I'm happy to announce that Karafka 2.1 has just been released.
For those who wonder what Karafka is, Karafka is a Ruby and Rails multi-threaded efficient Kafka processing framework.
The Karafka 2.1 release builds upon the foundation set by its predecessor, 2.0, making it a seamless continuation rather than a major rewrite. This means that upgrading from version 2.0 to 2.1 can be done without extensive work or significant modifications to existing codebases. With Karafka 2.1, you can expect improved features and enhancements while maintaining the stability and compatibility you have come to rely on.
Note: There are no extensive upgrade notes, and you only need to follow those guidelines.
Noticeable features and improvements
Virtual Offset Management for Virtual Partitions
Virtual Partitions allow you to parallelize the processing of data from a single partition. This can drastically increase throughput when IO operations are involved.
While the default scaling strategy for Kafka consumers is to increase partitions count and number of consumers, in many cases, this will not provide you with desired effects. In the end, you cannot go with this strategy beyond assigning one process per single topic partition. That means that without a way to parallelize the work further, IO may become your biggest bottleneck.
Virtual Partitions solve this problem by providing you with the means to further parallelize work by creating "virtual" partitions that will operate independently but will, as a collective processing unit, obey all the Kafka warranties.

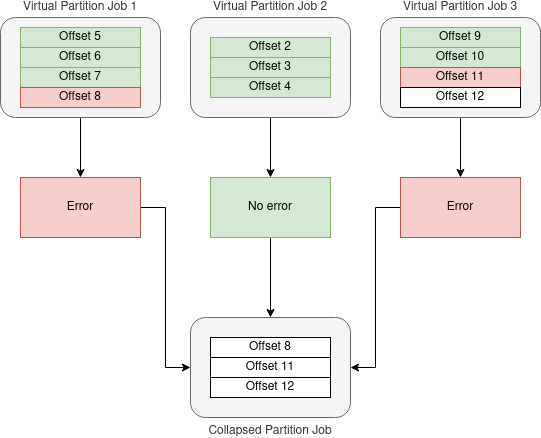
Up until now, when utilizing Virtual Partitions feature, the offset management was entirely collective. This meant that if any error occurred within any virtual partition during message processing, the entire set of virtual partitions from the starting offset would need to be processed again.
However, Karafka 2.1 introduces the concept of Virtual Offset Management, which enhances the previous offset management mechanism in several ways. When Karafka consumes messages using Virtual Partitions, it leverages Virtual Offset Management, which is built on top of the existing offset management mechanism. This feature allows for more granular and precise handling of offsets within each virtual partition.
While each of the Virtual Partitions operates independently, they are bound together to a single Kafka Partition. Karafka transforms the knowledge of messages marked as consumed in each virtual partition into a Kafka offset that can be committed. This process involves computing the highest possible offset by considering all the messages marked as consumed from all the virtual partitions. By analyzing the offsets across virtual partitions, Karafka can determine the maximum offset reached, allowing for an accurate and reliable offset commit to Kafka. This ensures that the state of consumption is properly synchronized and maintained.
Whenever you mark_as_consumed when using Virtual Partitions, Karafka will ensure that Kafka receives the highest possible continuous offset matching the underlying partition.
Below you can find a few examples of how Karafka transforms messages marked as consumed in virtual partitions into an appropriate offset that can be committed to Kafka.
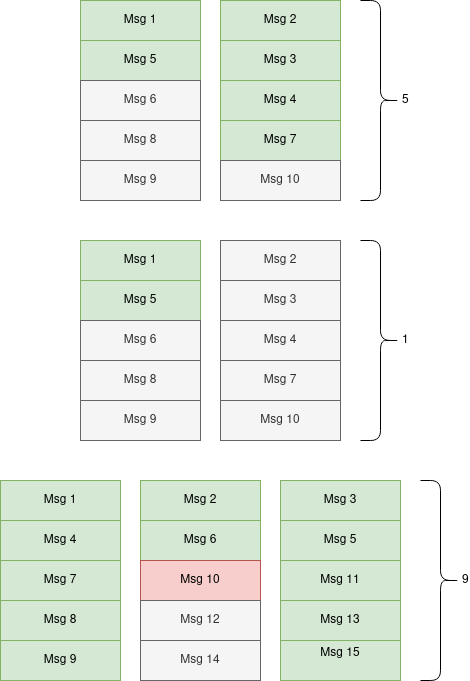
With Virtual Offset Management, Karafka keeps track of each virtual partition's offset separately. In case of any error occurring within a specific virtual partition, only that particular partition will be processed again from the point of the error.
