I'm thrilled to announce the new and shiny addition to the Karafka ecosystem: Karafka Web.
For those who wonder what Karafka is, Karafka is a Ruby and Rails multi-threaded efficient Kafka processing framework.
Karafka has always been a convenient framework, and I've abstracted or hidden many complexities related to working with Apache Kafka. However, the ecosystem needed one essential thing: a Web UI.
Until now, you would have to rely on external tooling to get visibility into your Karafka operations. While this is not problematic for big businesses, solid observability is difficult for anyone just starting their adventure with Karafka and Kafka.
Today I have the pleasure of presenting an effect of the last six months of my OSS work: Karafka Web. The Web UI provides a convenient way for developers to monitor and manage their Karafka-based applications without using the command line or third-party software. It does not require any additional database beyond Kafka itself.
"Hey, this looks like Sidekiq" you may say. And this is true! Mike was kind enough to allow me to utilize his well-curated and battle-tested dashboard design; honestly, I cannot thank him enough for that.
Features and capabilities
I've been working with Apache Kafka for over eight years, and I always wished we had a tool that could be easily mounted and used as a Rack application that would provide process-centric visibility. There are many excellent Web UIs for Apache Kafka, though most of them focus on Kafka. Karafka Web aims to provide another layer of visibility that is Karafka consumers-centric, allowing you to understand and debug your consumption operations.
