Table of Contents
RubyKaigi 2018 has ended, but the excitement is still fresh. After 25 hours in planes, trains, buses, and cabs we’re finally home. I guess it’s a good time to summarize and review 4 days on the best Ruby conference in the world.
Castle.io support
First of all, I would like to express special thanks to Castle.io for backing me up, providing me possibility to go to RubyKaigi and for their ongoing Karafka support. Wouldn't happen without them.

What is RubyKaigi?
I’ll let RubyKaigi speak for itself:
RubyKaigi is the authoritative international conference on the Ruby programming language, attracting Ruby committers and Ruby programmers from around the world to Japan, the birthplace of Ruby. Held nearly every year since 2006, RubyKaigi is a truly international event.
RubyKaigi is the most prestigious Ruby conference in the world. It is probably the only conference where you can meet all the core Ruby team members at the same time. It's also one of few conferences, if not the only one, that is in both Japanese and English simultaneously.
What is amazing about this conference is the fact that despite being hosted in Japan, English is not a second-class citizen. In fact, a majority of talks had slides in English, and during Japanese presentations, there was always a real-time translation available.
RubyKaigi gathers people from all around the world, creating a great place for exchanging experience and spreading new ideas. It's also an amazing place if you want to meet some (really a lot!) new people and recharge your Ruby batteries for at least a year.
This year's RubyKaigi was hosted in Sendai.
Traveling to Japan
Traveling to Japan from Poland is not that hard. There's a direct flight from Warsaw to Tokyo Narita Airport. It takes roughly 10 hours and 30 minutes. Sounds great as long as you're from Warsaw. Unfortunately, I live and work in Cracow. This and the fact, that Narita airport is located far away from the Tokyo city center, makes the whole journey a bit longer. It took us almost 24 hours to get from our apartment in Cracow to our hotel in Tokyo. Still not that bad for a 8658-kilometer distance.
Visiting Asakusa.rb
We've arrived in Japan a couple days before the conference. That was a great opportunity to visit Asakusa.rb, one of the most active and probably the most important Japanese local Ruby group. It's named after Asakusa - the district in Taitō that is famous for the Sensō-ji, a Buddhist temple dedicated to the bodhisattva Kannon.

Asakusa.rb about themself:
Asakusa.rb is probably the most active regional Rubyist group in Japan. We're having weekly meetup on every '''Ruby Tuesday''' somewhere in Tokyo.
If you have a chance to spend a day on Tuesday in Tokyo, come and join our meetup (or drink up)! We're always welcoming foreign guests :)
And to be honest, it's hard not to agree with that. They meet quite frequently, so if by any chance you end up in Tokyo, don't forget to visit them for a little hackathon.

Arriving in Sendai
Sendai is the capital city of Miyagi Prefecture, the largest city in the Tōhoku region, and the second-largest city north of Tokyo. Getting there from the Tokyo Station is straightforward and easy. All you have to do is take an Akita or Tohoku Shinkansen (bullet train). It takes less than two hours.
The city of Sendai is clean, big and friendly :) The only downside is the fact that the exchange rates for buying JPY with USD are much lower than in Tokyo (between 10 and 15 percent).




About the conference
Looking at how the conference was organized, hosted and managed by Akira Matsuda and the rest of the organizers, I can only say one thing: amazing job! It's really hard to point any flaws in the organization and the way everything happened.
I feel that I should also praise the Japanese-English translators. They did amazing job, especially since it was a very technical conference. The only moment one of them got confused was during the TRICK, but it was understandable. Almost everyone got confused in a way during this part of the conference.






