Table of Contents
I'm thrilled to announce the new and shiny Karafka 2.0. It is an effect of my work of almost four years.
For those who wonder what Karafka is, Karafka is a Ruby and Rails multi-threaded efficient Kafka processing framework.
Karafka 2.0 is a major rewrite that brings many new things to the table but removes specific concepts that were not as good as I initially thought when I created them.
In this announcement article, I will describe the most noticeable features and improvements that got into this release. If you are interested in a more comprehensive list, you can find it here.
Note: Upgrade notes for migration from Karafka 1.4 to Karafka 2.0 can be found here.
Getting started
If you are new to Karafka and want to play around, follow this demo or visit the Getting Started page:
Noticeable features and improvements
This section includes all the noticeable changes you may be interested in if you already work with Karafka or if you want to understand the journey.
Multi-threading
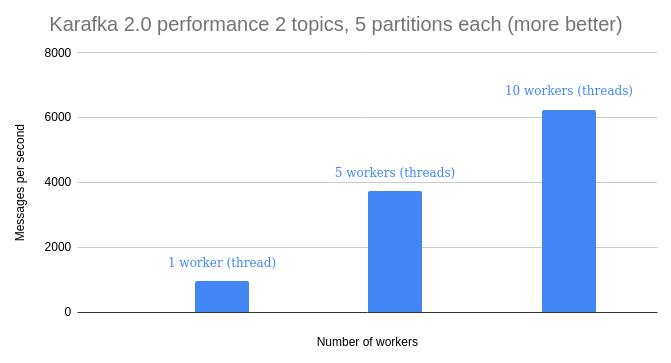
Most of the engineering work around this release was about performance, scalability, and improvement of the overall engineering experience.
Multi-threading is probably the most significant change in Karafka since it was created. Up until now, Karafka was single-threaded. That means that any concurrency would have to be implemented by the end user. The reason is dead simple: concurrency is hard. Synchronization is hard. Warranties are hard. I do feel (and can back it up with integration specs) that I tackled it pretty well.
Karafka 2.0 uses native Ruby threads to achieve concurrent processing in three scenarios:
- for concurrent processing of messages from different topics partitions.
- for concurrent processing of messages from a single partition when using the Virtual Partitions feature.
- to handle consumer groups management (each consumer group defined will be managed by a separate thread)
This can bring big advantages when any IO is involved.
When you start consuming messages, Karafka will fetch and distribute data to utilize multiple threads while preserving all the Kafka ordering warranties.
Years ago, I developed a lot of in-app async code to bypass Karafka limitations, and it makes me extremely happy to be able to retire all of it.
But wait, there's more...
Virtual Partitions
Virtual Partitions allow you to parallelize the processing of data from a single partition. This can drastically increase throughput when IO operations are involved.
While the default scaling strategy for Kafka consumers is to increase partitions count and number of consumers, in many cases, this will not provide you with desired effects. In the end, you cannot go with this strategy beyond assigning one process per single topic partition. That means that without a way to parallelize the work further, IO may become your biggest bottleneck.
Virtual Partitions solve this problem by providing you with the means to further parallelize work by creating "virtual" partitions that will operate independently but will obey all the Kafka warranties as a collective processing unit.
topic :orders_states do
consumer OrdersStatesConsumer
# Distribute work to virtual partitions based on the user id
virtual_partitions(
partitioner: ->(message) { message.payload[:user_id] }
)
endWith Virtual Partitions, you benefit from both worlds: scaling with Kafka partitions and scaling with Ruby threads.

*This example illustrates the throughput difference for IO intense work, where the IO cost of processing a single message is 1ms.
Active Job support
Active Job is a standard interface for interacting with job runners in Ruby on Rails. Active Job can be configured to work with Karafka.
