Table of Contents
Introduction
I'm happy to announce that Karafka 2.3 and its Web UI 0.8 have just been released.
For those who wonder what Karafka is, Karafka is a Ruby and Rails multi-threaded efficient Kafka processing framework.
The Karafka 2.3 release builds upon the foundation set by its predecessor, 2.2, making it a seamless continuation rather than a major rewrite. This means upgrading from version 2.2 to 2.3 can be done without extensive work or significant modifications to the existing codebases.
These releases introduce many new features. Please note that I have described only the most significant changes and improvements to the ecosystem below.
Note: There are no extensive upgrade notes; you only need to follow those guidelines.
Karafka Noticeable Features And Improvements
Karafka 2.3 marks a significant step in the framework's evolution, driven by the community's valuable input and the collective need for a robust Kafka processing solution.
With each bigger update, the OSS and Pro versions of Karafka receive refinements, ensuring every user benefits from a more streamlined, robust, and adaptable framework.
Transactions And Exactly-Once Semantics
Transactions in Karafka provide a mechanism to ensure that a sequence of actions is treated as a single atomic unit. In the context of distributed systems and message processing, a transaction ensures that a series of produce and consume operations are either all successfully executed or none are, maintaining data integrity even in the face of system failures or crashes.
Starting with this release, Karafka supports Kafka's Exactly-Once Semantics, the gold standard for message processing systems. It ensures that each message is processed exactly once, eliminating data duplication or loss risks. In simpler terms, despite failures, retries, or other anomalies, each message will affect the system state only once.
class EventsConsumer < ApplicationConsumer
def consume
# Make sure, that messages are produced only together with marking as consumed
transaction do
sum = 0
messages.each do |message|
sum += message.payload[:count]
end
produce_async(topic: :sums, payload: sum.to_s)
mark_as_consumed(messages.last)
end
end
endAny exception or error raised within a transaction block will automatically result in the transaction being aborted. This ensures that if there are unexpected behaviors or issues during message production or processing, the entire batch of messages within that transaction won't be committed, preserving data consistency.
Dead Letter Queue Independent Recovery Mode
In standard operations, Karafka, while processing messages, does not make assumptions about the processing strategy employed by the user. Whether it’s individual message processing or batch operations, Karafka remains agnostic. This neutrality in the processing strategy becomes particularly relevant during the DLQ recovery phases.
Under normal circumstances, Karafka treats a batch of messages as a collective unit during DLQ recovery. This collective approach might not align with specific use cases with independent message processing. In such cases, the failure of one message does not necessarily imply a problem with the entire batch.
Karafka's DLQ independent flag introduces a nuanced approach to DLQ recovery, treating each message as an entity with its error counter.
To enable it, add independent: true to your DLQ topic definition:
class KarafkaApp < Karafka::App
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
dead_letter_queue(
topic: 'dead_messages',
max_retries: 3,
independent: true
)
end
end
endThe following diagrams compare DLQ flows in Karafka: the first without the independent flag and the second with it enabled, demonstrating the operational differences between these two settings.

*The diagram shows DLQ retry behavior without the independent flag: each error in a batch adds to the error counter until the DLQ dispatch takes place on the last erroneous message.

*The diagram shows DLQ retry behavior with the independent flag active: the error counter resets after each message is successfully processed, avoiding DLQ dispatch if all messages recover.
Connection Multiplexing And Dynamic Scaling
Karafka 2.3 introduces enhanced multiplexing, allowing multiple connections per topic for parallel processing and increased throughput. Additionally, it introduces Dynamic Multiplexing, which optimizes resource utilization by automatically adjusting the number of connections based on partition assignments. This ensures balanced and efficient resource distribution, enhances system scalability, and maintains high performance despite fluctuating data volumes.
With this mode enabled, Karafka can automatically start and stop additional Kafka connections during runtime based on the topics and partition distribution.
