Table of Contents
Recently I've released a Ruby Apache Kafka microframework, however I don't expect anyone to use it without at least a bit information on what it can do. Here are some measurements that I took.
How Karafka handles multiple TCP connections
Since listening to multiple topics require multiple TCP connections it is pretty obvious that in order to obtain a decent performance, we are using threads (process clustering feature is in progress). Each controller that you create theoretically could have a single thread and could listen all the time. However with a bigger application, it could slow down the application. That's why we introduced topics clusterization. When you config your Karafka application, you should specify the concurrency parameter:
class App < Karafka::App
setup do |config|
# Other config options
config.max_concurrency = 10 # 10 threads max
end
end
This is a maximum number of threads that will be used to listen for incoming messages. It is pretty simple when you have less controllers (topics) than threads - it will just use a single thread per topic. However if you have more controllers then threads - few connections will be packed in a single thread (wrapped with Karafka::Connection::ThreadCluster). And this is how it works when you have 2 threads and 4 controllers:
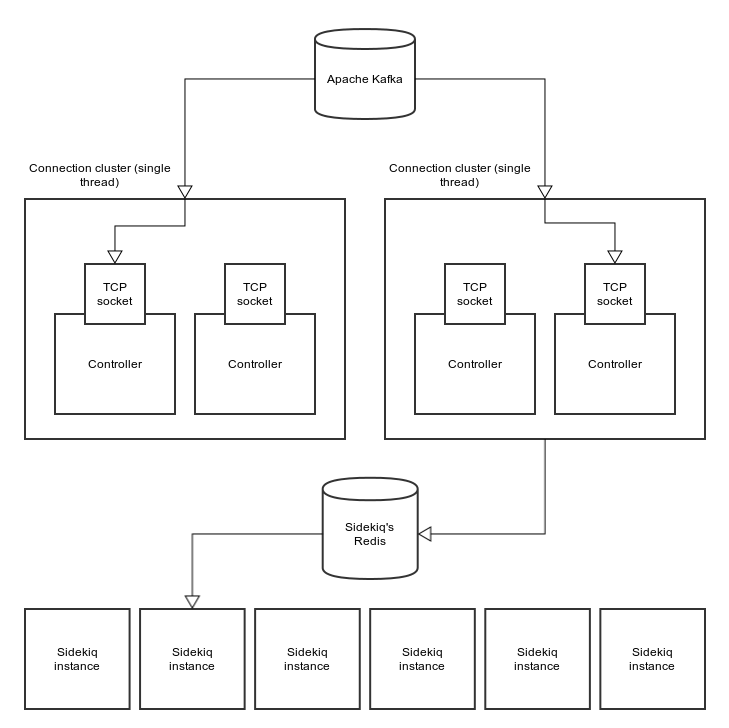
In general, it will distribute TCP connections across threads evenly. So, if you have 20 controllers and 5 threads, each thread will be responsible for checking 4 sockets, one after another. Since it won't do this simultaneously, Karafka will slow down. How much? It depends - if there's something on each of the topics - you will get around 24% (per controller) of the base performance out of each connection.
Other things that have impact on the performance
When considering this framework's performance, you need to keep in mind that:
- It is strongly dependent on what you do in your code
- It depends also on Apache Kafka performance
- Connection between Karafka and Redis (for Sidekiq) is a factor as well
- All the benchmarks show the performance without any business logic
- All the benchmarks show the performance without enqueuing to Sidekiq
- It also depends on what type of infrastructure you benchmark everything
- Message size is a factor as well (since it get deserialized to JSON by default)
- Ruby version - I've been testing in on MRI (CRuby) 2.2.3 - Karafka is not yet working with other Ruby distributions (JRuby or Rubinius) but it should change when some of the dependencies stop using refinements
Benchmarking
Methodology
For each of the benchmarks I was measuring time taken to consume all messages that were stored in Kafka. There were no business logic involved (just messages processing by the framework). My local Kafka setup was a default setup (no settings were changed) introduced with this Docker containers.
I've tested up to 5 topics - each with 1 000 000 messages loaded. Since Karafka has lazy loading for params - benchmark does not include time that is needed to unparse the messages. Unparsing performance strongly depends on a parser you pick (defaults to JSON) and messages size. Those benchmarks measure maximum throughput that we can get during messaging receiving.
Note: all the benchmarking was performed on my 16GB, 4 core i7 processor, Linux laptop. During the benchmarking I've been performing other tasks that might have small impact on overall results (although no heavy stuff).
1 thread
With a single thread it is pretty straightforward - the more controllers we have, the less we can process per controller. There's also controllers context switching overhead that consumes some of the power, allowing us to consume less and less. Switching between controllers seems to consume around 11% of a single controller performance when we tend to use more than 1 controller in a single threaded application.