This improvement significantly enhances the efficiency and reliability of message processing when working with Virtual Partitions. It minimizes redundant processing by isolating errors to the affected virtual partition, thereby reducing the overall processing time and resource consumption.
Below you can find a visualization of data re-processing from a single topic partition distributed across three virtual partitions. Karafka knows which of the messages were not processed successfully and will re-process only those when retrying.
CurrentAttributes support in ActiveJob
The Karafka ActiveJob adapter has been updated to support the Ruby on Rails CurrentAttributes feature. If you want to use it, you need to put this in your karafka.rb config file (or initializer):
require 'karafka/active_job/current_attributes'
Karafka::ActiveJob::CurrentAttributes.persist('YourCurrentAttributesClass')
# or multiple current attributes
Karafka::ActiveJob::CurrentAttributes.persist('YourCurrentAttributesClass', 'AnotherCurrentAttributesClass')When you set your current attributes and create a background job, it will execute with them set.
class Current < ActiveSupport::CurrentAttributes
attribute :user_id
end
class Job < ActiveJob::Base
def perform
puts 'user_id: #{Current.user_id}'
end
end
Karafka::ActiveJob::CurrentAttributes.persist('Current')
Current.user_id = 1
Job.perform_later # the job will output "user_id: 1"Karafka handles CurrentAttributes by including them as part of the job serialization process before pushing them to Kafka. These attributes are then deserialized by the ActiveJob consumer and set back in your CurrentAttributes classes before executing the job.
This approach is based on Sidekiq's approach to persisting current attributes: Sidekiq and Request-Specific Context.
Kubernetes Liveness support
I'm excited to share that Karafka 2.1 has introduced a new feature that will significantly enhance the reliability and stability of your Karafka server processes. With the addition of an out-of-the-box Kubernetes Liveness Listener, Karafka now allows for seamless implementation of liveness checks within your Kubernetes environment. But why is checking process liveness so important?
Liveness checks are critical for ensuring that a process runs as expected and actively consumes data. By enabling the Kubernetes Liveness Listener in Karafka 2.1, you can easily configure liveness checks without extra effort. This means that Kubernetes will automatically monitor the health of your Karafka server process, periodically sending requests to verify its liveness.
However, sometimes a process may appear active, yet it can actually be stuck on user logic. This situation can be challenging to detect without proper instrumentation. While the process might respond to system-level signals, it could be unresponsive within its user logic or certain parts of the codebase. These issues, often called "liveness bugs," can lead to degraded performance, data inconsistencies, or even complete service disruptions.
With the Kubernetes Liveness Listener in Karafka 2.1, you can proactively detect such liveness bugs. By regularly checking the health of your Karafka server process, Kubernetes will be able to identify situations where the process is unresponsive, even if it appears active from a system-level perspective. This enables you to take timely actions, such as restarting the process or triggering alerts for investigation, ensuring the overall stability and reliability of your Karafka applications.
Subscribe the Kubernetes listener within your Ruby code:
require 'karafka/instrumentation/vendors/kubernetes/liveness_listener'
listener = ::Karafka::Instrumentation::Vendors::Kubernetes::LivenessListener.new(
port: 3000,
# Make sure polling happens at least once every 5 minutes
polling_ttl: 300_000,
# Make sure that consuming does not hang and does not take more than 1 minute
consuming_ttl: 60_000
)
Karafka.monitor.subscribe(listener)And add a liveness probe to your Karafka deployment spec:
livenessProbe:
httpGet:
path: /
port: 3000
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5Upgrade Notes
No significant changes are needed. Just follow the changelog-based upgrade notes.
Karafka Pro
Karafka Pro has many valuable, well-documented, well-tested functionalities that can significantly improve your day-to-day operations with Kafka in Ruby. It also introduces commercial support, as due to a sheer number of questions and requests, I do need to have a way to prioritize those.
Help me build and maintain a high-quality Kafka ecosystem for Ruby and Ruby on Rails.
References
- Karafka Github
- Getting started with Karafka
- Github Karafka 2.1 release notes
- Karafka 2.1 docs
- WaterDrop (producer) wiki
- Example applications
- Karafka 2.1 upgrade notes
Stay tuned and don't forget to join our Slack channel.