When doing multi-threaded work in Ruby, there are a couple of ways to control the execution flow within a given thread. In this article, I will be looking at Thread#pass and Queue#pop and how understanding each of them can help you drastically optimize your applications.
Thread#pass - what it is and how does it work
One of the ways you can ask the scheduler to "do something else" is by using the Thread#pass method.
Where can you find it? Well, aside from Karafka, for example in one of the most recent additions to ActiveRecord called #load_async (pull request).
Let's see how it works and why it may or may not be what you are looking for when building multi-threaded applications.
Ruby docs are rather minimalistic with its description:
Give the thread scheduler a hint to pass execution to another thread. A running thread may or may not switch, it depends on OS and processor.
That means that when dealing with threads, you can tell Ruby that it would not be a bad idea to switch from executing the current one and focusing on others.
By default, all the threads you create have the same priority and are treated the same way. An excellent illustration of this is the code below:
threads = []
threads = 10.times.map do |i|
Thread.new do
# Make threads wait for a bit so all threads are created
sleep(0.001) until threads.size == 10
start = Time.now.to_f
10_000_000.times do
start / rand
end
puts "Thread #{i},#{Time.now.to_f - start}"
end
end
threads.each(&:join)
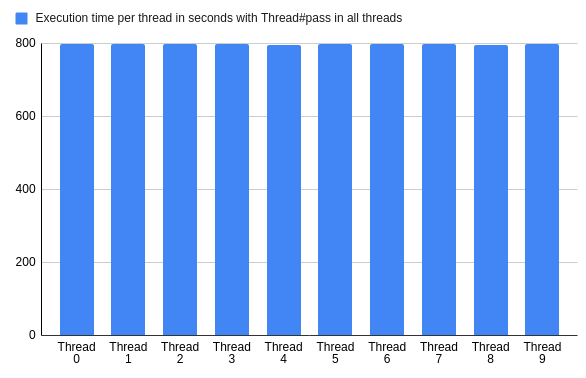
# for i in {1..1000}; do ruby threads.rb; done > results.txton average, the computation in each of them took a similar amount of time:
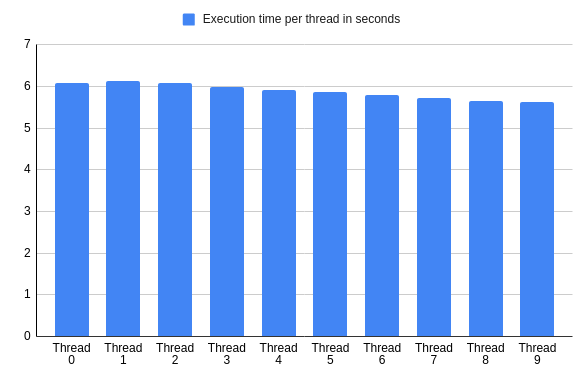
The difference in between the fastest and the slowest thread was less than 8%.
However, when one of the threads "passes," things change drastically:
threads = []
threads = 10.times.map do |i|
Thread.new do
sleep(0.001) until threads.size == 10
start = Time.now.to_f
10_000_000.times do
Thread.pass if i.zero?
start / rand
end
puts "Thread #{i},#{Time.now.to_f - start}"
end
end
threads.each(&:join)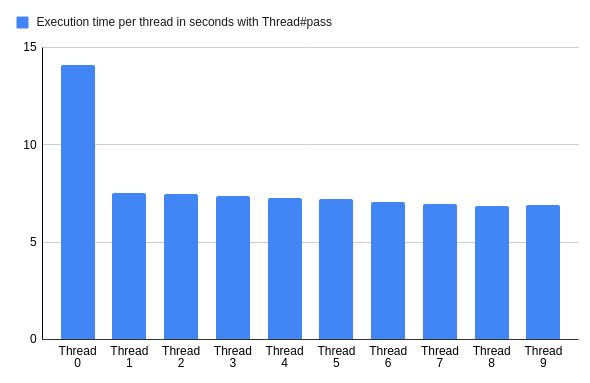
Now, thread zero takes twice as much time as other threads doing the same job.