I can really complain only on one thing: inaccurate location descriptions in English. Every party was hosted somewhere else, and the English descriptions and/or addresses of the places were either incomplete or incorrect. It could be a problem for anyone who does not know Japanese and has to rely on Google Maps. Surprisingly, there were even differences in the English and Japanese addresses for some of the locations.
However, in the end, I was able to get to each of the parties (sometimes with a bit of delay), so let's say it was just an eliminating challenge ;).
Day 1 Speeches
Matz’s keynote
The conference was opened by no one else than Matz himself. To be honest, no one knew what he is going to talk about, as his topic was "TBD" till the last moment.
He talked about one of the hardest problems in programming, naming. He admitted that the yield_self name was not exactly as it should be, and that instead of saying what it does, it described how it does it. He also announced that he accepted the then alias name for this method.
He also touched a couple of other "future Ruby" topics like Guilds and JIT but without any technical details.
His talk was the least technical one that I attended during the whole conference, but overall it was interesting. He even admitted that his talk is not going to be technical, because when he starts talking technical stuff people either get bored or they don't understand what he's talking about. I guess many of us are still not there ;).
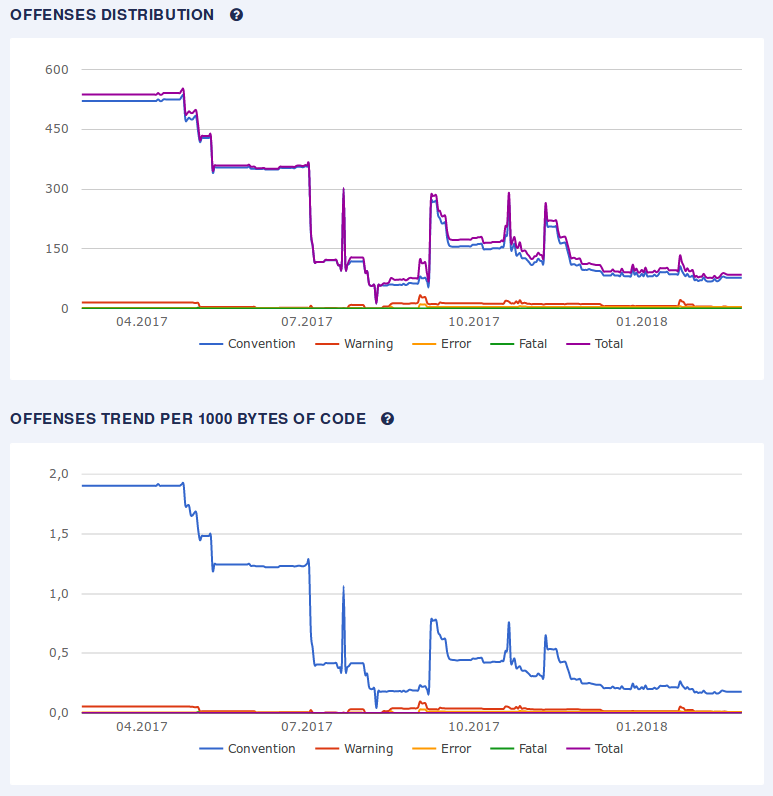
Karafka - Ruby Framework for Event Driven Architecture
Since it was my talk, it's not for me to judge. All I can say is that I had a lot of fun preparing and presenting this subject to the Ruby community. 40 minutes is definitely not enough to cover the complexity of Karafka, but I hope that the other attendees got at least a general overview of what this piece of software can do for them and how can it help them process a lot of data.

You can get the slides from my talk by clicking on the image below.

All about RuboCop
If you do Ruby for a living, there's a high probability that you know RuboCop. But what you may not be aware of is how it all began, how it evolved and where it will go in the future. BBatsov covered pretty much everything non-technical that you could be interested in reference to this awesome tool, as well as some technical details like deciding on a cross-platform parser and solving many problems in RuboCop development.

Day 2 Speeches
Guild prototype
If this were the only talk at this conference, I would still have come to Sendai. At least this is how I felt before the talk. I had high hopes about this topic and I (still) see guilds as one of the most important (if not the most important) components that will move the Ruby language and its community forward. I expected to get a lot of technical details on managing guilds from Koichi Sasada, plus some implementation details. Did I get what I expected? Well, not exactly...
After the talk I had mixed feelings, mostly because Koichi-san repeated many things that we already knew from his previous presentations. Although this is understandable as not everyone is into guilds as I am, I still was not satisfied. We've received only a glimpse of the whole API, some code examples and (really promising) benchmarks. That was good, but I feel that the earlier the API (an imperfect one, without full implementation) betcomes public, the faster the Ruby core team will get a feedback on it.
One thing that saved all of this was the Guilds initial source code release, right after the conference. I hope, that thanks to this initial code release, things get faster now.

You can download Koichi-san's presentation by clicking on the image below:

Firmware programming with mruby/c
In my humble opinion, this was the best talk during the whole RubyKaigi 2018.
Hasumi's talk included everything I love about Ruby and more:
- Ruby and more Ruby;
- mRuby/c that is not well known and not often used in Europe;
- Non-standard business use case that was super interesting (sake brewery);
- Hardware and how to interact from within mRuby with it;
- IoT;
- Sake.
All of it was wrapped in a really acceptable form with a newbie introduction to the subject. It was really easy to keep track with all the things he was talking about, even despite the fact, that it was in Japanese and some things could be distorted during the translation. He was also able to prove, that the ventilation at the venue was really good due to CO2 sensors running with Ruby!
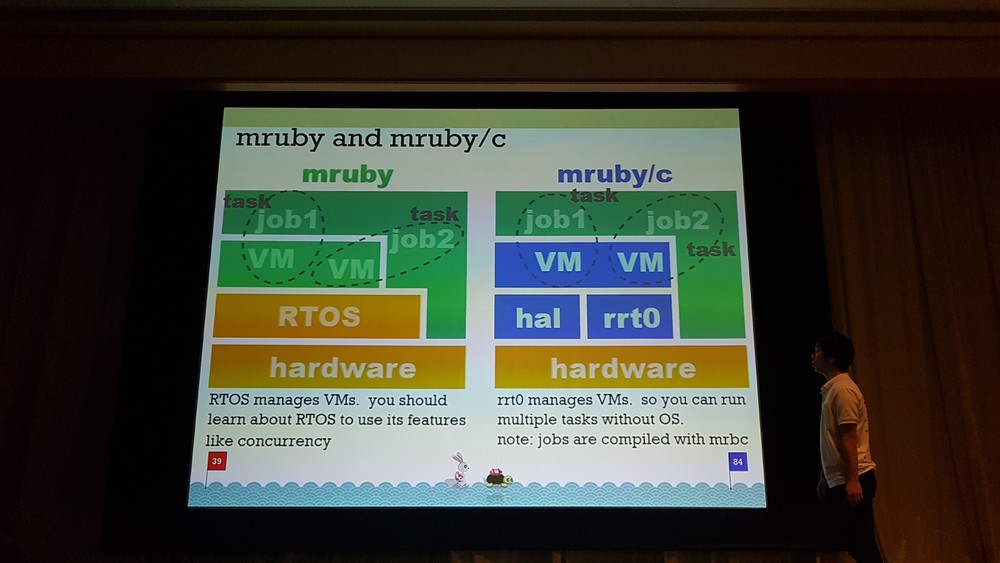
You can download Hasumi Hitoshi's great presentation by clicking on the image below:

RubyData Workshop (1) Data Science in Ruby
It's always really interesting to see how Ruby is being used in this area. The workshop focused on introducing the audience to some of the data science libraries available for Ruby and going through example sets of data and trying to get some valuable information out of them.
Too bad that the second part was in Japanese. :)
Day 3 Speeches
Parallel and Thread-Safe Ruby at High-Speed with TruffleRuby
TruffleRuby is one of the most interesting projects in the Ruby world at the moment. It's not just a new version of JRuby, it's a high performance implementation of the Ruby programming language built on GraalVM with Oracle support. TruffleRuby aims to run not only the Ruby code fast, but also do that with support for all the native C libraries. This means that once finished, it should be interchangeable with cRuby.
Benoit Daloze's keynote was about bringing more concurrency into Ruby world. Really good, technical talk with a lot of low-level details you won't find anywhere else.
The Method JIT Compiler for Ruby 2.
K0kubun-san's work is always exceptional. His talk was about the second most important (in my opinion) thing that is being currently developed by Ruby core team: YARV-MJIT. The talk included a short introduction and not-so-short technical part during which we all went together through how things are being constructed during the JITing process. It's really hard to summarize this type of talk, without having to write a whole separate article on that matter, so hopefully the presentation and the video recording will be soon available.
The most interesting part for me, was the part about getting rid of C and being able to achieve better performance with Ruby than with C. Remarkable magic it is!

High Performance GPU computing with Ruby
GPU computing with Ruby? Well yes! The talk was about the ArrayFire-rb. It's a library that can be used for high-performance computing in Ruby like statistical analysis of big data, image processing, linear algebra, machine learning, and more.
Good introduction to the subject with a bit of algebra and statistics here and there.

TRICK 2018 (FINAL)
TRICK (Transcendental Ruby Imbroglio Contest for RubyKaigi) is just something else. It's really hard to describe what it really is, but as a big simplification you can say that TRICK is the abstract painting using Ruby language as a brush. The goal of this contest is to create a small and eloquent Ruby program that will illustrate in an abstract way abilities of Ruby language.
This year's TRICK was the biggest, and by looking at the previous editions, I can clearly say that the most crazy. Many were following the patterns that you could see in the previous years. That is creating some obfuscated libraries that would build animations or render 3D models but the winning code really stood out! Being able to create a working Ruby code just from the reserved keywords is not only mind-blowing, is just... something else.

Before parties, parties, after parties and after-after parties - Omotenashi
Ruby is not just a language. It is also a community of super friendly, open-minded people that share the same passion. The same can be said about this conference. It's not only a conference, but it is also a place for exchanging ideas and concepts. And is there a better way to do that than over a bit of sake? I think not.
Every single conference day had a party. There was a party for some of us before the conference and an after party after the after party as well ;)
This part of each conference is, for me, as important as the talks. Being able to ask speakers about their work and hobbies and to discuss various Ruby-related matters with the best Ruby programmers in the world is always a pleasure. So many great conversations happened during these days...
Here, I must send a shout out to Hiroshi Shibata, Akira Matsuda, Joker007, Satoshi "moris" Tagomori and the rest of the Asakusa.rb members for taking such a good care of me and making me feel like one of them :-) It was amazing experience, and as I mentioned already, you are always welcome in Cracow!





Summary
RubyKaigi is really special: A purely technical conference with an extreme Ruby focus.
Technical stuff and technical discussions is what drives me, and the only problem that I had is that the conference was multi-track. I was unable to attend all of the talks and making a choice was almost impossible :(.
I can recommend this conference to any Ruby and Japan fan. Whether you're a beginner or a pro, you will definitely find something for yourself during presentations, workshops and the parties.