While Kafka is not a message queue, I still decided to create an Active Job adapter for it. Why? Because ordered jobs are something, I always wished for Ruby on Rails to have. On top of that, you may already have Kafka and only a few jobs to run. If so, why not use it and save yourself a hustle of yet another tool to maintain?
class Application < Rails::Application
# ...
config.active_job.queue_adapter = :karafka
end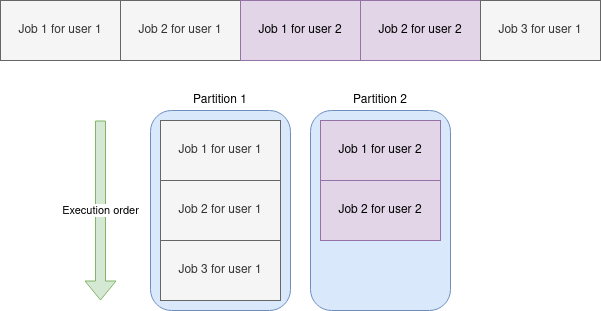
End-to-end integration test suite
Karafka comes with a home-brew framework for running end-to-end integration specs against Kafka. I did my best to describe every possible case I could have imagined to ensure that the framework behaves as expected under any circumstances.
It is also a great place to learn about how Karafka behaves in particular scenarios.
Lower supply chain fingerprint
The number of external dependencies Karafka relies on has been reduced significantly. It was done to ensure that Karafka can be integrated into and upgraded in applications without causing dependency conflicts.
Upgraded documentation
Karafka and WaterDrop have been fully updated with several new sections describing use-cases, edge-cases and providing help and suggestions for both simple and advanced usage.
Out-of-the-box DataDog and StatsD instrumentation
Using DataDog or StatsD? In just a few lines you can enable full instrumentation of both consumption and production of messages:
# initialize the listener with statsd client
dd_listener = ::Karafka::Instrumentation::Vendors::Datadog::Listener.new do |config|
config.client = Datadog::Statsd.new('localhost', 8125)
# Publish host as a tag alongside the rest of tags
config.default_tags = ["host:#{Socket.gethostname}"]
end
# Subscribe with your listener to Karafka and you should be ready to go!
Karafka.monitor.subscribe(dd_listener)
License change
Karafka 2.0 is dual licensed under LGPL and a Commercial License. Depending on your use-case, you should be good with one or the other.
Note: Before the license change, I did obtain the consent of all the contributors for a re-license. I want to say thank you to each of you for allowing me to do so.
Seamless Ruby on Rails integration
Karafka always had good integration with Ruby on Rails. With the 2.0 release, however, this integration is elevated to another level: no more files editing, no more configuration copying. Everything works out of the box.
Karafka Pro
This release is the first release that includes a Pro subscription.
Building a complex and reliable open-source is neither easy nor fast. Many companies rely on Karafka, and following Mikes Perham advice I have decided to introduce the Pro subscription to be able to support the further development of the ecosystem.
Karafka Pro has many valuable, well-documented, well-tested functionalities that can significantly improve your day-to-day operations with Kafka in Ruby. It also introduces commercial support, as due to a sheer number of questions and requests, I do need to have a way to prioritize those.
SInce it's not only me, 10% of the income will be further distributed down the supply chain pipeline to support the work of people I rely on.
Help me build and maintain a high-quality Kafka ecosystem for Ruby and Ruby on Rails.
Buy Karafka Pro.
Karafka 1.4 maintenance
With this release an official EOL policies have been introduced. Karafka 1.4 will be supported until the end of February 2023.
Karafka 2.0 has a lower dependency fingerprint and is in everything 1.4 was not. I strongly encourage you to upgrade.
What's ahead
Many things. This release is just the beginning. I am already working on a 2.1 release that will include several great additions, including:
- Management Web-UI similar to the one Resque and Sidekiq have
- Producer transactions
- At Rest encryption
- CurrentAttributes support for ActiveJob
- Seamless Dead-Letter Queue integration
Upgrade notes
Upgrade notes for migration from Karafka 1.4 to Karafka 2.0 can be found here.
References
- Karafka Github
- Getting started with Karafka
- Github Karafka 2.0 release notes
- Karafka 2.0 docs
- WaterDrop (producer) wiki
- Example applications
- Karafka 2.0 upgrade notes
Stay tuned and don't forget to join our Slack channel.