Introduction
Imagine pausing a problematic partition, skipping a corrupted message, and resuming processing - all within 60 seconds, without deployments or restarts. This is now a reality with Karafka 2.5 and Web UI 0.11.
This release fundamentally changes how you operate Kafka applications. It introduces live consumer management, which transforms incident response from a deployment-heavy process into direct, real-time control.
I'm excited to share these capabilities with the Karafka community, whose feedback and support have driven these innovations forward.
Sponsorship and Community Support
The progress of the Karafka ecosystem has been significantly powered by a collaborative effort, a blend of community contributions, and financial sponsorships. I want to extend my deepest gratitude to all our supporters. Your contributions, whether through code or funding, make this project possible. Thank you for your continued trust and commitment to making Karafka a success. It would not be what it is without you!
Notable Enhancements and New Features
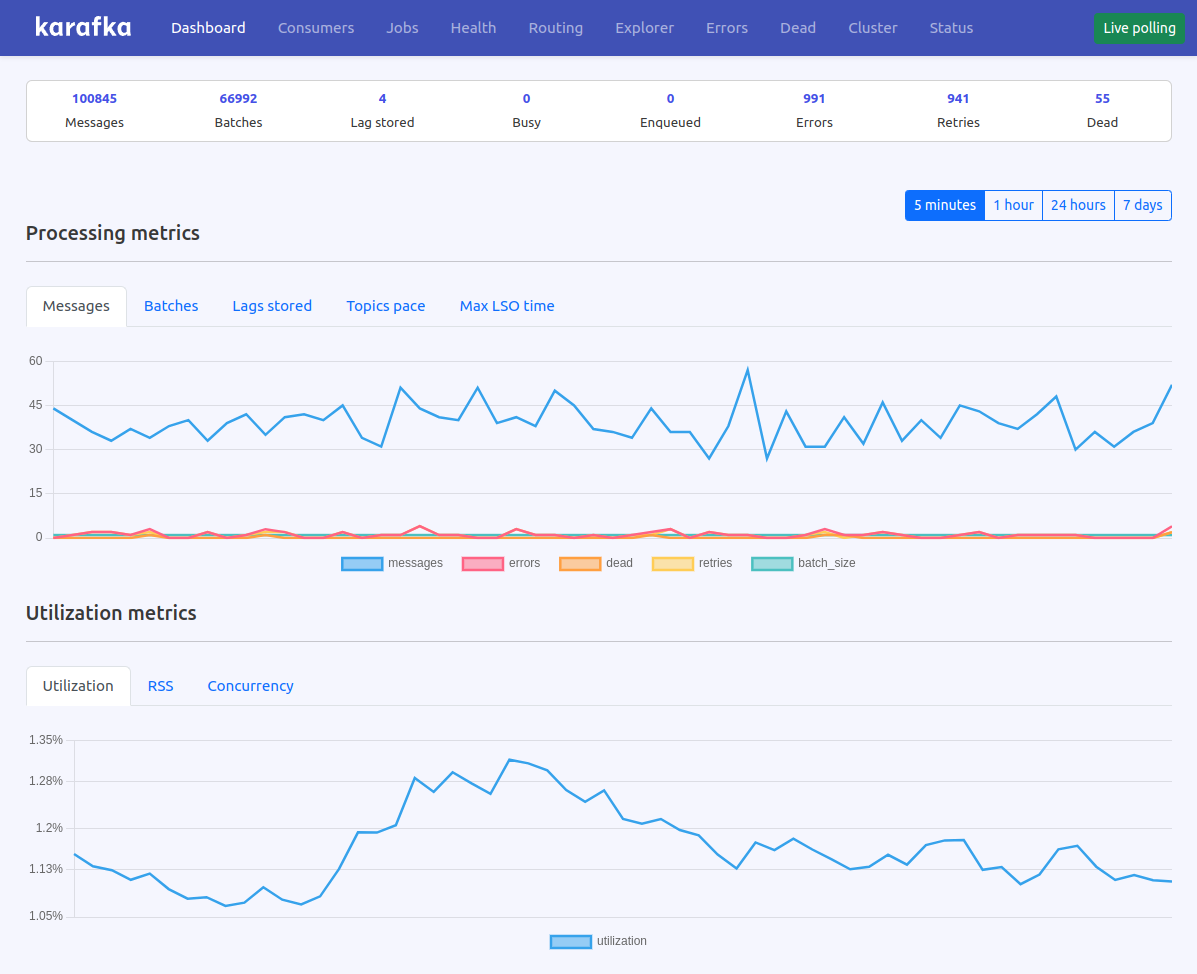
Below you can find detailed coverage of the major enhancements, from live consumer management capabilities to advanced performance optimizations that can improve resource utilization by up to 50%. For a complete list of all changes, improvements, and technical details, please visit the changelog page.
