As an open-source developer, I constantly seek performance gains in the code I maintain. Since I took over rdkafka from AppSignal in November 2023, I promised not only to maintain the gem but to provide a stream of feature improvements and performance enhancements. One key area where performance can often be improved is how synchronization is handled in synchronous operations. This article discusses our significant improvement in rdkafka by replacing sleep with condition variables and mutexes.
rdkafka-ruby (rdkafka for short) is a low-level driver used within the Karafka ecosystem to communicate with Kafka.
It is worth pointing out that while I did the POC, Tomasz Pajor completed the final implementation, and I'm describing it here because Tomasz does not run a blog.
The Problem with Sleep in Synchronous Operations
In synchronous operations, especially those involving waiting for a condition to be met, the use of sleep to periodically check the status is common but problematic. While simple to implement, this approach introduces inefficiencies and can significantly degrade performance.
How Sleep Was Used in rdkafka
Such an approach was taken in rdkafka-ruby when dealing with callbacks for many operations. Whether dispatching messages, creating new topics, or getting configuration details, any wait request would sleep for a certain period, periodically rechecking whether the given operation was done. This meant that operations that could be completed in a few milliseconds were delayed by the fixed sleep duration.
Additionally, librdkafka, the underlying library used by rdkafka, is inherently asynchronous. Operations are dispatched to an internal thread that triggers a callback upon completion or error. This asynchronous nature requires some form of synchronization to ensure the main thread can handle these callbacks correctly. The sleep-based approach for synchronization added unnecessary delays and inefficiencies.
Below is a simplified diagram of synchronous message production before the change.

Why Sleep is Inefficient
Using sleep for status checking in synchronous operations has several significant drawbacks:
- Latency: A fixed sleep interval means the actual waiting time is at least as long as the sleep duration, even if the condition is met sooner.
- Resource Wastage: CPU cycles are wasted during sleep since the thread is inactive and does not contribute to the task's progress.
- Imprecise Timing: Threads might wake up slightly later than the specified interval, leading to additional delays.
In rdkafka, the default sleep duration was set to 100ms. This means that any #wait operation would take at least 100ms, even if the task only required a few milliseconds. This unnecessary wait time accumulates, leading to significant performance degradation.
While such a lag was insignificant in the case of one-time operations like topic creation, it was problematic for anyone using sync messages dispatch. The overhead of sleeping for an extensive period was significant. The faster the cluster worked, the bigger the loss would be.
I asked Tomasz Pajor, who wanted to do something interesting in the Karafka ecosystem, to replace it with a condition-variable-based setup.
Validating Assumptions
To ensure that the new approach would yield gains, I measured the difference in time when librdkafka announced successful delivery against when this information was available in Ruby. This validation confirmed that the new synchronization method could provide a major performance boost.
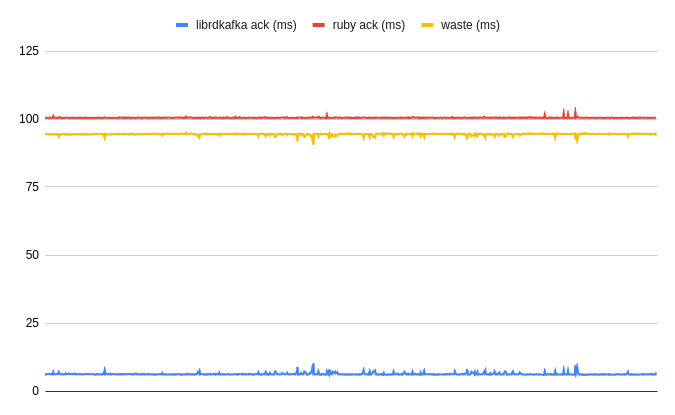
*Time from the message dispatch to the moment the given component is aware of its successful delivery, plus waste time (pointless wait). Less is better.