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
# Establish at most three connections and shut down two if not needed. Start with 2.
subscription_group 'events' do
multiplexing(min: 1, max: 3, boot: 2)
topic :events do
consumer EventsConsumer
end
end
end
endMultiplexing increases throughput and significantly enhances processing capabilities in scenarios with multi-partition lags. When a single process subscribes to multiple partitions, it can swiftly address lags in any of them, ensuring more consistent performance across your system. This advantage becomes particularly prominent in IO-intensive workloads where efficient data handling and processing are crucial.
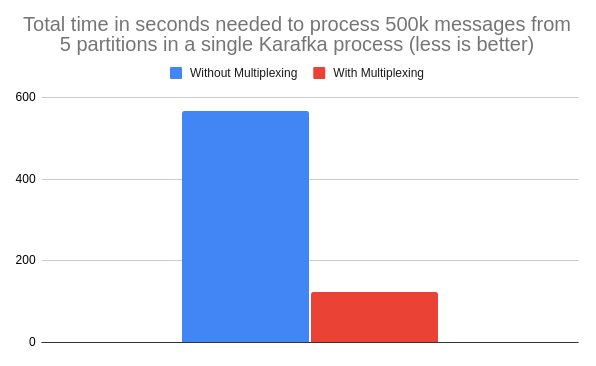
*This example illustrates the performance difference for IO intense work, where the IO cost of processing a single message is 1ms and a total lag of 500 000 messages in five partitions.
Access Control Lists (ACLs) Admin Support
Apache Kafka ACLs (Access Control Lists) provide a robust mechanism to control permissions and access rights for Kafka resources. They are crucial for ensuring data security, managing consumer and producer interactions, and maintaining overall cluster integrity. Karafka extends these capabilities with a simplified, Ruby-friendly API:
acl = Karafka::Admin::Acl.new(
resource_type: :topic,
resource_name: 'my_topic',
resource_pattern_type: :literal,
principal: 'user:Bob',
host: '*',
operation: :write,
permission_type: :allow
)
Karafka::Admin::Acl.create(acl)Periodic Jobs
Periodic Jobs were designed to allow consumers to perform operations at regular intervals, even without new data. This capability is particularly useful for applications that require consistent action, such as window-based operations or maintaining system readiness.
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
topic :events do
consumer Consumer
# Tick at most once every five seconds
periodic true
end
end
endclass Consumer < Karafka::BaseConsumer
def consume; end
def tick
puts "Look, mom, I'm periodic!"
end
endKarafka's Periodic Jobs handle tasks based on timing intervals and let you schedule specific tasks, like setting alarms or reminders. This means you can set up tasks that run regularly, just like cron jobs. This feature is great for organizing your work and ensuring everything runs smoothly and on time. In a later article, I'll talk more about how to use this for setting up scheduled tasks.
Offset Metadata Storage
Offset Metadata Storage allows adding metadata to offsets. At its core, it enables developers to attach custom metadata to message offsets when committed to the Kafka broker. This metadata, essentially a form of annotation or additional data, can be retrieved and used for many purposes, enhancing message processing systems' capability, traceability, and intelligence.
In traditional Kafka consumption, a message's offset indicates its position within a partition. While this is crucial for ensuring messages are processed in order, and no message is missed or duplicated, the standard offset mechanism doesn't provide context or additional information about the processing state or the nature of the message. Offset Metadata Storage fills this gap by allowing developers to store custom, context-rich data alongside these offsets.
All you need to use is a second argument when you mark it as consumed:
def consume
messages.each do |message|
EventsStore.call(message)
@aggregator.mark(message)
mark_as_consumed(
message,
# Make sure that this argument is a string and in case of a JSON, do not
# forget to define a custom deserializer
{
process_id: Process.uid,
aggregated_state: @aggregator.to_h,
}.to_json
)
end
endAnd then, to retrieve the offset metadata, you can use the #offset_metadata method within your consumer. This method fetches the offset metadata and deserializes it using the configured deserializer.
def consume
# Use offset metadata only on the first run on the consumer
unless @recovered
@recovered = true
metadata = offset_metadata
# Do nothing if `#offset_metadata` was false. It means we have lost the assignment
return unless metadata
# Use the metadata from the previous process to recover the internal state
@aggregator.recover(
metadata.fetch('aggregated_state')
)
end
# Rest of the processing here...
endWeb UI Noticeable Features And Improvements
The latest Web UI 0.8 release enhances OSS and the paid Pro version. My goal was always clear: provide a strong OSS foundation that most users can rely on, allowing their projects to grow naturally before considering the jump to Pro. This approach ensures that everyone, regardless of their version, has access to a robust and efficient toolset from the get-go.