Live Consumer Management: A New Operational Model
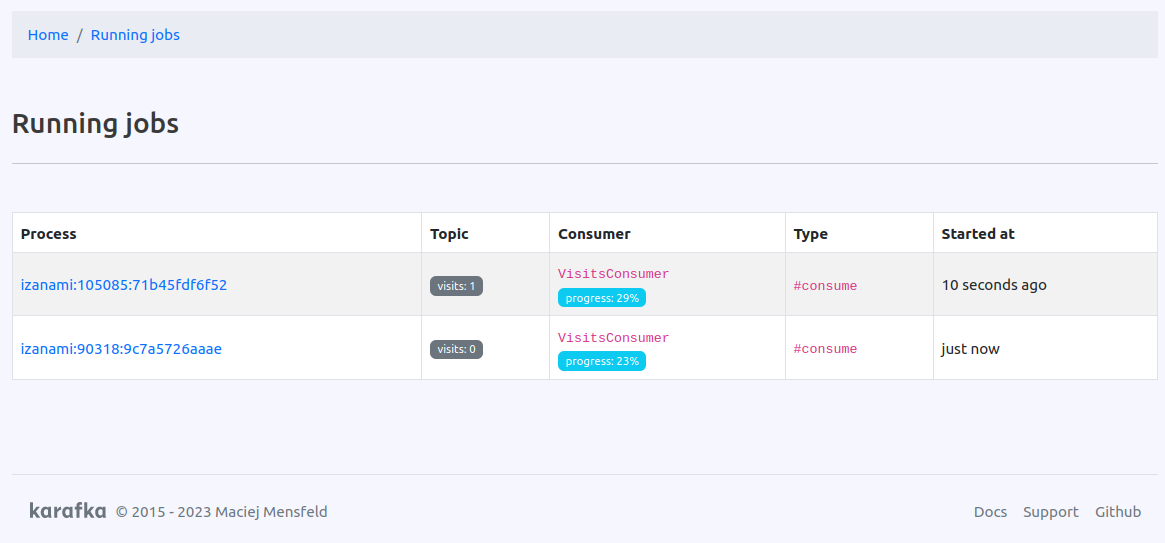
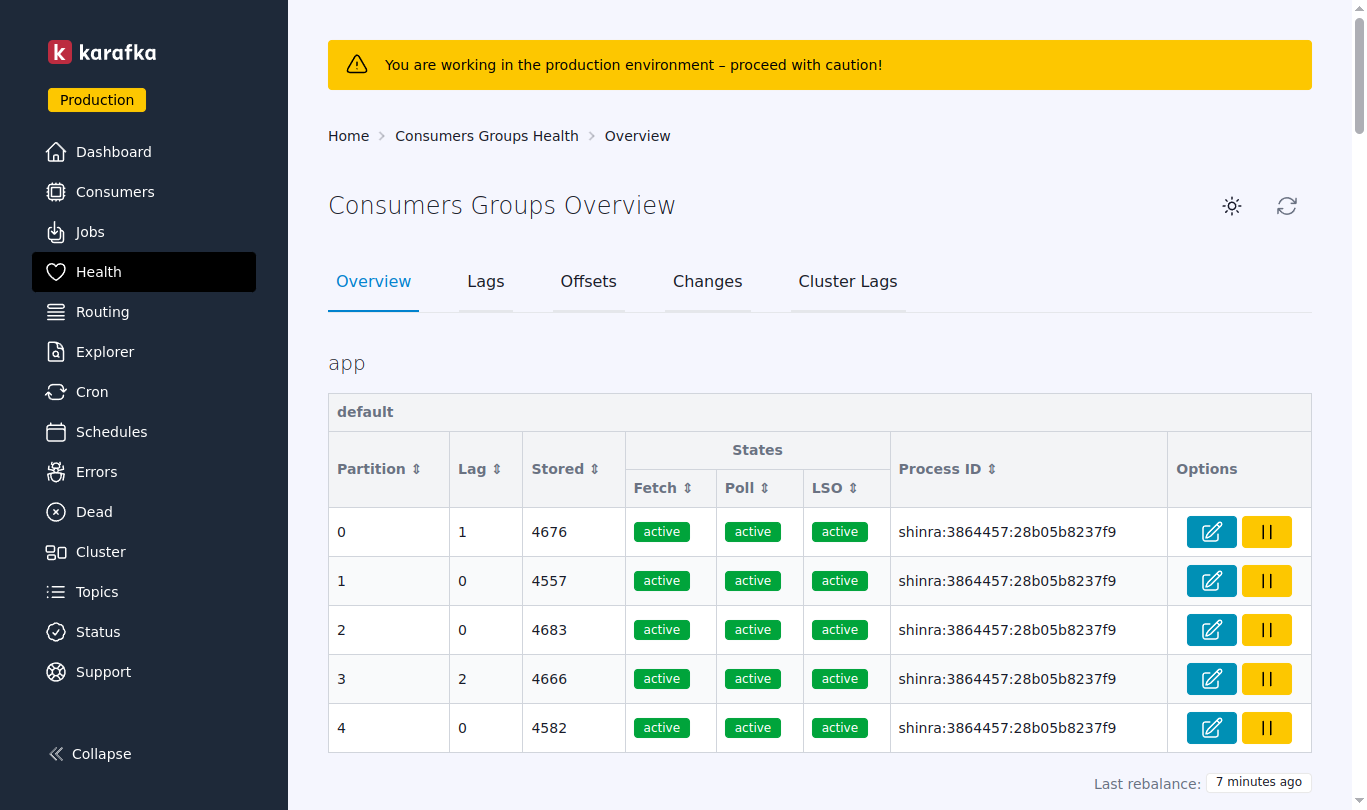
This update introduces live consumer management capabilities that change how you operate Karafka applications. You can now pause partitions, adjust offsets, manage topics, and control consumer processes in real time through the web interface.
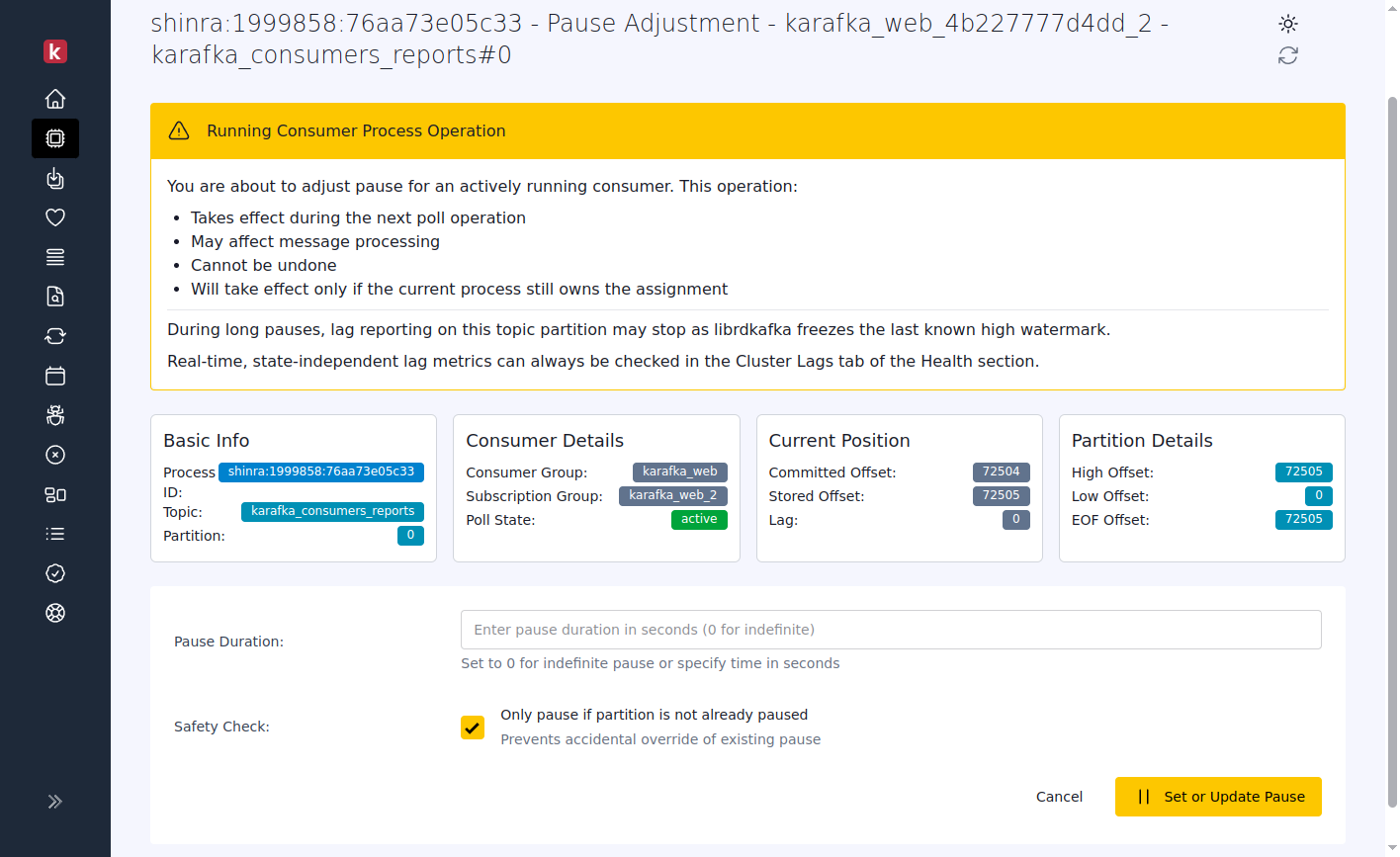
Note: While the pause and resume functionality provides immediate operational control, these controls are session-based and will reset during consumer rebalances caused by group membership changes or restarts. I am developing persistent pause capabilities that survive rebalances, though this feature is still several development cycles away. The current implementation remains highly valuable for incident response, temporary load management, and real-time debugging where quick action is needed within typical rebalance intervals.
Why This Matters
Traditional Kafka operations often require:
