As an open-source developer, I constantly seek performance gains in the code I maintain. Since I took over rdkafka from AppSignal in November 2023, I promised not only to maintain the gem but to provide a stream of feature improvements and performance enhancements. One key area where performance can often be improved is how synchronization is handled in synchronous operations. This article discusses our significant improvement in rdkafka by replacing sleep with condition variables and mutexes.
rdkafka-ruby (rdkafka for short) is a low-level driver used within the Karafka ecosystem to communicate with Kafka.
It is worth pointing out that while I did the POC, Tomasz Pajor completed the final implementation, and I'm describing it here because Tomasz does not run a blog.
The Problem with Sleep in Synchronous Operations
In synchronous operations, especially those involving waiting for a condition to be met, the use of sleep to periodically check the status is common but problematic. While simple to implement, this approach introduces inefficiencies and can significantly degrade performance.
How Sleep Was Used in rdkafka
Such an approach was taken in rdkafka-ruby when dealing with callbacks for many operations. Whether dispatching messages, creating new topics, or getting configuration details, any wait request would sleep for a certain period, periodically rechecking whether the given operation was done. This meant that operations that could be completed in a few milliseconds were delayed by the fixed sleep duration.
Additionally, librdkafka, the underlying library used by rdkafka, is inherently asynchronous. Operations are dispatched to an internal thread that triggers a callback upon completion or error. This asynchronous nature requires some form of synchronization to ensure the main thread can handle these callbacks correctly. The sleep-based approach for synchronization added unnecessary delays and inefficiencies.
Below is a simplified diagram of synchronous message production before the change.
Why Sleep is Inefficient
Using sleep for status checking in synchronous operations has several significant drawbacks:
Latency: A fixed sleep interval means the actual waiting time is at least as long as the sleep duration, even if the condition is met sooner.
Resource Wastage: CPU cycles are wasted during sleep since the thread is inactive and does not contribute to the task's progress.
Imprecise Timing: Threads might wake up slightly later than the specified interval, leading to additional delays.
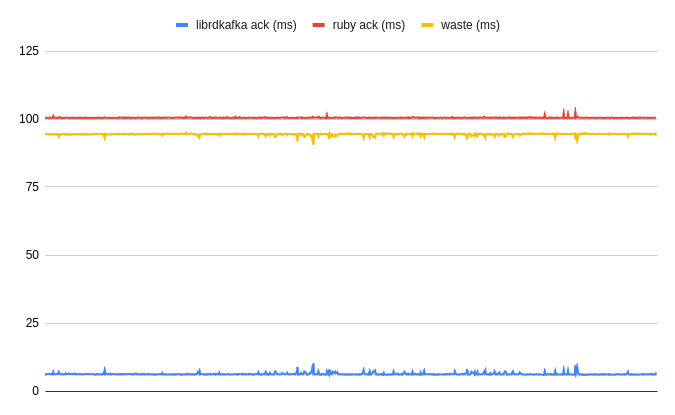
In rdkafka, the default sleep duration was set to 100ms. This means that any #wait operation would take at least 100ms, even if the task only required a few milliseconds. This unnecessary wait time accumulates, leading to significant performance degradation.
While such a lag was insignificant in the case of one-time operations like topic creation, it was problematic for anyone using sync messages dispatch. The overhead of sleeping for an extensive period was significant. The faster the cluster worked, the bigger the loss would be.
I asked Tomasz Pajor, who wanted to do something interesting in the Karafka ecosystem, to replace it with a condition-variable-based setup.
Validating Assumptions
To ensure that the new approach would yield gains, I measured the difference in time when librdkafka announced successful delivery against when this information was available in Ruby. This validation confirmed that the new synchronization method could provide a major performance boost.
*Time from the message dispatch to the moment the given component is aware of its successful delivery, plus waste time (pointless wait). Less is better.
