
Half a year ago, I've made a post about Enforcing unique jobs in Karafka and Sidekiq for single resources. This approach is great, however, there's a particular case in which Sidekiq Unique Jobs can block all of your Sidekiq workers except one. This can significantly limit your computing power without you being aware of it.
When using Sidekiq Unique Jobs with a WhileExecuting strategy, only a single worker can start processing Sidekiq job with a given unique key. This is really helpful when you work with resources for which you cannot perform parallel operations (for example when you work with a database for which there are no atomic operations but you need to increment counters), as doing so could overwrite results from an other worker. A WhileExecuting strategy, with a properly defined unique key can help you prevent that from happening. However...
Problem definition
Sidekiq jobs are being consumed out of a FIFO queue. Without any additional modifications, situation is pretty clear: having 4 single threaded processes each allows you to process 4 jobs at the same time.
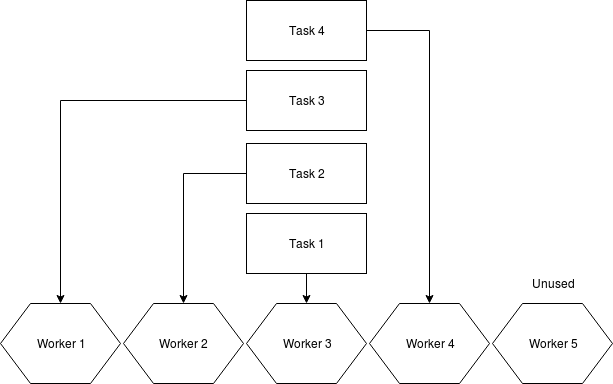
Everything changes, when you decide to add Sidekiq Unique Jobs to your stack. In a case, when there are multiple jobs in sequence for a given unique key, Sidekiq will get seriously clogged. In the worst scenario, it won't matter how many workers and threads you have in your Sidekiq infrastructure. You will get a performance of a single Sidekiq thread. It is because you cannot make Sidekiq skip certain tasks because of FIFO queue processing. To bypass this limitation, authors of Sidekiq Unique Jobs introduced a #sleep that will run up until the resource is free again to be processed or until timeout occurs. This approach means, that if you have more tasks in queue than processors, they will have to wait until all the jobs with a given unique key are processed.
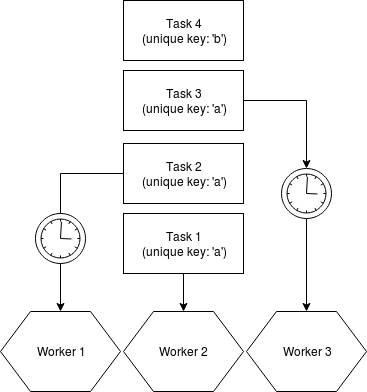
All the workers will actively wait (meaning that in Sidekiq console you will see them marked as busy) up until a lock is released.
Solution: reschedule instead of waiting
Warning: if a similar case occurs in your business logic quite often, probably you will be better taking engine different than Sidekiq. I would recommend this solution for non-frequent edge/corner cases.
Bypassing that behavior is pretty easy: if there's a lock, put the current job at the end of the queue. That said, your jobs will be checked for possibility of execution and rescheduled back instead of waiting. This will mess up your queue counters a bit (as you will have more jobs enqueued and processed that it should) but on the other hand it means that Sidekiq will "actively" seek for resources on which it can work in a certain moment.
To do so, we can create a new Unique Job strategy that we can later on apply. Apart from rescheduling, our strategy won't differ from the WhileExecuting, so we can use it as a base.
module SidekiqUniqueJobs
module Lock
class WhileExecutingReschedule < WhileExecuting
MUTEX = Mutex.new
def synchronize
MUTEX.lock
if (@locked = locked?)
yield
else
# We use sleep just to prevent from a pointless, extremely fast looping
# in case all the jobs have the same unique key
sleep 0.1
@item['class'].constantize.perform_async(*@item['args'])
end
rescue Sidekiq::Shutdown
logger.fatal { "the unique_key: #{@unique_digest} needs to be unlocked manually" }
raise
ensure
# If we were able to obtain lock, we need to release it after processing
if @locked
SidekiqUniqueJobs.connection(@redis_pool) { |conn| conn.del @unique_digest }
end
MUTEX.unlock
end
end
end
end
Applying this strategy is super easy. We just need to replace while_executing strategy with while_executing_reschedule:
class ApplicationWorker include Sidekiq::Worker # sidekiq_options unique: :while_executing sidekiq_options unique: :while_executing_reschedule end
Cover photo by: Alexandre Duret-Lutz on Creative Commons 2.0 license. Changes made: added an overlay layer with an article title on top of the original picture.