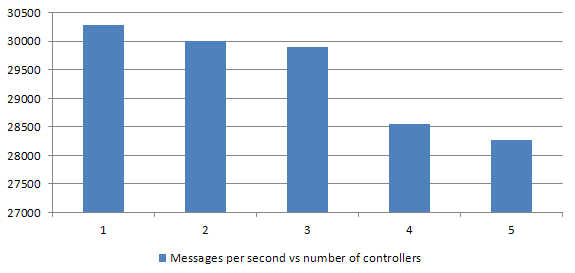
Context switching between controllers in a single thread will cost us around 1% of a general performance per one additional controller (if you're eager to know what we're planning to do with it scroll down to the summary). On one side it is a lot, on the other, with a bigger application you should probably run Karafka in multithreaded mode.. That way context switching won't be as painful.
2 threads
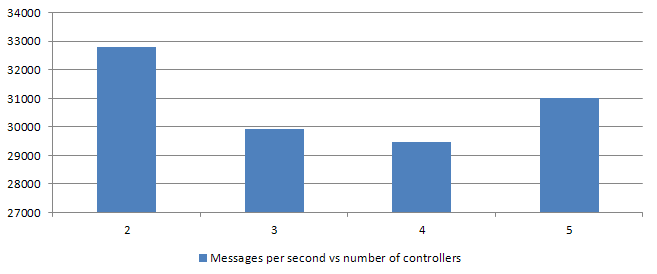
General performance with 2 threads and 2 controllers proves that we're able to lower switching impact on a overall performance, gaining around 1.5-2k requests per second (overall).
3 threads
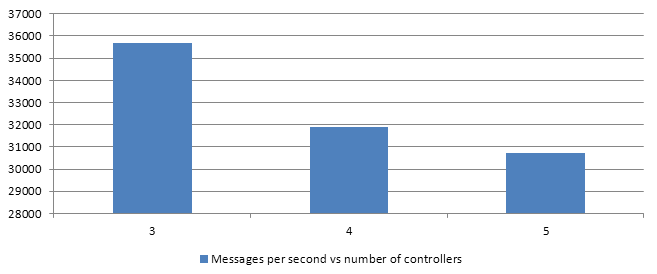
5 controllers with 3 threads vs 5 controllers with 1 thread: 7% better performance.
4 threads
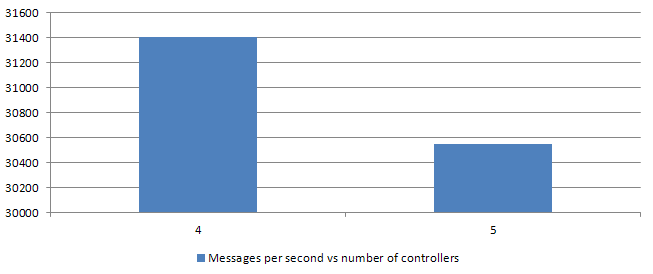
5 threads
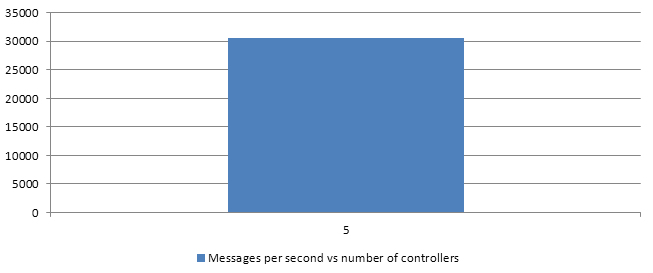
Benchmarks results
Summary
The overall performance of a single Karafka framework process is highly dependent on the way it is being used. Because of GIL, when we receive data from sockets, we can only process incoming messages from a single socket at a time. So in general we're limited to around 30-33k requests per second per process. It means that the bigger the application gets, the slower it works (when we consider total performance per single controller). However this is only valid when we assume that all the topics are always full of messages. Otherwise we don't process, we wait on the IO and Ruby can process incoming messages from multiple threads. That's why it is worth starting Karafka with a decent concurrency level.
How can we increase throughput for Karafka applications? Well for now, we can create multiple partitions for a single topic and spin up multiple Karafka processes. Then they will load balance between partitions automatically. This solution has one downside: if we have only few topics with multiple partitions and rest with a single one, then some of the threads in Karafka won't perform any work. This will be fixed soon (we're already working on it), when we will introduce a Karafka processes clustering. It will allow to spin up multiple Karafka processes (in a single cluster) that will listen only for a given part of controllers. That way the overall performance will increase significantly. But still being able to perform 30k rq/s is not that bad, right? ;)
March 27, 2016 — 18:24
why doesn’t use fiber?
April 4, 2016 — 17:13
for what purpose? Fiber would be nice if I would have a lot of code that would run/stop many times – Karafka uses multiple tcp connections so it can work nice with threads even in MRI