Ruby would "wait" an additional 94 milliseconds on average before acknowledging a given message delivery! This meant there was a theoretical potential to improve this by over 93% per dispatch, ideally getting as close to librdkafka delivery awareness as possible.
The Role of Condition Variables and Mutexes
Before we explore the implementation's roots and some performance benchmarks, let's establish the knowledge baseline. While most of you may be familiar with mutexes, condition variables are only occasionally used in Ruby daily.
Mutexes
A mutex (short for mutual exclusion) is a synchronization primitive that controls access to a shared resource. It ensures that only one thread can access the resource at a time, preventing race conditions.
Condition Variables
A condition variable is a synchronization primitive that allows threads to wait until a particular condition is true. It works with a mutex to avoid the "busy-wait" problem seen with sleep.
Below is a simple example demonstrating the use of condition variables in Ruby. One thread waits for a condition to be met, while another thread simulates some work, sets the condition to true, and signals the waiting thread to proceed.
mutex = Mutex.new
condition = ConditionVariable.new
ready = false
# Thread that waits for the condition to be true
waiting_thread = Thread.new do
mutex.synchronize do
puts "Waiting for the condition..."
condition.wait(mutex) until ready
puts "Condition met! Proceeding..."
end
end
# Thread that sets the condition to true
signaling_thread = Thread.new do
sleep(1) # Simulate some work
mutex.synchronize do
puts "Signaling the condition..."
ready = true
condition.signal
end
end
waiting_thread.join
signaling_thread.join
Spurious Wakeups
When using condition variables, it is essential to handle spurious wakeups. A spurious wakeup is when a thread waiting on a condition variable is awakened without being explicitly notified. This can happen for various reasons, such as system-level interruptions or other factors beyond the application's control.
The condition should always be checked in a loop to handle spurious wakeups. This ensures that even if the thread wakes up unexpectedly, it will recheck the condition and go back to waiting if it is not met. Here's an example:
@mutex.synchronize do
loop do
if condition_met?
# Proceed with the task
break
else
@resource.wait(@mutex)
end
end
end
This loop ensures that the thread only proceeds when the actual condition is met, thus safeguarding against spurious wakeups.
Implementing Condition Variables in rdkafka
To address the inefficiencies caused by sleep, Tomasz replaced it with a combination of condition variables and mutexes. This change allows threads to wait more efficiently for conditions to be met.
Here's a simplified version of the wait code that replaced sleep with condition variables and mutexes:
def wait(max_wait_timeout: 60, raise_response_error: true)
timeout = max_wait_timeout ? monotonic_now + max_wait_timeout : MAX_WAIT_TIMEOUT_FOREVER
@mutex.synchronize do
loop do
if pending?
to_wait = (timeout - monotonic_now)
if to_wait.positive?
@resource.wait(@mutex, to_wait)
else
raise WaitTimeoutError.new(
"Waiting for #{operation_name} timed out after #{max_wait_timeout} seconds"
)
end
elsif self[:response] != 0 && raise_response_error
raise_error
else
return create_result
end
end
end
end
def unlock
@mutex.synchronize do
self[:pending] = false
@resource.broadcast
end
end
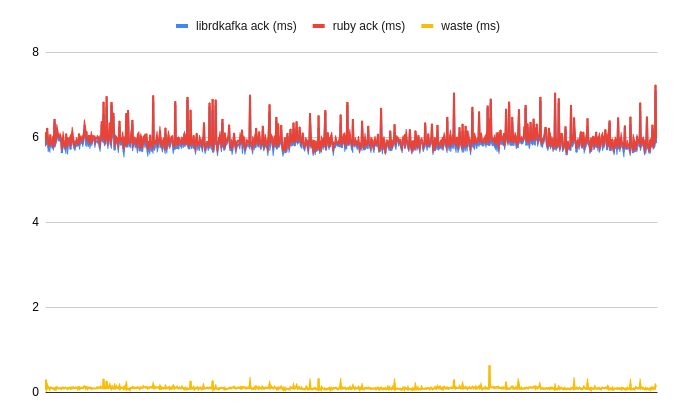
The moment librdkafka would trigger delivery callback, condition variable #broadcast would unlock the wait, effectively reducing the wait waste from around 93ms down to 0,07ms! That's a whooping 1328 times less!