- Deploying code changes to skip problematic messages
- Restarting entire applications to reset consumer positions
- Manual command-line interventions during incidents
- Complex deployment coordination
This release provides an alternative approach. You now have more control over your Karafka infrastructure, which can significantly reduce incident response times.
Consider these operational scenarios:
-
Incident Response: A corrupted message is causing consumer crashes. You can pause the affected partition, adjust the offset to skip the problematic message, and resume processing - typically completed in under a minute.
-
Data Replay: After fixing a bug in your processing logic, you need to reprocess recent messages. You can navigate to a specific timestamp in the Web UI and adjust the consumer position directly.
-
Load Management: Your downstream database is experiencing a high load. You can selectively pause non-critical partitions to reduce load while keeping essential data flowing.
-
Production Debugging: A consumer appears stuck. You can trace the running process to see what threads are doing and identify bottlenecks before taking action.
This level of operational control transforms Karafka from a "deploy and monitor" system into a directly manageable platform where you maintain control during challenging situations.
Partition-Level Control
The Web UI now provides granular partition management with surgical precision over message processing:
-
Real-Time Pause/Resume: This capability addresses the rigidity of traditional consumer group management. You can temporarily halt the processing of specific data streams during maintenance, throttle consumption from high-volume partitions, or coordinate processing across multiple systems.
-
Live Offset Management: The ability to adjust consumer positions in real-time eliminates the traditional cycle of "stop consumer → calculate offsets → update code → deploy → restart" that could take time.