Ruby would "wait" an additional 94 milliseconds on average before acknowledging a given message delivery! This meant there was a theoretical potential to improve this by over 93% per dispatch, ideally getting as close to librdkafka delivery awareness as possible.
The Role of Condition Variables and Mutexes
Before we explore the implementation's roots and some performance benchmarks, let's establish the knowledge baseline. While most of you may be familiar with mutexes, condition variables are only occasionally used in Ruby daily.
Mutexes
A mutex (short for mutual exclusion) is a synchronization primitive that controls access to a shared resource. It ensures that only one thread can access the resource at a time, preventing race conditions.
Condition Variables
A condition variable is a synchronization primitive that allows threads to wait until a particular condition is true. It works with a mutex to avoid the "busy-wait" problem seen with sleep.
Below is a simple example demonstrating the use of condition variables in Ruby. One thread waits for a condition to be met, while another thread simulates some work, sets the condition to true, and signals the waiting thread to proceed.
mutex = Mutex.new
condition = ConditionVariable.new
ready = false
# Thread that waits for the condition to be true
waiting_thread = Thread.new do
mutex.synchronize do
puts "Waiting for the condition..."
condition.wait(mutex) until ready
puts "Condition met! Proceeding..."
end
end
# Thread that sets the condition to true
signaling_thread = Thread.new do
sleep(1) # Simulate some work
mutex.synchronize do
puts "Signaling the condition..."
ready = true
condition.signal
end
end
waiting_thread.join
signaling_thread.joinSpurious Wakeups
When using condition variables, it is essential to handle spurious wakeups. A spurious wakeup is when a thread waiting on a condition variable is awakened without being explicitly notified. This can happen for various reasons, such as system-level interruptions or other factors beyond the application's control.
The condition should always be checked in a loop to handle spurious wakeups. This ensures that even if the thread wakes up unexpectedly, it will recheck the condition and go back to waiting if it is not met. Here's an example:
@mutex.synchronize do
loop do
if condition_met?
# Proceed with the task
break
else
@resource.wait(@mutex)
end
end
endThis loop ensures that the thread only proceeds when the actual condition is met, thus safeguarding against spurious wakeups.
Implementing Condition Variables in rdkafka
To address the inefficiencies caused by sleep, Tomasz replaced it with a combination of condition variables and mutexes. This change allows threads to wait more efficiently for conditions to be met.
Code Implementation
The PR with this change can be found here.
Here's a simplified version of the wait code that replaced sleep with condition variables and mutexes:
def wait(max_wait_timeout: 60, raise_response_error: true)
timeout = max_wait_timeout ? monotonic_now + max_wait_timeout : MAX_WAIT_TIMEOUT_FOREVER
@mutex.synchronize do
loop do
if pending?
to_wait = (timeout - monotonic_now)
if to_wait.positive?
@resource.wait(@mutex, to_wait)
else
raise WaitTimeoutError.new(
"Waiting for #{operation_name} timed out after #{max_wait_timeout} seconds"
)
end
elsif self[:response] != 0 && raise_response_error
raise_error
else
return create_result
end
end
end
end
def unlock
@mutex.synchronize do
self[:pending] = false
@resource.broadcast
end
endThe moment librdkafka would trigger delivery callback, condition variable #broadcast would unlock the wait, effectively reducing the wait waste from around 93ms down to 0,07ms! That's a whooping 1328 times less!
Performance and Efficiency Gains
By using condition variables and mutexes, we observed a significant improvement in performance and efficiency:
- Reduced Latency: Threads wake up as soon as the condition is met, eliminating the unnecessary wait time introduced by sleep.
- Better Resource Utilization: The CPU is not idling during the waits, allowing for more efficient use of processing power.
- More Predictable Timing: The precise control over thread waking improves the predictability and reliability of synchronous operations.