Performance and Efficiency Gains
By using condition variables and mutexes, we observed a significant improvement in performance and efficiency:
Reduced Latency: Threads wake up as soon as the condition is met, eliminating the unnecessary wait time introduced by sleep.
Better Resource Utilization: The CPU is not idling during the waits, allowing for more efficient use of processing power.
More Predictable Timing: The precise control over thread waking improves the predictability and reliability of synchronous operations.
The performance gains are substantial on a fast cluster. For instance, with queue.buffering.max.ms set to 5ms (default) and an acknowledgment (ack) of 1 or 2, Kafka can dispatch messages in 6-7ms. Using a 100ms sleep means waiting an additional 94ms, leading to a total wait time of 100ms for operations that could have been completed in 5-6ms.
The improvement is also significant in the case of WaterDrop, which had the sleep value set to 10ms. On a fast cluster with the same settings, a 10ms sleep would still cause a delay for operations that could be completed in 5ms, effectively doubling the wait time.
*Time from the message dispatch to the moment the given component is aware of its successful delivery, plus waste time (pointless wait). Less is better.
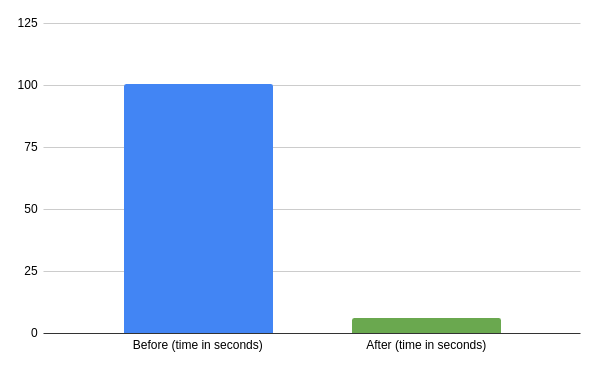
The change is so significant that putting it on a chart is hard. The time needed to dispatch 1000 messages synchronously is now over 16 times shorter!
*Time needed to dispatch 1000 messages synchronously before and after the change. Less is better.
Implications for Ruby's Scheduler
Ruby's scheduler also benefits from the removal of short sleep intervals. The Ruby scheduler typically schedules thread work in 100ms increments. Short sleeps disrupt this scheduling, leading to inefficient thread management and potential context-switching overhead. The scheduler can manage threads more effectively using condition variables and mutexes, reducing the need for frequent context switches and improving overall application performance.
Rdkafka and WaterDrop Synchronicity Remarks
Karafka components and the design of librdkafka heavily emphasize asynchronous operations. These operations are the recommended approach for most tasks, offering superior performance and resource utilization. However, it's important to address synchronous operations. Their efficient handling is crucial, particularly for specific use cases like transactions.
This improvement in rdkafka enhances the performance of synchronous operations, making them more efficient and reliable. It is important to recognize users' diverse use cases, including those who prefer synchronous operations for their specific needs.
Conclusions
Replacing sleep with condition variables and mutexes in rdkafka significantly enhanced its performance. This approach eliminates unnecessary wait times, optimizes resource usage, and aligns better with Ruby's scheduling model. These improvements translate to a more efficient and responsive application, especially in high-performance environments where every millisecond counts.
By adopting this change, rdkafka can better handle high-volume synchronous operations, ensuring that threads wait only as long as necessary and wake up immediately when the required condition is met. This not only improves performance but also enhances the overall robustness of the system.