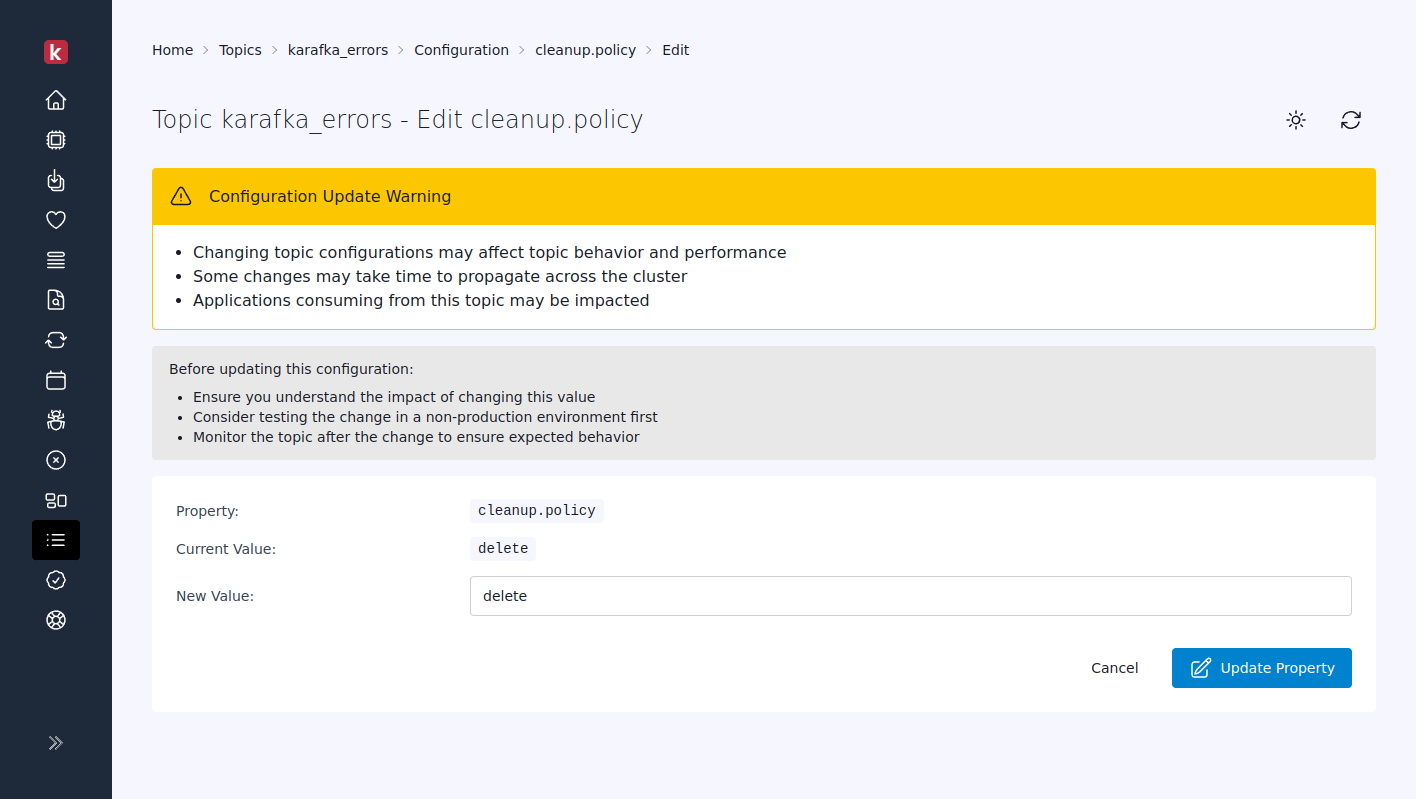
Complete Topic Lifecycle Management
Pro Web UI 0.11 introduces comprehensive topic administration capabilities that transform how you can manage your Kafka infrastructure. The interface now supports complete topic creation with custom partition counts and replication factors, while topic deletion includes impact assessment and confirmation workflows to prevent accidental removal of critical topics.