This update brings more than just Pro improvements; it significantly enriches the OSS experience. Thanks to the support from our Pro users, features that were once exclusive to Pro have transitioned to OSS. This move elevates the quality of the developer experience within the OSS ecosystem and reinforces the commitment to a user-friendly and inclusive Kafka ecosystem for all.
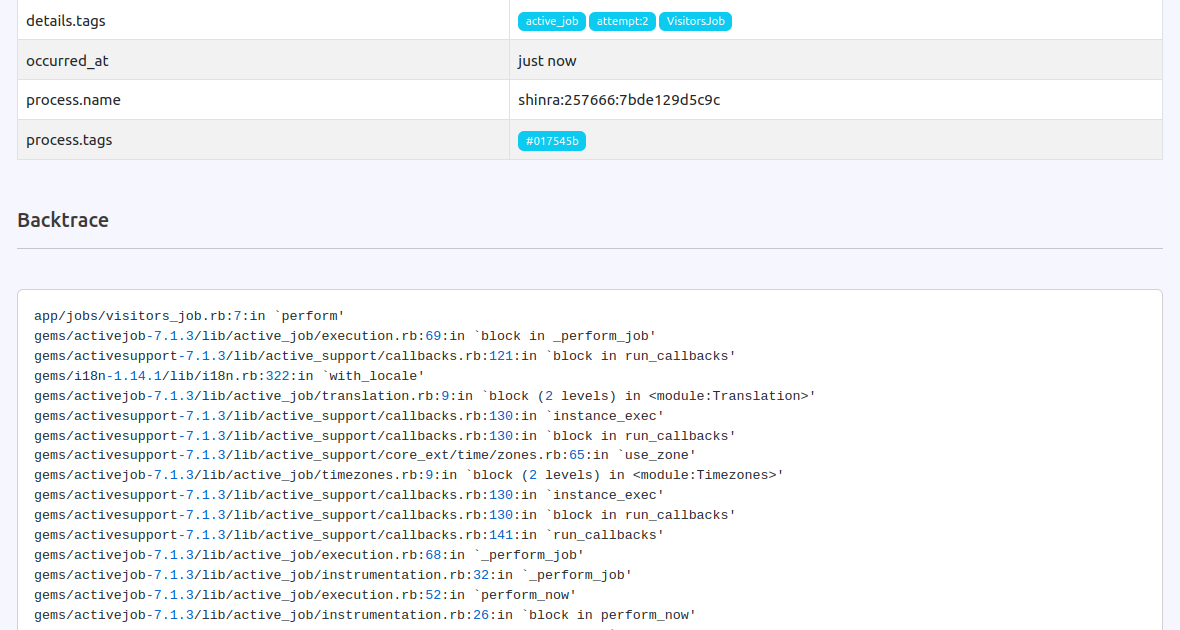
Full Errors Info Promoted to OSS
Full Error Backtrace visibility is now available in OSS.
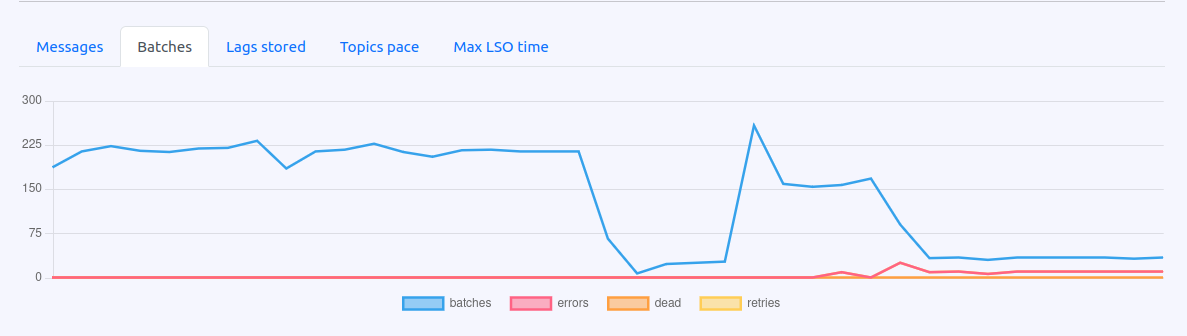
Various Graphs Promoted to OSS
Graphs such as Concurrency, Batches, and Utilization have been promoted to OSS.