The journey towards efficient parallelization in library development has often been based on using threads. As Karafka celebrates its eighth anniversary, it's become clear that while threads have served us well for many tasks, there's room to explore further. That's why I've decided to introduce forking capabilities into Karafka, aiming to offer another dimension of parallelization to its users. This move isn't about replacing threads but about providing options to cover a broader spectrum of use cases than before.
For those who wonder what Karafka is, Karafka is a Ruby and Rails multi-threaded efficient Kafka processing framework designed for building efficient and scalable message processing applications.
Objectives and Scope
This article isn't a deep dive into every aspect of Ruby's parallelism and concurrency. Instead, it's focused on illustrating how forking, as a specific capability, can be woven into the fabric of Ruby applications, with Karafka as our case study. The goal is to outline what it takes to integrate forking effectively - ensuring it's stable, robust, and ready for production environments.
While forking offers potent possibilities for the performance and scalability of Ruby applications, it comes with its challenges. This topic easily deserves a whole chapter in a book about Ruby; hence, please remember that I picked only the most relevant things in this article to paint a general picture of the subject.
Acknowledgements
A special thank you goes out to KJ Tsanaktsidis, a member of the Ruby core team. His deep knowledge, insights, and willingness to help have been invaluable as I navigated the complexities of adding forking capabilities to Karafka. His help is living proof of the spirit of MINASWAN.
Concurrency and Parallelism in Ruby
Before we dive deeper into Karafka Swarm details and code-base, here is a short introduction to Ruby concurrency for all the people not deeply involved in any of those matters.
Ruby's model for handling parallelism and concurrency is robust, offering developers multiple ways to execute tasks simultaneously or concurrently. It can, however, also be challenging. This flexibility is critical to optimizing application performance and efficiency. Among the tools Ruby provides are processes, threads, and fibers, each with distinct characteristics and use cases. Additionally, Ruby has introduced more advanced features like auto-fibers and a fiber scheduler to enhance concurrency management further.
Note: Ractors were skipped as they are not entirely usable at the moment.
Processes
Processes in Ruby are separate instances of running programs, each with its own allocated memory space. This isolation guarantees that processes do not interfere with each other, making them a reliable choice for parallel tasks. However, this comes at a higher cost of resource usage than threads and fibers.
# Fork a new process
child_pid = fork do
# This block is executed in the child process
puts "Child Process: PID=#{Process.pid}"
# Child process does some work
sleep 1 # Simulate some work by sleeping for 1 second
end
# This code is executed only in the parent process
puts "Parent Process: PID=#{Process.pid}, Child PID=#{child_pid}"
# The parent process waits for the child process to exit
Process.wait(child_pid)
puts "Child process #{child_pid} has finished."
Threads
Threads offer a way to perform concurrent operations within the same application instance, sharing the same memory space. While this makes data exchange between threads straightforward, it also introduces the need for careful synchronization to prevent issues like race conditions. Threads in Ruby are subject to the Global Interpreter Lock (GIL), which we'll discuss next.
# An array to hold the threads
threads = []
# Create 5 threads
5.times do |i|
threads << Thread.new do
sleep_time = rand(1..3)
puts "Thread #{i+1}: Sleeping for #{sleep_time} seconds..."
sleep(sleep_time)
puts "Thread #{i+1}: Woke up!"
end
end
# Wait for all threads to complete
threads.each(&:join)
puts "All threads have completed."
Fibers, Auto-Fibers, and Fiber Scheduler
Fibers are lightweight programming constructs that allow for more granular control over program execution. They enable cooperative multitasking within a single thread, where the developer manually controls when a fiber is paused or resumed. This provides a flexible way to handle tasks that can be interrupted or need to yield control frequently.
