Note: These release notes cover only the major changes. To learn about various bug fixes and changes, please refer to the change logs or check out the list of commits in the main Karafka repository on GitHub.
Table of Contents
- 1 Code quality
- 2 Performance
- 3 Features
- 3.1 Controllers are now Consumers
- 3.2 New instrumentation engine using Dry-Monitor
- 3.3 Dynamic Karafka::Params::Params parent class
- 3.4 System callbacks reorganization with multiple callbacks support
- 3.5 before_fetch_loop configuration block for early client usage (#seek, etc)
- 3.6 Rewritten NewRelic client
- 3.7 Key and/or partition key support for responders
- 3.8 Alias for client#mark_as_consumed on a consumer level
- 4 Incompatibilities and breaking changes
- 4.1 Controllers are now Consumers
- 4.2 after_fetched renamed to after_fetch to normalize the naming convention
- 4.3 received_at renamed to receive_time to follow ruby-kafka and WaterDrop conventions
- 4.4 Hash is now the default params base class in favor of ActiveSupport::HashWithIndifferentAccess
- 4.5 All metadata keys are strings by default
- 4.6 JSON parsing defaults now to string keys
- 4.7 Configurators removed in favor of the after_init block configuration
- 4.8 Karafka ecosystem gems versioning convention
- 5 Documentation
- 6 Upgrade guide
- 7 Getting started with Karafka
Note: 1.2 release is the last release that will require ActiveSupport to work.
Code quality
I will start with the same thing as with 1.1. We're constantly working on having a better and easier code base. Despite many changes to our code-base stack, we were able to maintain a pretty decent offenses distribution and trends.
It's worth pointing out, that we're now using more extensively many components of the Dry-Rb ecosystem and we love it!
Performance
This release brings significant performance improvements allowing you to consume around 40-50k messages per second per single topic. We could do a bit more (around 5-10%) by using symbols as defaults for metadata params key names, but this would bring up a lot of complexity and confusion since JSON parsing returns string keys. It would also introduce some problematic incompatibilities when using additional backend engines that serialize the whole params_batch and deserialize it back.
Karafka is a complex piece of software and benchmarking it can be tricky. There are many use-cases that need to be considered. Some of them single threaded, some of them multi-threaded, some with a non-parsed data rejections and some requiring multiple-thread interactions. That's why it is really hard to design a single benchmark that will be able to compare multiple Kafka + Ruby frameworks in a fair way.
We've decided not to go that way, but rather compare new releases with the previous once. Here are the results of running the same logic with 1.1 and 1.2 multiple times (the more the better):
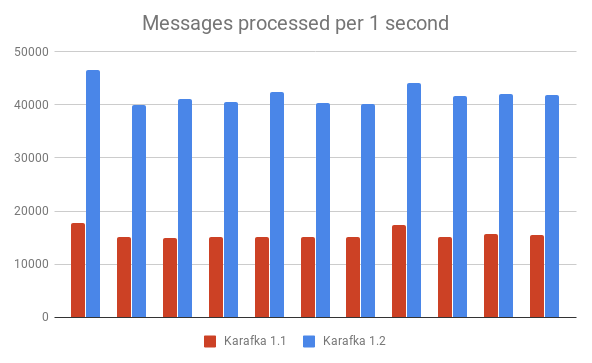
For some edge cases, Karafka 1.2 can be up to 3x faster than 1.1.
If you are looking for some cross-framework benchmark results, they are available here.
Features
Controllers are now Consumers
Initial versions of Karafka were built with an idea, that we could ignore the transportation layer when working with data. Regardless whether it was an HTTP request, Kafka message or anything else, as long as the data is in a compatible format, we should not have to adapt our business logic to it.
That was the primary reason, why prior to Karafka 1.2 you would put logic in controllers that inherited from ApplicationController or KarafkaController. And this was a mistake.
More and more companies use Karafka within a typical Ruby on Rails stack in which controllers are meant to be Rails controllers. Less experienced developers that encounter Karafka controllers within Rails app/controllers namespace would often end up trying to use some Rails controllers API specific magic without realizing that they're within Karafka controller scope. To eliminate this problem and to match Kafka naming conventions, the processing units that are responsible for feeding you with Kafka data are being renamed to Consumers and from now on, there are no controllers in the Karafka ecosystem.