Time Ranges Promoted to OSS
Data Exploration Time Ranges are now fully available in OSS.
Data Sorting
Data Sorting in Karafka Web UI is super helpful because it lets you quickly organize and find the info you need in tables full of different metrics. With all the data Karafka handles, sorting makes it much easier to spot the important stuff.
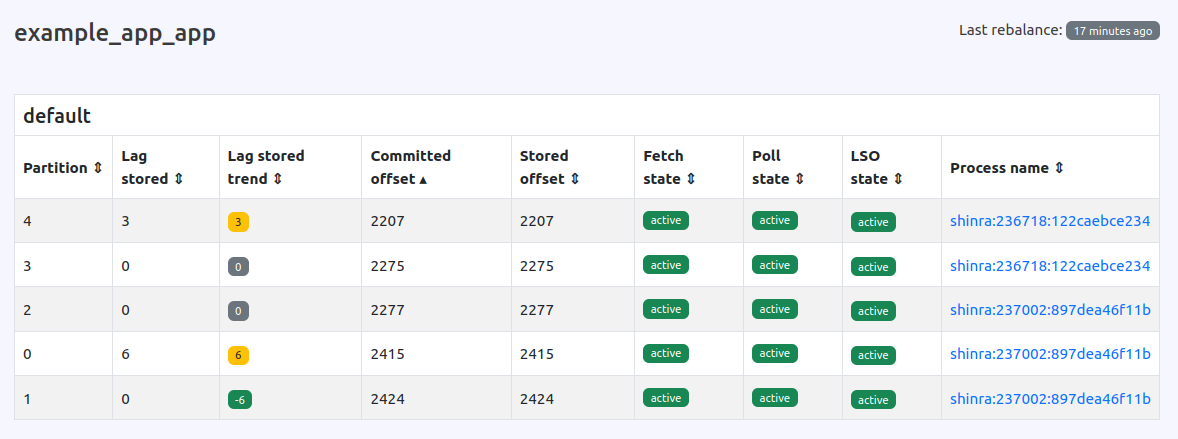
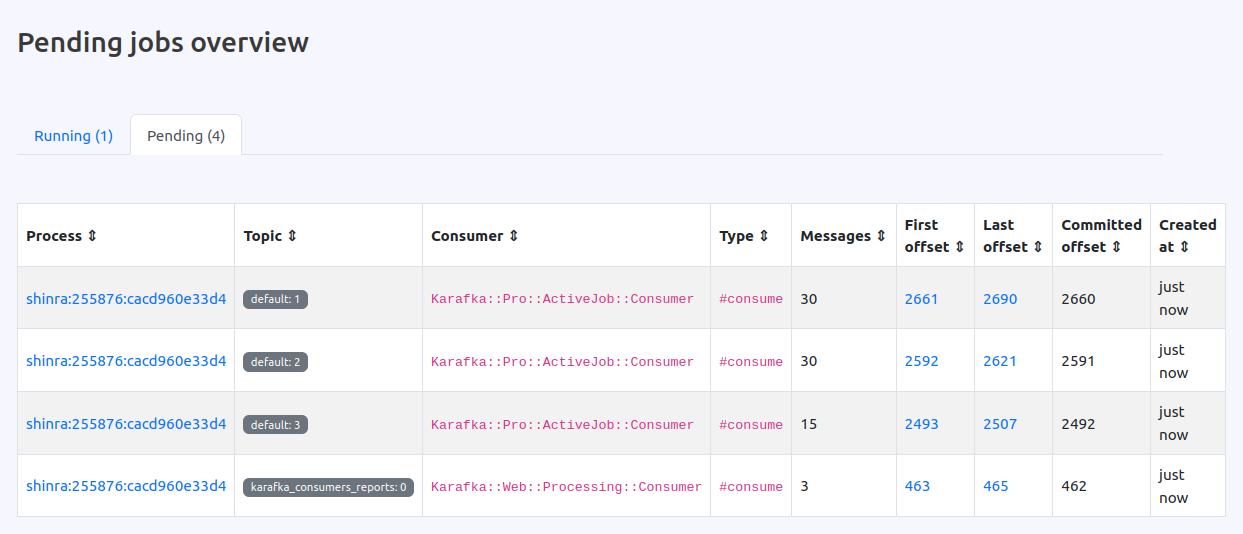
Pending Jobs Visibility
Pending Jobs visibility in Karafka Web UI is a feature that is particularly useful when working with advanced scheduling API that fine-tunes how jobs are managed within a process. This API can hold back job execution when needed, like when you want to balance your system's resources or prioritize tasks from specific topics.