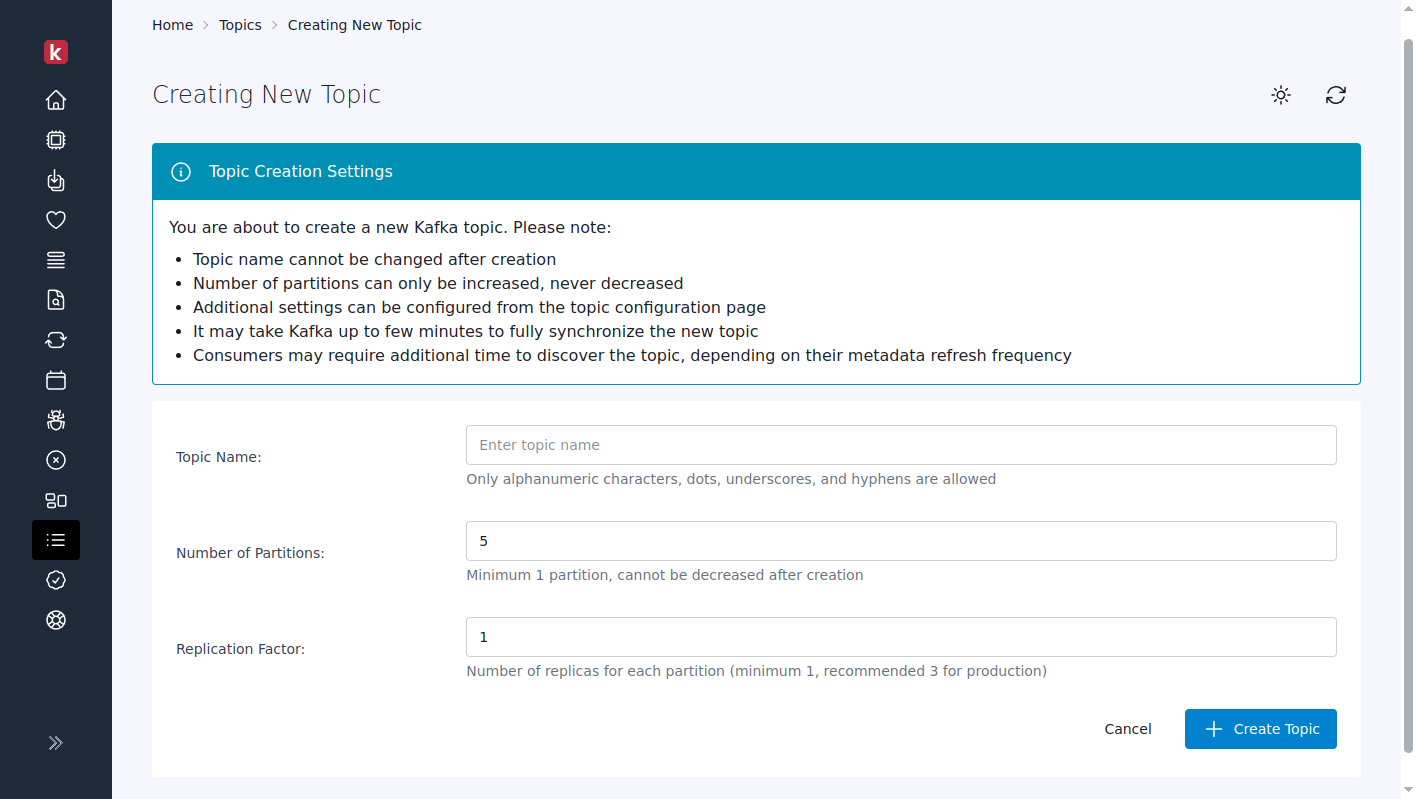
The live configuration management system lets you view and modify all topic settings, including retention policies, cleanup strategies, and compression settings. Dynamic partition scaling enables you to increase partition counts to scale throughput.
This approach unifies Kafka administration in a single interface, eliminating the need to context-switch between multiple tools and command-line interfaces.
UI Customization and Branding
When managing multiple Karafka environments, visual distinction becomes critical for preventing costly mistakes. Web UI 0.11 introduces customization capabilities that allow you to brand different environments distinctively - think red borders for production, blue gradients for staging, or custom logos for other teams. Beyond safety, these features enable organizations to seamlessly integrate Karafka's Web UI into their existing design systems and operational workflows.
Karafka::Web.setup do |config|
# Custom CSS for environment-specific styling
config.ui.custom_css = '.dashboard { background: linear-gradient(45deg, #1e3c72, #2a5298); }'
# Custom JavaScript for enhanced functionality
config.ui.custom_js = 'document.addEventListener("DOMContentLoaded", () => {
console.log("Production environment detected");
});'
endThe UI automatically adds controller and action-specific CSS classes for targeted styling:
/* Style only the dashboard */
body.controller-dashboard {
background-color: #f8f9fa;
}
/* Highlight error pages */
body.controller-errors {
border-top: 5px solid #dc3545;
}
Enhanced OSS Monitoring Capabilities
Web UI 0.11 promotes two monitoring features from Pro to the open source version: consumer lag statistics charts and consumer RSS memory statistics charts. These visual monitoring tools now provide all users with essential insights into consumer performance and resource utilization.
This change reflects my core principle: the more successful Karafka Pro becomes, the more I can give back to the OSS version. Your Pro subscriptions directly fund the research and development that benefits the entire ecosystem.