# Within app/consumers
class UsersCreatedConsumer < ApplicationConsumer
def consume
params_batch.each { |params| User.create!(params['user']) }
end
end
New instrumentation engine using Dry-Monitor
Note: Dry-Monitor usage requires a separate article. Here's just a brief summary of what we did with it.
Old Karafka monitor was too magical. It would auto-detect the context in which it is invoked, automatically building notification scopes and doing a lot of other things. This was really cool but it was:
- Slow
- Hard to maintain
- Bug sensitive
- Code change sensitive
- Not isolated from the rest of the system
- Hard to use with custom tools like NewRelic or Airbrake
- Limited when it comes to instrumenting with multiple tools at the same time
- Too custom to be easily replaced
We are proud to announce, that from now on, Dry-Monitor is the instrumentation backbone of the whole Karafka ecosystem. Here's a simple example of what you can achieve using it:
Karafka.monitor.subscribe 'params.params.parse.error' do |event|
puts "Oh no! An error: #{event[:error]} occurred!"
end
and to be honest, possibilities are endless. From simple logging, through in-production performance monitoring up to multi-target complex instrumentation. Please refer to the Monitoring and logging section of Karafka Wiki for more details.
Dynamic Karafka::Params::Params parent class
Karafka is designed to handle a lot of messages. Each incoming message is wrapper with a lazy evaluated hash-like object. Prior to 1.2, each params object was built based on ActiveSupport::HashWithIndifferentAccess. Truth be told, it is not the fastest library ever (benchmark details here), especially when compared to a PORO Hash:
Comparison: Common Hash#[] access: 8306261.5 i/s Common Hash#fetch access: 6053147.2 i/s - 1.37x slower HashWithIndifferentAccess #[] String: 3803546.0 i/s - 2.18x slower HashWithIndifferentAccess#fetch String: 1993671.6 i/s - 4.17x slower HashWithIndifferentAccess#fetch Symbol: 1932004.0 i/s - 4.30x slower HashWithIndifferentAccess #[] Symbol: 1422367.3 i/s - 5.84x slower Hash#with_indifferent_access #[] String: 470876.8 i/s - 17.64x slower Hash#with_indifferent_access #fetch String: 414701.6 i/s - 20.03x slower Hash#with_indifferent_access #fetch Symbol: 410033.7 i/s - 20.26x slower Hash#with_indifferent_access #[] Symbol: 381347.2 i/s - 21.78x slower
Now imagine that in some cases, we create 50 0000 objects like that per second. This had to have a serious impact on the framework performance. As always, there needs to be a trade-off. Should we go with a Hash in the name of performance or should we use HashWithIndifferentAccess for the sake of the "simplicity"? We will let you choose whatever you find more suitable.
For that reason, we've provided a config params_base_class setting that you can use to set up the base params class from which Karafka::Params::Params will inherit. By default, it is a plain Hash.
require 'active_support/hash_with_indifferent_access'
class App < Karafka::App
setup do |config|
# Other settings...
# config.params_base_class = Hash
config.params_base_class = HashWithIndifferentAccess
end
end
Keep in mind, that you can use other base classes like for example concurrent hash for your advantage. The only requirement is that it needs to have the same API as a Ruby Hash.
System callbacks reorganization with multiple callbacks support
Note: This will be unified with a one set of events that you will be able to hook up to in 1.3 using Dry-Events.
Due to the fact, that some of the things happen in Karafka outside of consumers scope, there are two types of callbacks available:
- Lifecycle callbacks - callbacks that are triggered during various moments in the Karafka framework lifecycle. They can be used to configure additional software dependent on Karafka settings or to do one-time stuff that needs to happen before consumers are created.
- Consumer callbacks - callbacks that are triggered during various stages of messages flow
You can read more about them and how to use them in the Callbacks wiki section.
before_fetch_loop configuration block for early client usage (#seek, etc)
This new callback will be executed once per each consumer group per process before we start receiving messages. This is a great place if you need to use Kafka's #seek functionality to reprocess already fetched messages again.