# Define a fiber to print numbers
numbers_fiber = Fiber.new do
(1..3).each do |number|
puts "Number: #{number}"
Fiber.yield
end
end
# Define a fiber to print letters
letters_fiber = Fiber.new do
('A'..'C').each do |letter|
puts "Letter: #{letter}"
Fiber.yield
end
end
# Alternate between the two fibers
while numbers_fiber.alive? || letters_fiber.alive?
numbers_fiber.resume
letters_fiber.resume
end
puts "Both fibers have finished their execution."
Ruby has introduced auto-fibers and the fiber scheduler, building on the concept of fibers. Auto-fibers automate the management of fibers, enabling asynchronous execution patterns that are simpler to implement and reason about. This is particularly useful for non-blocking I/O operations, where the Ruby runtime can automatically switch contexts instead of blocking the current thread, improving overall application throughput.
The fiber scheduler complements auto-fibers by providing a hook into Ruby's event loop, allowing developers to define custom scheduling logic. This is a powerful feature for those who need to integrate with external event loops or optimize their concurrency model for specific performance characteristics. Together, auto-fibers and the fiber scheduler significantly enhance Ruby's concurrency toolkit, offering developers sophisticated mechanisms for writing efficient, non-blocking code.
GIL (Global Interpreter Lock)
The GIL is a mechanism in Ruby designed to prevent multiple threads from executing Ruby code simultaneously, thereby protecting against concurrent access to Ruby's internal structures. While it simplifies thread safety, the GIL can limit the effectiveness of multi-threaded programs on multi-core processors, particularly for CPU-bound tasks. However, for I/O-bound tasks, Ruby threads can still offer significant performance improvements.
Below, you can find a simple example that attempts to perform CPU-bound operations using threads. The GIL ensures that only one thread can execute Ruby code at a time, which means CPU-bound operations won't see a significant performance improvement when run in parallel threads, unlike I/O-bound operations.
require 'benchmark'
def fib(n)
n <= 2 ? 1 : fib(n - 1) + fib(n - 2)
end
# Measure the execution time of two threads performing CPU-bound tasks
execution_time = Benchmark.measure do
thread1 = Thread.new { fib(35) }
thread2 = Thread.new { fib(35) }
thread1.join
thread2.join
end
puts "Execution time with GIL: #{execution_time.real} seconds"
Multi-Process Communication API selection
To support a swarm of processes, one must figure out how they can be controlled and managed. Managing processes and ensuring their smooth operation in the Linux ecosystem is fundamental to system administration and application development. However, traditional process management relies heavily on process identifiers (PIDs) and has limitations and challenges. One such challenge is PID reuse, where after a process terminates, its PID can be reassigned to a new process. This behavior can lead to issues where actions intended for one process mistakenly affect another. To address these concerns and enhance process management capabilities, Linux introduced the concept of pidfd.
What is pidfd?
pidfd stands for PID file descriptor. A mechanism introduced in Linux 5.3 provides a more stable and reliable way to reference and manage processes. Unlike traditional PIDs, which the system can reuse, a pidfd is a unique file descriptor for a specific process instance. This means that as long as you hold the pidfd, it uniquely identifies the process, eliminating the risks associated with PID reuse.
The introduction of pidfd was motivated by the need to safely manage long-lived processes and perform operations without the risk of affecting unintended processes due to PID reuse. This is especially important in environments with high process churn, where PIDs can quickly be recycled.
The Problem with PIDs
Before pidfd, processes were managed and signaled using their PIDs. However, due to the finite and recyclable nature of PIDs, two major issues arose:
PID Reuse: Once a process exits, its PID can be reassigned to a new process. A program storing PIDs for later use could mistakenly signal a completely unrelated process.
Race Conditions: When a PID is checked and an action is taken (like sending a signal), the original process could terminate and the PID reassigned, leading to unintended consequences.
These issues necessitated a more stable reference to processes, leading to the development of pidfd.
Below is a theoretical case demonstrating how a Ruby script uses signals to communicate with processes identified by PIDs. This example highlights the risks associated with PID reuse and race conditions, where a signal intended for a specific process might inadvertently affect another process if the original PID has been reassigned.