What is worth pointing out is that this method does not stop the execution flow by itself, and it just suggests to Ruby that there may be other more important things to do.
Exactly this behaviour was used by Jean Boussier in ActiveRecord:
def schedule_query(future_result) # :nodoc:
@async_executor.post { future_result.execute_or_skip }
Thread.pass
endThis code schedules a background job and suggests to the scheduler that it may be worth doing that or other things somewhere else.
It is worth mentioning, that when all the threads use the Thread#pass, it becomes a colossal burden to the Ruby VM. Ruby goes crazy since none of the threads wants to do any work and the execution time increases over 100 times.
Queue#pop - What it is and how does it work
Queue is a well known class and #popis one of the most important methods it contains.
Here is what Ruby docs say about the Queue class and the #pop method:
The Queue class implements multi-producer, multi-consumer queues. It is especially useful in threaded programming when information must be exchanged safely between multiple threads. The Queue class implements all the required locking semantics.
#pop: If the queue is empty, the calling thread is suspended until data is pushed onto the queue. If non_block is true, the thread isn't suspended, and ThreadError is raised.
When asked about queues, most programmers think about workers consuming jobs from a queue:
numbers = Queue.new
threads = 10.times.map do |i|
Thread.new do
while number = numbers.pop
result = Time.now.to_f / number
# a bit of randomness
sleep(rand / 1_000)
puts "Thread #{i},#{result}"
end
end
end
10_000.times { numbers << rand }
# see what I did here? ;)
Thread.pass until numbers.empty?
numbers.close
threads.each(&:join)What is worth keeping in mind about Queue#pop is that it will block the execution in a given thread until there is something to do. This means, that a blocked thread becomes almost "invisible" from the performance perspective. Here's an example of running computations with 0 , 4, 9 and 99 blocked threads:
queue = Queue.new
THREADS = 4
THREADS.times do
Thread.new { queue.pop }
end
# Wait until all the threads are initialized
Thread.pass until queue.num_waiting == THREADS
start = Time.now.to_f
10_000_000.times do
start / rand
end
puts Time.now.to_f - start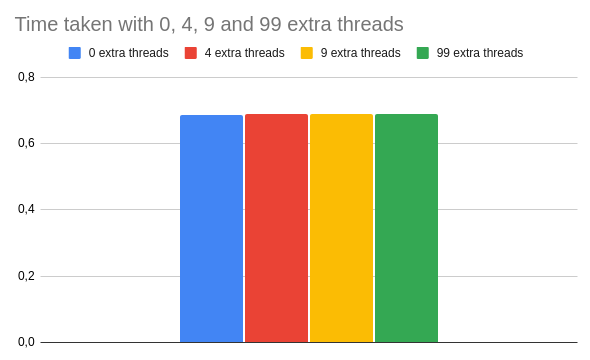
As you can see, inactive threads do not have a big impact on the overall performance of this code. Even with 99 extra threads, the end result is not far away from the baseline.