The performance gains are substantial on a fast cluster. For instance, with queue.buffering.max.ms set to 5ms (default) and an acknowledgment (ack) of 1 or 2, Kafka can dispatch messages in 6-7ms. Using a 100ms sleep means waiting an additional 94ms, leading to a total wait time of 100ms for operations that could have been completed in 5-6ms.
The improvement is also significant in the case of WaterDrop, which had the sleep value set to 10ms. On a fast cluster with the same settings, a 10ms sleep would still cause a delay for operations that could be completed in 5ms, effectively doubling the wait time.
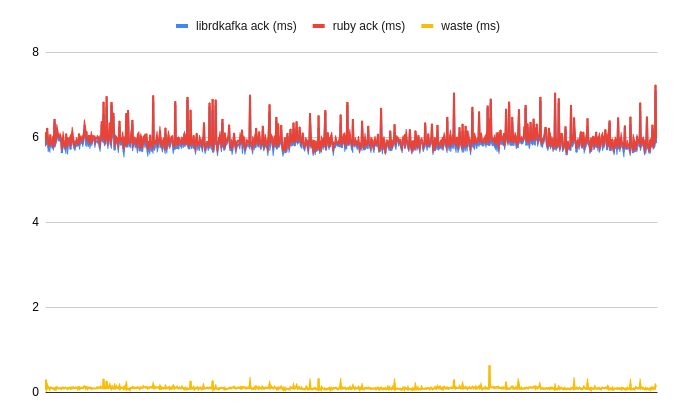
*Time from the message dispatch to the moment the given component is aware of its successful delivery, plus waste time (pointless wait). Less is better.
The change is so significant that putting it on a chart is hard. The time needed to dispatch 1000 messages synchronously is now over 16 times shorter!
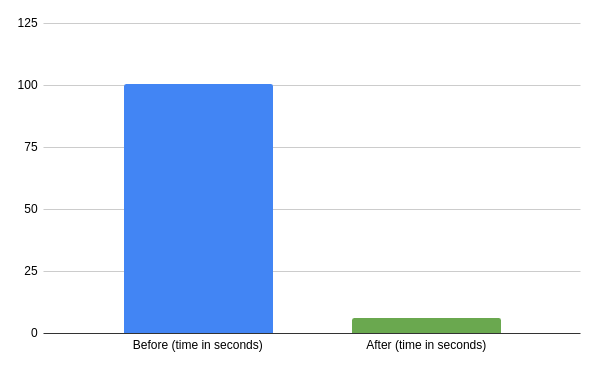
*Time needed to dispatch 1000 messages synchronously before and after the change. Less is better.
Implications for Ruby's Scheduler
Ruby's scheduler also benefits from the removal of short sleep intervals. The Ruby scheduler typically schedules thread work in 100ms increments. Short sleeps disrupt this scheduling, leading to inefficient thread management and potential context-switching overhead. The scheduler can manage threads more effectively using condition variables and mutexes, reducing the need for frequent context switches and improving overall application performance.
Rdkafka and WaterDrop Synchronicity Remarks
Karafka components and the design of librdkafka heavily emphasize asynchronous operations. These operations are the recommended approach for most tasks, offering superior performance and resource utilization. However, it's important to address synchronous operations. Their efficient handling is crucial, particularly for specific use cases like transactions.
This improvement in rdkafka enhances the performance of synchronous operations, making them more efficient and reliable. It is important to recognize users' diverse use cases, including those who prefer synchronous operations for their specific needs.
Conclusions
Replacing sleep with condition variables and mutexes in rdkafka significantly enhanced its performance. This approach eliminates unnecessary wait times, optimizes resource usage, and aligns better with Ruby's scheduling model. These improvements translate to a more efficient and responsive application, especially in high-performance environments where every millisecond counts.
By adopting this change, rdkafka can better handle high-volume synchronous operations, ensuring that threads wait only as long as necessary and wake up immediately when the required condition is met. This not only improves performance but also enhances the overall robustness of the system.