Note: Keep in mind, that this is a per process configuration (not per consumer) so you need to check if a provided consumer_group (if you use multiple) is the one you want to seek against.
class App < Karafka::App
# Setup and other things...
# Moves the offset back to 100 message, so we can reprocess messages again
# @note If you use multiple consumers group, make sure you execute #seek on a client of
# a proper consumer group not on all of them
before_fetch_loop do |consumer_group, client|
topic = 'my_topic'
partition = 0
offset = 100
if consumer_group.topics.map(&:name).include?(topic)
client.seek(topic, partition, offset)
end
end
end
Rewritten NewRelic client
Thanks to NewRelic kindness, we were able to rewrite the whole listener that now can collect various information about the Karafka data flow. It is super easy to use and extend. You can find it in the Monitoring and Logging wiki section.
Key and/or partition key support for responders
You can now provide key and/or partition_key when using responders:
module Users
class CreatedResponder < KarafkaResponder
topic :users_created
def respond(user)
respond_to :users_created, user, key: user.id
end
end
end
Alias for client#mark_as_consumed on a consumer level
Simple yet powerful. For max performance, you may use manual offset commit management. If you do that, you can now use the #mark_as_consumed directly, without having to refer to the #client object.
class UsersCreatedConsumer < ApplicationConsumer
def consume
params_batch.each { |params| User.create!(params['user']) }
mark_as_consumed params_batch.last
end
end
Incompatibilities and breaking changes
Controllers are now Consumers
Please refer to the features section with this one. It is both a feature and a breaking change at the same time.
after_fetched renamed to after_fetch to normalize the naming convention
class ExamplesConsumer < Karafka::BaseConsumer
include Karafka::Consumers::Callbacks
after_fetched do
# Some logic here
end
def consume
# some logic here
end
end
is now:
class ExamplesConsumer < Karafka::BaseConsumer
include Karafka::Consumers::Callbacks
after_fetch do
# Some logic here
end
def consume
# some logic here
end
end
received_at renamed to receive_time to follow ruby-kafka and WaterDrop conventions
received_at params key is now receive_time. This means that two timestamp values are available for each params object:
- receive_time - the moment message was received by our Karafka process
- create_time - the moment our message was created in the producer
Hash is now the default params base class in favor of ActiveSupport::HashWithIndifferentAccess

Long story short: performance and fewer dependencies. You can still use it though:
require 'active_support/hash_with_indifferent_access'
class App < Karafka::App
setup do |config|
# Other settings...
config.params_base_class = HashWithIndifferentAccess
end
end
All metadata keys are strings by default
Since now the default params class is a Hash, we had to pick either symbols or strings as key names for all the metadata attributes. We've decided to go with strings as they are more serialization friendly and cooperate with various backends used with Karafka.
Note: If you use HashWithIndifferentAccess, nothing really changes for you.
def consume params_batch.first.keys #=> ["parser", "partition", "offset", "key", "create_time", ...] end
JSON parsing defaults now to string keys
Since there is no indifferent access by default, when lazy parsing the JSON Kafka data, it will default to string keys that will be merged to the params object. If you're not planning to use the HashWithIndifferentAccess make sure that your code-base is ready for this change.
Karafka 1.1:
class UsersCreatedConsumer < ApplicationConsumer
def consume
# Assuming user data is in the 'user' json scope
params_batch.each do |params| params[:user] #=> { name: 'Maciek' }
params['user'] #=> { name: 'Maciek' }
params['receive_time'] #=> 2018-02-27 18:53:31 +0100
end
end
end
Karafka 1.2:
class UsersCreatedConsumer < ApplicationConsumer
def consume
# Assuming user data is in the 'user' json scope
params_batch.each do |params| params[:user] #=> nil
params['user'] #=> { name: 'Maciek' }
# Note, that system keys are strings as well
params['receive_time'] #=> 2018-02-27 18:53:31 +0100
end
end
end
Configurators removed in favor of the after_init block configuration
What were configurators? Let me quote 1.1 wiki on that one:
For additional setup and/or configuration tasks you can create custom configurators. Similar to Rails these are added to a config/initializers directory and run after app initialization.