Reducing method calls in a multi-threaded environment
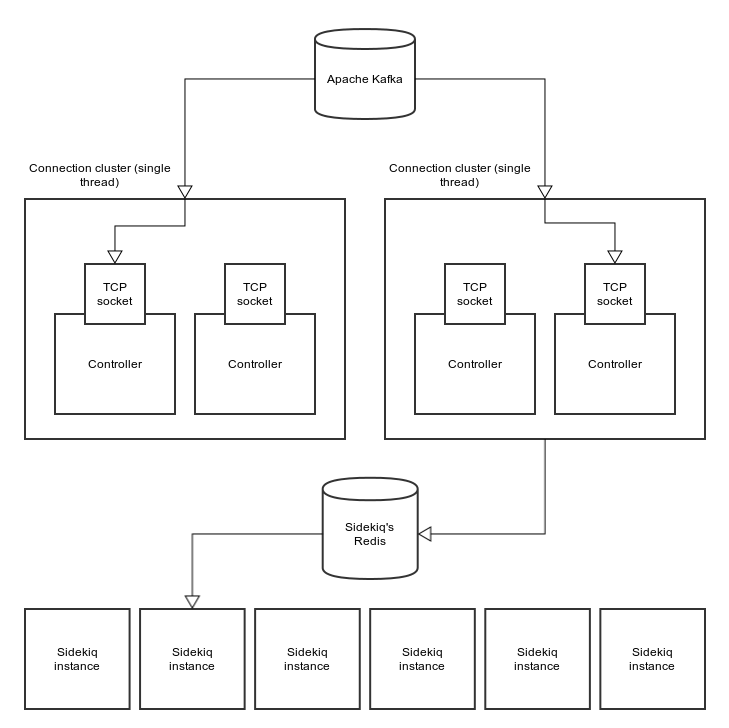
Now that you know what Thread#pass and Queue#pop do, lets put them to work in a real use case. For that to happen we will be looking into the Karafka framework.
Karafka is a framework used to simplify Apache Kafka-based Ruby applications development that I built. The version 2.0 supports work distribution across multiple threads. The way it works from a data processing perspective is quite simple:
1. Take some data from Kafka
2. Divide it into processing units (jobs)
3. Put all the jobs into a queue
4. Wait for all the workers to pick the jobs and finish all the work
5. Repeat endlessly
Assuming an endless stream of data available, this can be pretty much modelled as followed:
queue = Queue.new
THREADS = 10
THREADS.times do |i|
Thread.new do
loop do
data, task = queue.pop
task.call(data)
end
end
end
def wait_for_jobs_to_finish(queue)
Thread.pass while queue.num_waiting < THREADS || !queue.empty?
end
def data
Array.new(10) { rand }
end
task = ->(data) { data * 2 }
100_000.times do
data.each { queue << [_1, task] }
wait_for_jobs_to_finish(queue)
endAnd this is how the listener loop together with jobs distributions was implemented by me initially.
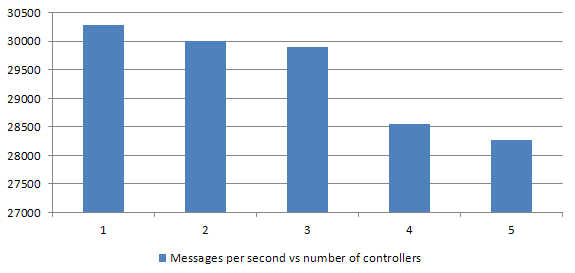
When benchmarked in regards to the number of times Thread#pass was executed on a pass-through benchmark (where we measure max throughput), things looked solid.
Despite increased number of iterations, we would not wait more often per iteration. What that means, is that our jobs were short enough for them to finish prior to Ruby returning to the wait loop.