# Mounting is simple as it can be
require 'karafka/web'
Rails.application.routes.draw do
# Your other routes...
mount Karafka::Web::App, at: '/karafka'
endBelow you can find the presentation of features I consider the most notable.
Note: You can find the whole list of features and capabilities described here.
Consumers monitoring and insights
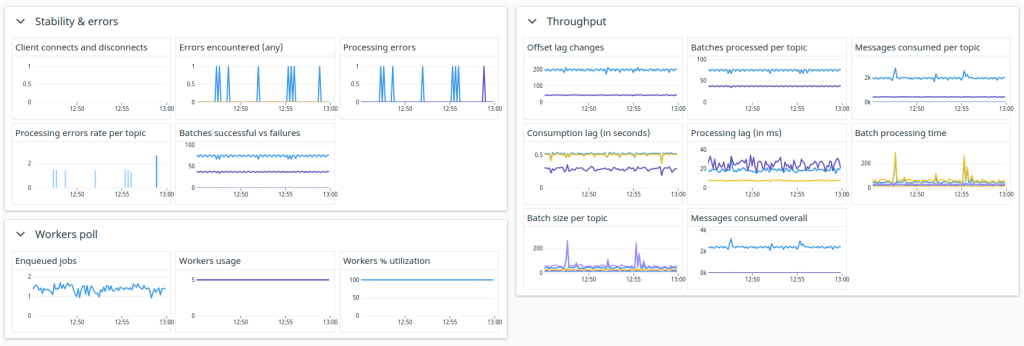
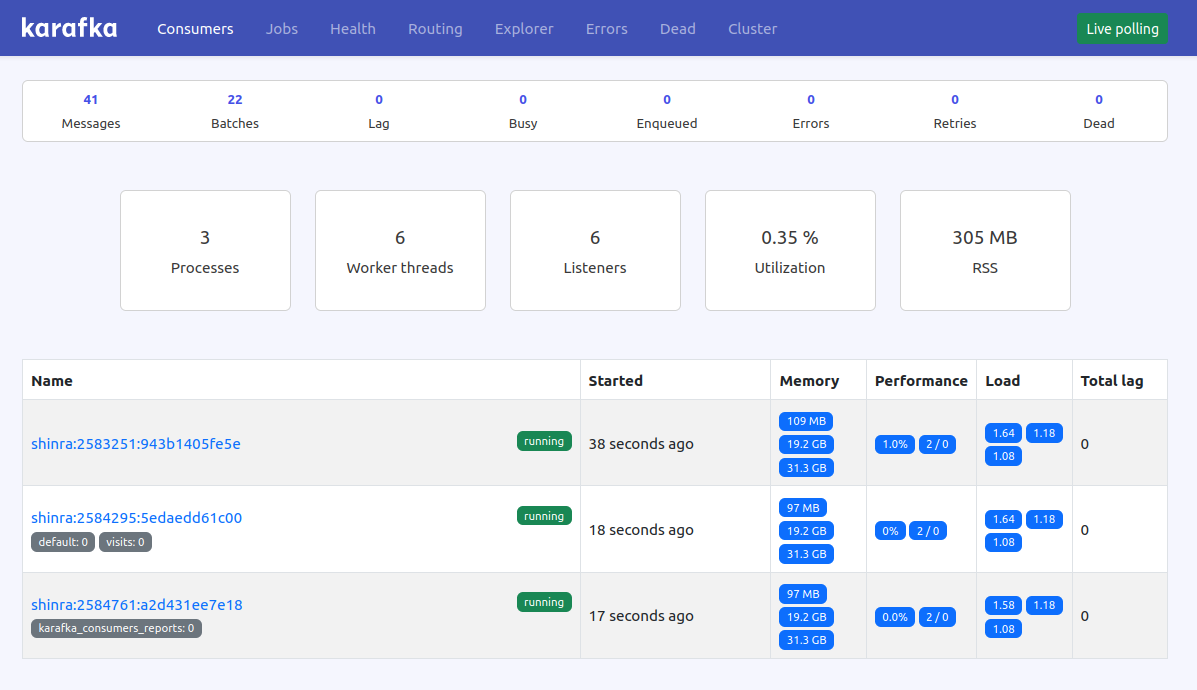
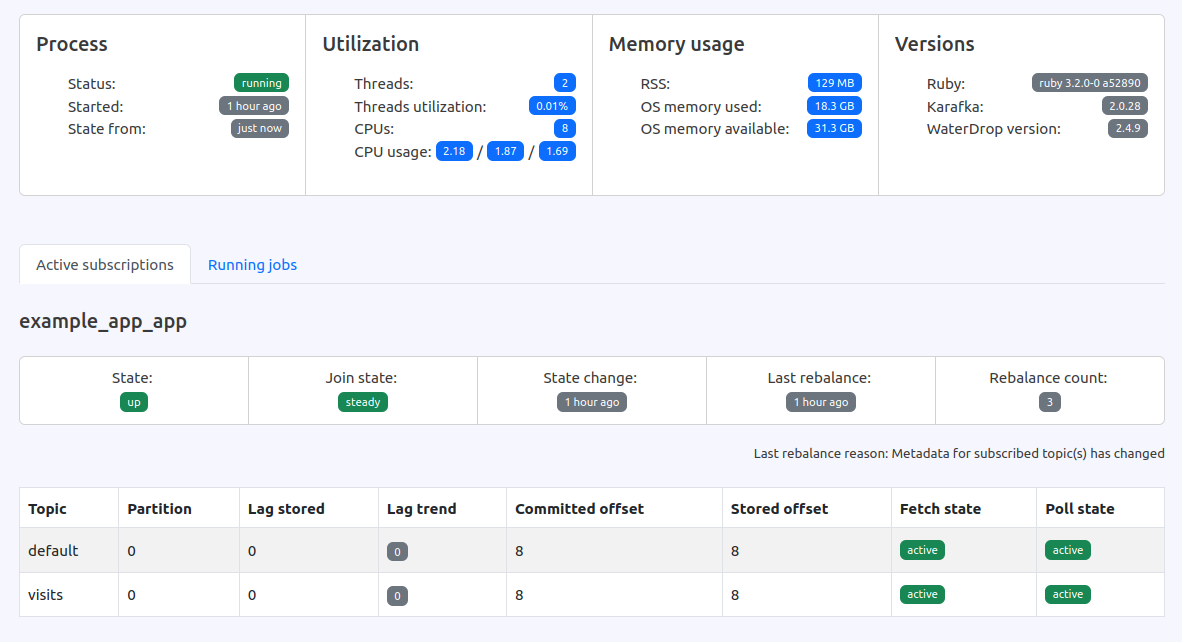
Each Karafka consumer periodically reports its status and metrics to a dedicated Kafka topic. This data is then used to compute aggregated metrics and provide visibility into the current operations of each consuming process.
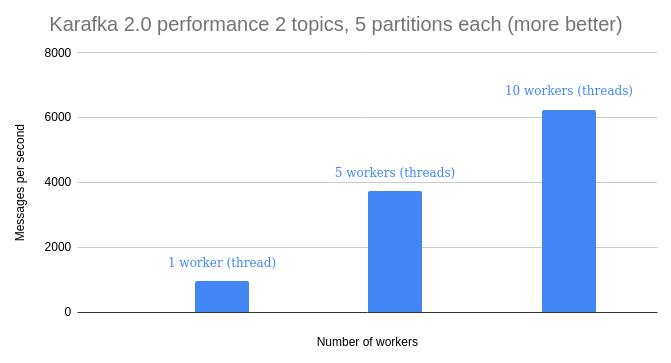
Consumers monitoring gives you a general overview and granular insights into each of the running processes. Ever wondered whether your processes are IO or CPU bound at a given time? Or how loaded are your processes? Now you can check it out with one click!
Data Explorer
Data explorer allows users to view and explore the data produced to Kafka. It understands the Karafka routing table and can deserialize data before it being displayed. It allows for quick investigation of both payload and header information.

Error tracking
Karafka consumers are multi-threaded. The consumption process happens independently from data polling. There is a lot of synchronization, and not all the errors propagate to the consumer threads. Karafka records all the errors, including the non-user-related ones, and presents them in the errors view.
