
Table of Contents
There are various methods for calling shell commands in Ruby. Most of them either not wait at all for the results, or wait until the command execution is finished.
In many cases it is ok, because programmers want shell command results for further processing. Unfortunately this means that while a shell command runs, there's no way to get partial results and process them (multitasking FTW). It also means that all the results have to be buffered. It might be (for a long running intensive commands) a source of memory leaks in your applications.
Luckily there's a great way to process shell command data in a stream (row after row).
The task
Lets assume that we want to find first 10 files in our file system that match a given pattern (note that it could be achieved way better with just shell commands but it's not the point here).
The bad way
Here's a typical code to achieve that (and believe me - I've encountered solutions like that in production systems):
require 'memory_profiler'
report = MemoryProfiler.report do
pattern = /test/
results = `find / 2> /dev/null`.split("\n")
selection = results.select { |file| file =~ pattern }
selection[0..10]
end
report.pretty_print
This might seem elegant and it definitely works, but let's check Ruby's process memory usage:
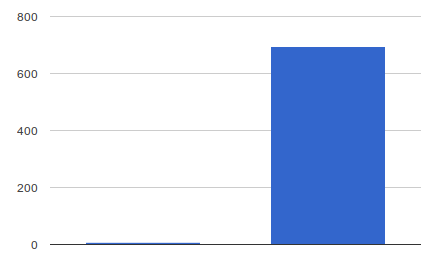
Memory usage in MB (before and after find)
Total allocated: 661999052 bytes (2925598 objects)
Total retained: 40 bytes (1 objects)
allocated memory by gem
-----------------------------------
661999052 other
allocated memory by class
-----------------------------------
632408588 String
26181752 Array
3408440 MatchData
232 Hash
40 Process::Status
We had to use nearly 700MB of memory and it took us 4.7 seconds just to find few matching files. The time wouldn't be that bad, but memory usage like this is a bit overkill. It is bad mostly because find / lists all the files and the more things we have, the bigger output we get. This also means that our code will behave differently dependent on what machine it will run. For some we might not have memory problems but for others it might grow over 1GB.
Now imagine what would happen if we would execute this code in 25 Sidekiq concurrent workers...
![]()
![]()
Of course with GC running we might not kill our machine, but memory spikes will look kinda weird and suspicious.
The good way - hello IO.popen
Instead of waiting for all the files from find / command, let's process each line separately. To do so, we can use the IO.popen method.
IO.popen runs the specified command as a subprocess; the subprocess’s standard input and output will be connected to the returned IO object. (source)
It means that we can execute find command and feed our main process with every line of the output separately.
Note: IO.popen executed without a block will not wait for the subprocess to finish!
require 'memory_profiler'
report = MemoryProfiler.report do
pattern = /test/
selection = []
IO.popen('find / 2> /dev/null') do |io|
while (line = io.gets) do
# Note - here you could use break to get out and sigpipe
# subprocess to finish it early. It will however mean that your subprocess
# will stop running early and you need to test if it will stop without
# causing any trouble
next if selection.size > 10
selection << line if line =~ pattern
end
end
selection[0..10]
end
report.pretty_print
Results:
Total allocated: 362723119 bytes (2564923 objects)
Total retained: 394 bytes (3 objects)
allocated memory by gem
-----------------------------------
362723119 other
allocated memory by class
-----------------------------------
362713215 String
8432 IO
1120 MatchData
232 Hash
80 Array
40 Process::Status
45% less memory required.
The best way (for some cases)
There's also one more way to do the same with the same #popen but in a slightly different style. If you:
- Don't need to process all the lines from the executed command
- Can terminate subprocess early
- Are aware of how to manage subprocesses
you can then stream data into Ruby as long as you need and terminate once you're done. Than way Ruby won't fetch new lines and won't have to GC them later on.
require 'memory_profiler'
report = MemoryProfiler.report do
pattern = /test/
selection = []
run = true
io = IO.popen('find / 2> /dev/null')
while (run && line = io.gets) do
if selection.size > 10
Process.kill('TERM', io.pid)
io.close
run = false
end
selection << line if line =~ pattern
end
selection
end
report.pretty_print
Since we don't wait for the subprocess to finish, it definitely will be faster but what about memory consumption?
Total allocated: 509989 bytes (5613 objects)
Total retained: 448 bytes (4 objects)
allocated memory by gem
-----------------------------------
509989 other
allocated memory by class
-----------------------------------
499965 String
8432 IO
1120 MatchData
232 Hash
200 Array
40 Process::Status
99% less than the original solution!
Note: This solution is not always applicable.
Summary
The way you execute shell commands really depends on few factors:
- Do you need an output results at all?
- Do you need all the lines from the output at the same time?
- Can you do other stuff and return once the data is ready?
- Can you process partial data?
- Can you terminate subprocess early?
When you go with your code out of Ruby scope and when you execute shell commands, it is always good to ask yourself those questions. Sometimes achieving stream processing ability can be done only when the system is being built, so it is really good to think about that before the implementation. In general I would recommend to always consider streaming in every place where we cannot exactly estimate the external command result size. That way you won't be surprised when there will be a lot more data that initially anticipated.
Note: Attentive readers will notice, that I didn't benchmark memory used in the subprocess. That is true, however it was irrelevant to our case as the shell command for all the cases was exactly the same.
Cover photo by: heiwa4126 on Creative Commons license.
January 4, 2017 — 10:33
Can we just `break` instead of `next` in the second solution?
I think the called process will simply get SIGPIPE in that case and exit.
January 4, 2017 — 11:33
You’re absolutely right and not at the same time. I didn’t want to sigpipe as it would terminate the process. Reading through whole dataset ensures, that we wait until process finishes it’s execution. It might be a concern in case of some processes so I followed a “safe” route with this example. I’ve added a note. Thank you.
January 4, 2017 — 12:07
Right point. Then instead of SIGTERMing the process we can just exit the loop and let the child process get SIGPIPE :-)
January 4, 2017 — 12:34
Yes I know but then the example that was supposed to be simple (you can replace TERM with PIPE) would get a bit of Ruby “magic” that not necessary would be understandable for folks without reading through some details on how that works.