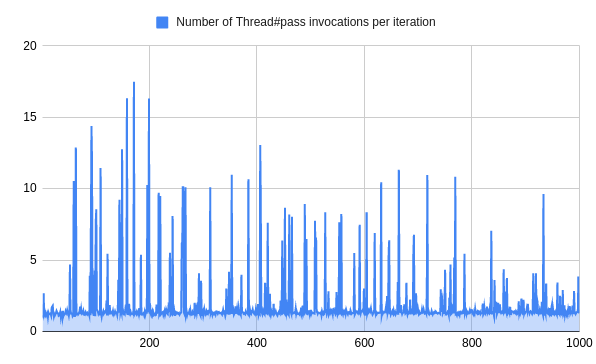
Things become much more interesting if we assume that our jobs take more time than Ruby gives them before thread execution is interrupted. Then things start to look differently:
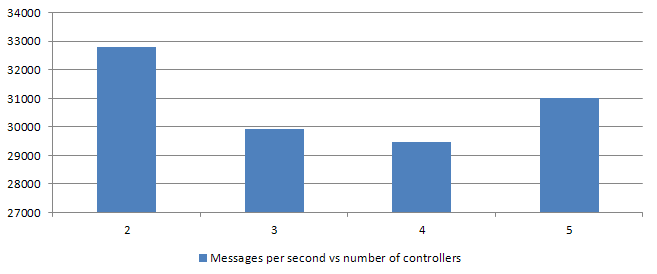
# Same code as before but the job has a bit of sleep simulating IO
task = ->(data) { sleep(rand(9..11) / 10000.0) }Assuming we burn around 1ms per job, the number of passes skyrockets:
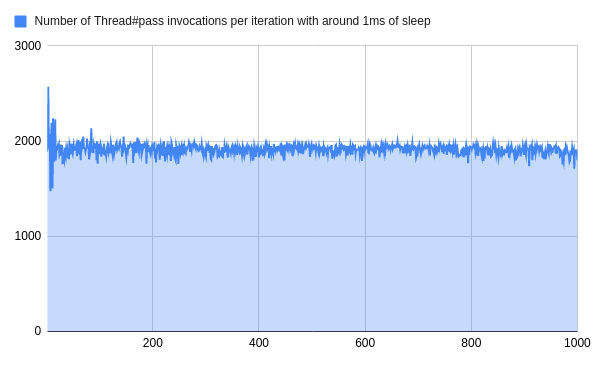
That's over 1000 times more invocations of the same method!
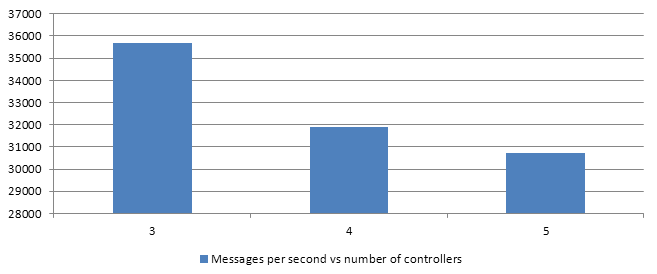
In a case, where we would run heavy queries of around 100ms (+/- 10%) per job, we end up with following results per iteration:
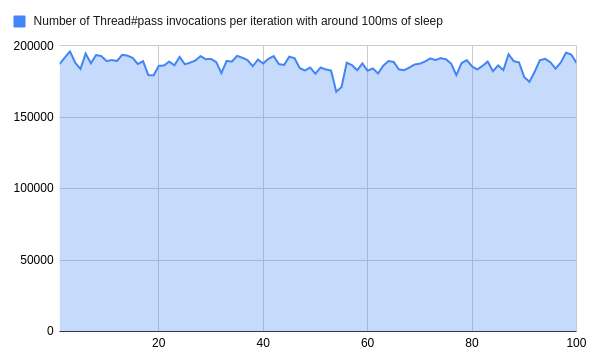
That means, that Ruby had to run #Thread#pass over 180 000 times on average for nothing!
When optimizing any code, it is good to establish the primary use case for its usage. In the case of Karafka, while raw throughput is important, it is more about complex jobs being able to use the GVL release strategy to allow parallel work execution upon IO.
So, is there a better way to make Ruby wait patiently on all the jobs to be done? There is: Queue#pop. Since it is thread-safe, we can use it to notify the main thread that the given job has finished. It won't eliminate useless runs, but it will reduce them so much that they, in fact, will become insignificant. Since we know how many jobs we've enqueued, we know how many times we need to #pop:
queue = Queue.new
lock = Queue.new
THREADS = 10
THREADS.times do |i|
Thread.new do
loop do
data, task = queue.pop
task.call(data)
lock << true
end
end
end
def wait_for_jobs_to_finish(dispatched, lock)
dispatched.times { lock.pop }
end
def data
Array.new(10) { rand }
end
task = ->(data) { data * 2 }
100_000.times do
data.each { queue << [_1, task] }
wait_for_jobs_to_finish(data.size, lock)
endThe lock.pop will stop the execution of the main thread until each job is done. This means that we increase the number of stops with an increased number of threads. However, this correlation is linear and the end result is orders of magnitude smaller than when using Thread.pass.