# Fork a new process
child_pid = fork do
# Child process will sleep for 5 seconds
sleep 5
end
# Parent process waits for a moment to ensure the child process starts
sleep 1
# Send a "SIGUSR1" signal to the child process
puts "Sending SIGUSR1 to child process #{child_pid}"
Process.kill("SIGUSR1", child_pid)
# Wait for the child process to exit
Process.wait(child_pid)
# Now let's simulate PID reuse by forking another process that might reuse the same PID
another_child_pid = fork do
# This process does something else
sleep 5
end
# Assuming the original child PID got reused (simulating PID reuse)
# Here we try to signal the original child process again, not knowing it's a different process now
puts "Attempting to send SIGUSR1 to original child PID (now potentially reused): #{child_pid}"
begin
Process.kill("SIGUSR1", child_pid)
rescue Errno::ESRCH
puts "Process with PID #{child_pid} does not exist anymore."
end
Ruby and PidFd
Ruby's process management capabilities, while robust, traditionally revolve around PIDs. Ruby allows sending signals to processes using their PIDs but does not provide built-in APIs for pidfd operations. This gap means that Ruby applications can only directly leverage the benefits of pidfd with additional mechanisms.
I implemented a pidfd layer using Ruby's Foreign Function Interface (FFI) to bridge this gap. FFI is a way to call C functions and use C data structures from Ruby, enabling direct interaction with the lower-level system APIs that support pidfd. This implementation was an exciting challenge, as I don't often need to dive deep into Linux's signal tables and syscalls.
This implementation will receive its own blog post, and for now, all you need to know about it is the fact that Karafka ships with a relatively simple API comprised of only three methods and an initializer:
pid = fork { sleep }
# Fetch from Linux the pidfd of the child (can be any other process)
pidfd = Karafka::Swarm::Pidfd.new(pid)
# Check if given process is alive
pidfd.alive? #=> true
# Kill it
pidfd.signal('TERM')
# Collect it so there is no zombie process
pidfd.cleanup
# Check again and see that it is dead
pidfd.alive? #=> false
Karafka Swarm: A Perfect Match for Scalability
In my experience with Karafka, it's clear that while most user workloads are I/O-bound, involving operations like DB storage or cache updates, a significant portion - about 20% - are CPU-intensive. These tasks, involving heavy deserialization and computations, didn't fit with Karafka's multi-threaded model, which is more suited for I/O-bound tasks. Users often had to run multiple independent processes for CPU-heavy workloads, leading to unnecessary memory overhead. Recognizing this inefficiency, I decided to do something with it.
Swarm Architecture
When starting a project like this one, it is good to have an initial idea of what you want to achieve. Karafka is a critical component of many businesses, so the solution had to be robust and stable. Here are a few of the things that need to be taken into consideration when deciding on the architecture of such a solution:
Supervision Model
Zombie Processes
Orphaned Processes
Shutdown Procedure
Processes Communication
Memory Management
Load Balancing
Errors Handling
Signals Handling
Resources Cleanup
I've decided to pick an architecture that centers around a supervisor-worker model. At its core, the supervisor acts as the central command, orchestrating the execution of child node workers. These workers are responsible for parallel processing messages from Kafka topics, each operating in its own process space.
This design allows for a scalable and fault-tolerant system where the supervisor monitors and manages worker processes, ensuring that they perform optimally and restart them as necessary. By isolating work to individual processes, Swarm mitigates the risk of a single point of failure, enhancing the reliability of the application.
Challenges with Forking and librdkafka
Karafka relies under the hood on librdkafka - a C library implementation of the Apache Kafka protocol. A significant challenge in implementing the Swarm architecture is the inherent limitations of librdkafka regarding forking. librdkafka is not fork-safe. This limitation necessitates careful management of how and when processes are forked and how librdkafka is initialized and used within these processes.