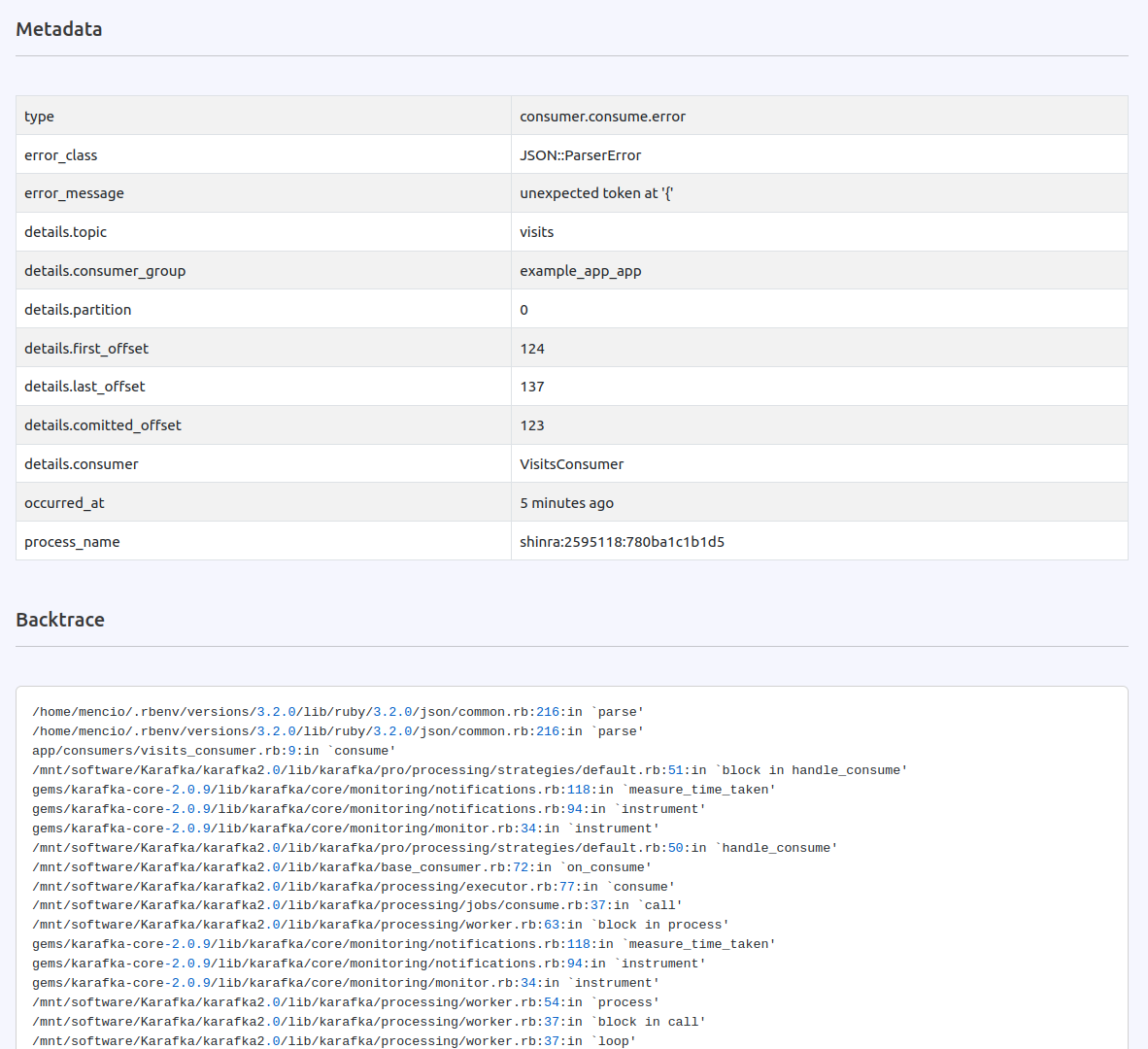
Getting Started
If you want to get started with Karafka and test the Web-UI as fast as possible, then the best idea is to visit our Web UI getting started guides and the example Rails app repository.
The example Rails repository already contains the Web UI and detailed instructions on how to run it.
Support
Building and maintaining a complex OSS framework takes a lot of resources. That's why I also sell Karafka Pro subscriptions. It includes a commercial-friendly license, priority support, architecture consultations, enhanced Web UI and high throughput data processing-related features (virtual partitions, long-running jobs, and more).
Help me provide high-quality open-source software. If your business rely on Karafka, please consider supporting me. See the Karafka homepage for more details.
Future plans
My primary Web UI-related efforts revolve around providing trend graphs for better health assessment and visibility to diagnose potential lagging and clogging issues quickly.
TL;DR
No UI: bad.
Out-of-the-box OSS Karafka Web UI: great.
No third party dependencies, minimal supply chain fingerprint, works out-of-the-box.