Now, the Web UI lets you see all jobs waiting to run. This means you can easily track what's queued up, helping you understand how your jobs are organized and when they will likely be executed.
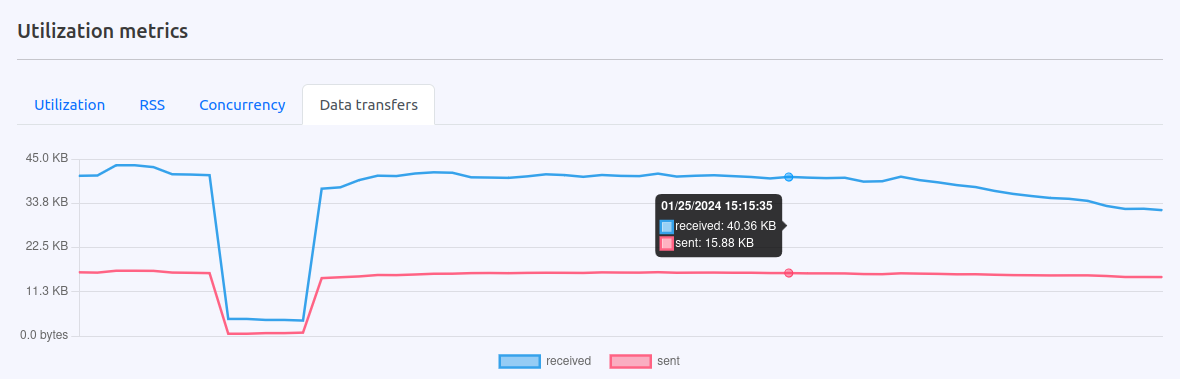
Data Transfers Visibility
Visibility of ingress and egress data in Karafka Web UI helps you monitor the data flow to and from Kafka. This feature is excellent for spotting how much data your system is dealing with and catching any unexpected data spikes. It's beneficial if you're with vendors who charge for data transfer, as it can help you manage costs better and quickly spot any issues that might lead to extra charges.
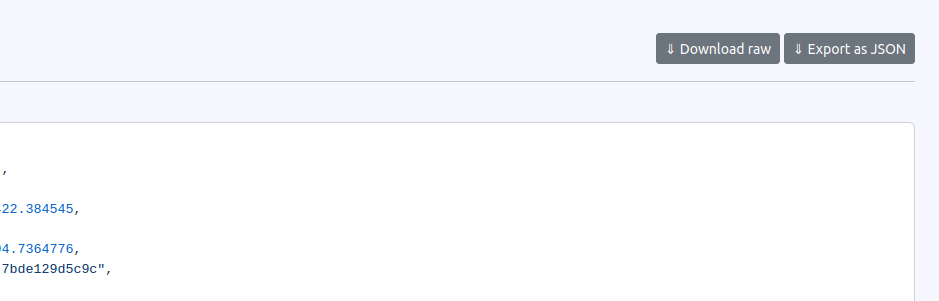
Raw Payloads and Deserialized Payloads Download
The Web UI now allows the download of Raw and Deserialized Payloads, giving you direct access to your message data in its original or processed form. This feature can be adjusted to fit your company's data access policies, ensuring that sensitive information remains secure while providing the necessary data transparency and accessibility for your team.