Due to a changed lifecycle of Karafka process, more things are being built dynamically upon boot. This means that in order to run initializers in a good way, we would have to control the load order in a more granular way. That's why this functionality has been replaced with an after_init callback declaration:
class App < Karafka::App
# Setup and other things...
# Once everything is loaded and done, assign Karafka app logger as a Sidekiq logger
# @note This example does not use config details, but you can use all the config values
# to setup your external components
after_init do |_config|
Sidekiq::Logging.logger = Karafka::App.logger
end
end
Note: you can have as many callbacks of any type as you want to. They also can be objects as long as the respond to a #call method.
Karafka ecosystem gems versioning convention
Karafka is combined from several independent libraries. The most important are:
- Karafka - The main gem that is used to build Karafka applications that consume messages
- WaterDrop - WaterDrop is a standalone Karafka component library for generating Kafka messages
- Capistrano-Karafka - Integration for deployment using Capistrano
- Karafka Sidekiq Backend - an optional proxy that will pass messages received from Karafka into Sidekiq jobs
Some Karafka users had problems using mismatched versions of those gems. From now on, they all will be released in sync up to the second version point. It means that if you decide to use Karafka 1.2 with other ecosystem libraries, you should match them to 1.2.* as well.
Note: This should be resolved automatically as we locked all the proper versions within gemspec, but still worth mentioning.
Documentation
Our Wiki has been updated accordingly to the 1.2 status. You probably may want to look at the rewritten Monitoring and logging section and the new Testing guide that illustrates how you can test various Karafka ecosystem components.
Upgrade guide
Controllers are now Consumers
Following steps are required to move from controllers:
- 1. Create app/consumers directory
- 2. Rename ApplicationController (or KarafkaController) to ApplicationConsumer / KarafkaConsumer
- 3. Move the ApplicationController and all Karafka controllers to app/consumers
- 4. Rename files and classes by replacing "Controller" with "Consumer"
- 5. If you use callbacks, don't forget about Karafka::Consumers::Callbacks
- 6. Do exactly the same with your specs/tests
- 7. Replace the controller consumers groups definition in the karafka.rb file with consumer
- 8. Rename all the "Controller" with "Consumer" in the karafka.rb file
Karafka, WaterDrop and friends version match
This should be resolved automatically but if you prefer, you can always lock all the Karafka ecosystem gems in your gemfile:
gem 'karafka', '~> 1.2' gem 'karafka-sidekiq-backend', '~> 1.2' gem 'capistrano-karafka', '~> 1.2'
Ruby on Rails HashWithIndifferentAccess params compatibility mode
If you still want to use HashWithIndifferentAccess, feel free to:
require 'active_support/hash_with_indifferent_access'
class App < Karafka::App
setup do |config|
# Other settings...
# config.params_base_class = Hash
config.params_base_class = HashWithIndifferentAccess
end
end
Default monitor and logger update
Please refer to the Monitoring and logging Wiki section for details of the way both of those things work now. If you used the default monitoring and logging without any customization, all you need to do is add this to your karafka.rb file after the setup part:
Karafka.monitor.subscribe(Karafka::Instrumentation::Listener)
NewRelic client update
If you use our NewRelic example client, please take a look at the new one and upgrade accordingly.
Callbacks rename
class ExamplesConsumer < Karafka::BaseConsumer
include Karafka::Consumers::Callbacks
# Rename this
after_fetched do
# Some logic here
end
# To this
after_fetch do
# Some logic here
end
end
Karafka params received_at renamed to receive_time
Again, just a name change: if you use 'received_at' params timestamp, you'll enjoy it under the 'receive_time' key.
Getting started with Karafka
If you want to get started with Kafka and Karafka as fast as possible, then the best idea is to just clone our example repository:
git clone https://github.com/karafka/karafka-example-app ./example_app
then, just bundle install all the dependencies:
cd ./example_app bundle install
and follow the instructions from the example app Wiki.