Here's the same benchmark with a number of Queue#pop calls that replaced Thread#pass for non-sleep case:
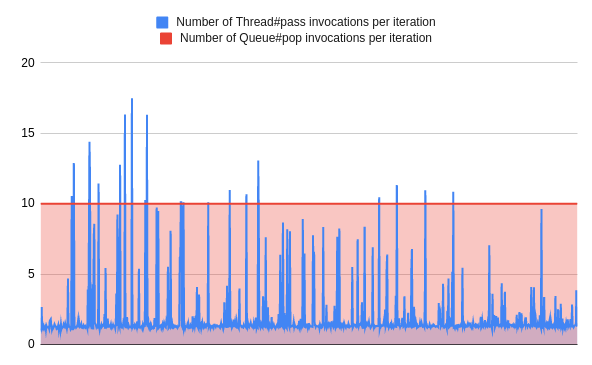
The number of Queue#pop invocations equals the thread number. It is independent of jobs types or any other circumstances. So the longer jobs are, the bigger the improvement:
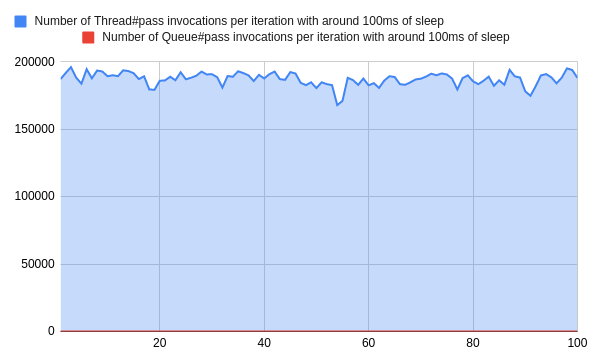
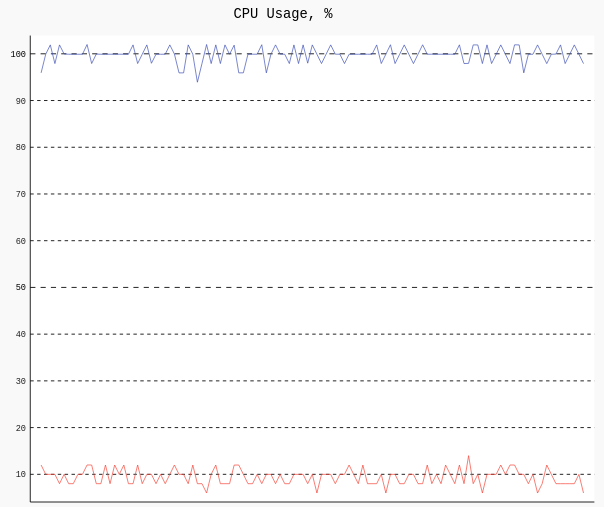
This change not only reduced the number of calls by over 99.994% but it also drastically lowered CPU utilization, which is visible especially for cases with extensive IO (here simulated with sleep):
Summary
So, is one better than the other? No. They should be used in different cases and to achieve different goals.
Thread#pass should not be used to defer work but rather to provide a hint to Ruby, that there may be more important things that it could focus on.
Queue#pop on the other hand can act not only as a component of a queue but also as a part of multi-threaded applications flow control.
Concurrency is not easy. Thread management and selection of proper methods are as crucial as understanding your primary use-cases and building correct benchmarks. Sometimes minor tweaks can provide tremendous benefits.
Note: this post would not be possible without extensive help from Samuel Williams. Thank you!
Cover photo by Chris-Håvard Berge on Attribution-NonCommercial 2.0 Generic (CC BY-NC 2.0) . Image has been cropped.