Open-source software drives innovation, and I'm committed to contributing meaningfully. By making advanced monitoring capabilities freely available, I ensure that teams of all sizes can access the tools needed to build robust Kafka applications. Pro users get cutting-edge features and support, while the broader community gains battle-tested tools for their production environments.
Performance and Reliability Improvements
While Web UI 0.11 delivers management capabilities, Karafka 2.5 focuses equally on performance optimization and advanced processing strategies. This version includes throughput improvements, enhanced error-handling mechanisms, and reliability enhancements.
Balanced Virtual Partitions Distribution
The new balanced distribution strategy for Virtual Partitions is a significant improvement, delivering up to 50% better resource utilization in high-throughput scenarios.
The Challenge:
Until now, Virtual Partitions have used consistent distribution, where messages with the same partitioner result go to the same virtual partition consumer. While predictable, this led to resource underutilization when certain keys contain significantly more messages than others, leaving worker threads idle while others were overloaded.
The Solution:
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
virtual_partitions(
partitioner: ->(message) { message.headers['order_id'] },
# New balanced distribution for optimal resource utilization
distribution: :balanced
)
end
endThe balanced strategy dynamically distributes workloads by:
- Grouping messages by partition key
- Sorting key groups by size (largest first)
- Assigning each group to the worker with the least current workload
- Preserving message order within each key group
When to Use Each Strategy:
Use :consistent when:
- Processing requires stable assignment across batches
- Implementing window-based aggregations spanning multiple polls
- Keys have relatively similar message counts
- Predictable routing is more important than utilization
Use :balanced when:
- Processing is stateless, or state is managed externally
- Maximizing worker thread utilization is a priority
- Message keys have highly variable message counts
- Optimizing throughput with uneven workloads
The performance gains are most significant with IO-bound processing, highly variable key distributions, and when keys outnumber available worker threads.
Advanced Error Handling: Dynamic DLQ Strategies
Karafka 2.5 Pro introduces context-aware DLQ strategies with multiple target topics:
class DynamicDlqStrategy
def call(errors_tracker, attempt)
if errors_tracker.last.is_a?(DatabaseError)
[:dispatch, 'dlq_database_errors']
elsif errors_tracker.last.is_a?(ValidationError)
[:dispatch, 'dlq_validation_errors']
elsif attempt > 5
[:dispatch, 'dlq_persistent_failures']
else
[:retry]
end
end
end
class KarafkaApp < Karafka::App
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
dead_letter_queue(
topic: :strategy,
strategy: DynamicDlqStrategy.new
)
end
end
endThis enables:
- Error-type-specific handling pipelines
- Escalation strategies based on retry attempts
- Separation of transient vs permanent failures
- Specialized recovery workflows
Enhanced Error Tracking
The errors tracker now includes a distributed correlation trace_id that gets added to both DLQ dispatched messages and errors reported by the Web UI, making it easier to track and correlate error occurrences with their DLQ dispatches.
Worker Thread Priority Control
Karafka 2.5 introduces configurable worker thread priority with intelligent defaults:
# Workers now run at priority -1 (50ms) by default for better system responsiveness
# This can be customized based on your system requirements
config.worker_thread_priority = -2This prevents worker threads from monopolizing system resources, leading to more responsive overall system behavior under high load.
FIPS Compliance and Security
All internal cryptographic operations now use SHA256 instead of MD5, ensuring FIPS compliance with enterprise security requirements.
Coming Soon: Parallel Segments
Karafka 2.5 Pro also introduces Parallel Segments, a new feature for concurrent processing within the same partition when there are more processes than partitions. As we finalize the documentation, this capability will be covered in a dedicated blog post.
Migration Notes
Karafka 2.5 and its related components introduce a few minor breaking changes necessary to advance the ecosystem. No changes would disrupt routing or consumer group configuration. Detailed information and guidance can be found on the Karafka Upgrades 2.5 documentation page.
Migrating to Karafka 2.5 should be manageable. I have made every effort to ensure that breaking changes are justified and well-documented, minimizing potential disruptions.
Conclusion
Karafka 2.5 and Web UI 0.11 mark another step in the framework's evolution, continuing to address real-world operational needs and performance challenges in Kafka environments.
I thank the Karafka community for their ongoing feedback, contributions, and support. Your input drives the framework's continued development and improvements.
The complete changelog and upgrade instructions are available in the Karafka documentation.