To navigate these challenges, I decided to ensure that librdkafka instances are never pre-fork present. This involved initializing librdkafka only within the child processes after a fork, ensuring that no librdkafka objects or handles are shared across process boundaries. This approach maintains the integrity of the message processing pipeline, ensuring data consistency and system reliability.
Below, you can see an example code and how it behaves when rdkafka-ruby (the C binding layer that I also maintain) producer is being used from forks:
producer = Rdkafka::Config.new('bootstrap.servers': 'localhost:9092').producer
producer.produce(topic: 'a', payload: 'b')
fork do
producer.produce(topic: 'a', payload: 'b')
end
Ruby VM will crash upon usage or sometimes even just presence of a librdkafka initialized entity in a fork.
Forking Strategies
That is why, initially, when I thought about adding swarm capabilities to Karafka, I thought about a relatively simple approach of forking nodes during the supervisor startup. This would save me from any resource management risk and allow me to use librdkafka from the supervisor post-fork.
However, I quickly realized this approach would not work in production in case of child-only incidents like VM crashes or critical errors. I had to develop a strategy that would allow me to control and manage processes during the whole time Karafka was supposed to run.
Supervision and Memory Leak Control
One of the challenges in managing a multi-process system is controlling memory leaks. While Karafka does not have known memory leaks, it can also integrate with applications that may have their issues. Karafka's supervisor monitors the memory usage of child processes to mitigate potential memory leaks, taking corrective action when usage patterns indicate a possible leak.
Here's the simplified code Karafka uses to monitor and report memory leaks to the supervisor. It compares the RSS with the configured max allowed, and if we go beyond it, it notifies the supervisor.
class LivenessListener
# This method is triggered every 5 seconds in each node
def on_statistics_emitted(_event)
# Skip if we are not a forked node
return unless node
# Fetch current process health status
current_status = status
# Report
current_status.positive? ? node.unhealthy(current_status) : node.healthy
end
private
def status
return 3 if rss_mb > @memory_limit
0 # This status means all good
end
def rss_mb
kb_rss = 0
IO.readlines("/proc/#{node.pid}/status").each do |line|
next unless line.start_with?('VmRSS:')
kb_rss = line.split[1].to_i
break
end
(kb_rss / 1_024.to_f).round
end
end
Processes Management
Karafka's Swarm architecture supervisor plays a critical role in managing child processes. It is responsible for monitoring the health of these processes, restarting them as needed, and ensuring that they are performing their tasks efficiently. The supervisor uses signals to communicate with child processes, managing their lifecycle from startup to shutdown.
Health checks are periodically conducted to ensure that each child's process is responsive, and messages are processed as expected. These checks are essential for maintaining the system's overall health, allowing the supervisor to take preemptive action to restart or replace workers who are not functioning correctly.
Each node is responsible for reporting its health periodically and indicating if its behavior deviates from the expected one configured by the developer.
The supervisor process uses signals to send control commands to child nodes, which allowed me to have unified control API whether using swarm or not. The child nodes use pipes to report their health status to the supervisor. This design choice leverages the strengths of both communication mechanisms appropriately for their respective tasks.
Why Pipes for Health Reporting?
Reliability and Order: Data transmitted through pipes is read in the order it was sent, ensuring accurate and consistent health monitoring.
Buffering: Pipes can buffer data, allowing child nodes to report health even when the supervisor is temporarily unable to read, preventing data loss and non-blocking operations.
Ease of Use: Ruby's abstraction over pipes simplifies their integration and use, allowing for straightforward data transmission without delving into complex IPC mechanisms.
Isolation and Safety: Separating control commands (via signals) from health data (via pipes) enhances system robustness by preventing interference between control and data flows.
Working with pipes has many benefits:
Pipes support structured and reliable communication, essential for detailed health reporting.
The buffering and non-blocking nature of pipes contribute to efficient system performance.