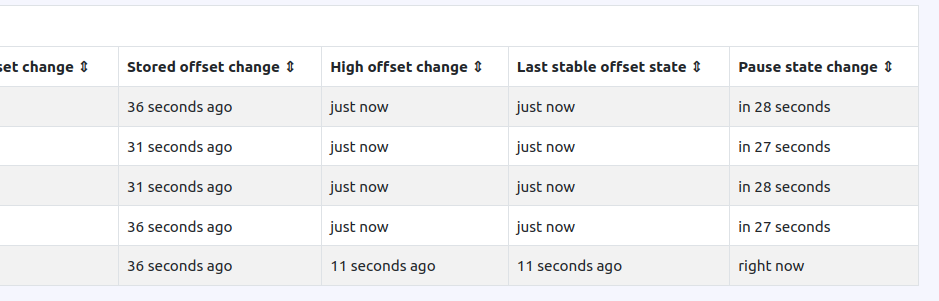
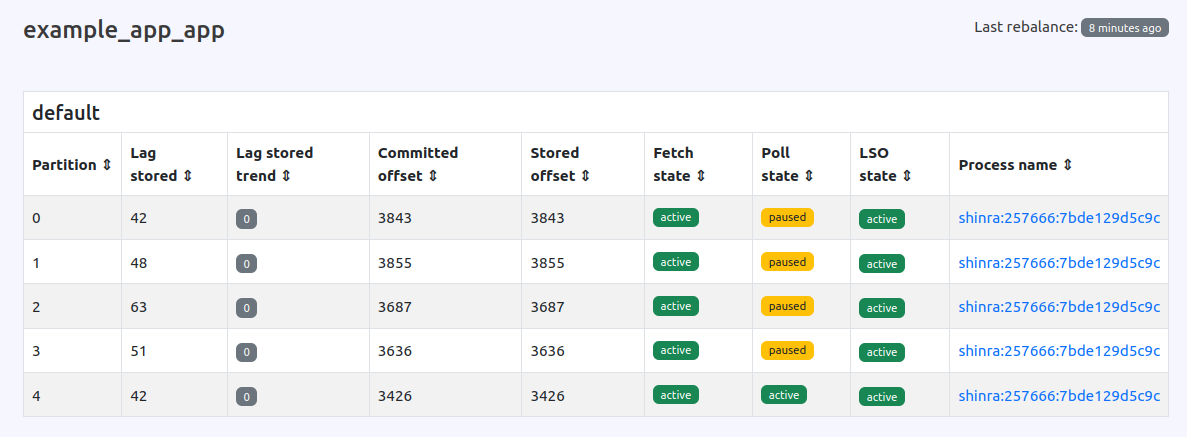
Pauses Tracking
Karafka UI has enhanced its visibility features, providing detailed information about paused partitions, including when their processing is expected to resume. This is particularly helpful if a pause is due to an error, as you can see when the partition is paused and when it's set to get back on track.
Upgrade Notes
No significant changes are needed. Just follow this Upgrade Doc.
Karafka Pro
Karafka Pro has many valuable, well-documented, well-tested functionalities that can significantly improve your day-to-day operations with Kafka in Ruby. It also introduces commercial support, as due to a sheer number of questions and requests, I do need to have a way to prioritize those.
Help me continue to build and maintain a high-quality Kafka ecosystem for Ruby and Ruby on Rails.
References
- Karafka Github
- Getting started with Karafka
- Github Karafka 2.3 Release Notes
- Karafka 2.3 Docs
- WaterDrop (producer) Docs
- Example Applications
- Karafka 2.3 Upgrade Notes
Stay tuned, and don't forget to join our Slack channel.