The ordered transmission ensures that health data integrity is maintained, aiding in precise system monitoring and decision-making.
This combination of signals for control and pipes for health reporting aligns with Karafka's design philosophy, ensuring efficient, reliable, and clear communication between the supervisor and child nodes.
Below, you can find an example of parent-child pipe-based communication.
# Create a pipe
reader, writer = IO.pipe
if fork
# Parent process
writer.close # Close the writing end in the parent, as we'll only read
puts "Parent is waiting for a message from the child..."
message_from_child = reader.read
puts "Parent received a message: #{message_from_child}"
Process.wait # Wait for the child process to exit
else
# Child process
reader.close # Close the reading end in the child, as we'll only write
sleep 1 # Simulate some work
puts "Child sending a message to the parent..."
writer.puts "Hello from your child process!"
writer.close # Close the writer to signal we're done sending
end
Since the supervisor receives reports, all it has to do is iterate over all the nodes, check them, and take appropriate actions if needed. While the whole code can be found in the Karafka repository, here's the most important part that I find rather self-descriptive:
def control
@nodes.each do |node|
if node.alive?
next if terminate_if_hanging(node)
next if stop_if_not_healthy(node)
next if stop_if_not_responding(node)
else
next if cleanup_one(node)
next if restart_after_timeout(node)
end
end
end
This code is executed in regular intervals, and each time, there is a system change to any of the child nodes. It ensures that whatever happens to any of the child nodes does not go unnoticed.
Glueing Things Together
In this article, I aimed to avoid delving into every nitty-gritty detail or pasting all the code snippets here. Instead, I focused on providing a high-level overview since the complete implementation details are readily available on GitHub for those interested in diving deeper. After integrating and refining all the necessary functionalities, I emerged with the following set of components:
Karafka::Swarm::Supervisor - Acts as the orchestrator that initiates and monitors forks through a monitoring system. It's responsible for the orderly shutdown of all processes, including itself. In the event of any node failure, it ensures the node is restarted.
Karafka::Swarm::Pidfd - This component encapsulates the Linux pidfd functionality within a Ruby wrapper, facilitating communication within the Swarm. It offers a more stable and resource-efficient alternative to traditional PID and PPID management combined with signal-based communication.
Karafka::Swarm::Node - Represents an individual forked process within the swarm, providing an API for managing forks and checking their status. While it serves slightly different purposes in the supervisor and the forked processes, its primary functions include facilitating information exchange with the supervisor and ensuring processes do not turn into zombies or become orphaned.
Karafka::Swarm::Manager - Similar to the thread manager but dedicated to managing processing nodes within the swarm. It oversees the initialization of nodes and monitors their behavior. If a node behaves unexpectedly, the manager attempts a graceful restart, escalating to forceful termination if necessary. Designed to operate within the supervisor.
Karafka::Swarm::LivenessListener - A monitoring component that periodically signals to the supervisor, ensuring it's aware that the system is responsive and not hanging. It also vigilantly checks if a node has become an orphan, terminating the process if necessary to maintain system integrity.
Overall, I think that the implementation I ended up with is quite compact and elegant, providing all the necessary components for robust and stable operations.
Future Directions
As the one behind Karafka, I often say that the framework is only about 30% complete in terms of my vision for its capabilities. I envision a vast landscape of features and improvements for this ecosystem, especially from a processing and data manipulation standpoint. Two key focus areas are the integration of ractors and the more innovative use of auto-fibers, each poised to enhance how Karafka handles data streams.
Summary
Ruby, while not the fastest language, offers a rich set of concurrency primitives that, when utilized effectively, can achieve impressive performance for both CPU and I/O-intensive tasks.
The ongoing development of my framework, alongside Ruby's evolving concurrency model, presents a promising landscape for developers aiming to achieve peak application performance. As the Ruby core team pushes the boundaries of what's possible with Ruby, I hope Karafka will be able to incorporate these advancements for the benefit of its users.