Kafka is a popular distributed streaming platform that is commonly used for building real-time data pipelines and streaming applications. One of the core features of Kafka is its ability to handle high-volume, real-time data streams and reliably process and distribute them to multiple consumers. However, in some cases, it may be necessary to postpone the processing of certain messages for many reasons.
This is where the Karafka's Delayed Topics feature comes in. This is a powerful mechanism that allows you to delay the consumption of messages for a later time, giving you greater control over your message processing and the ability to optimize your application's performance. In this article, we will take a deep dive into the Karafka's Delayed Topics feature and explore how it can be used to delay message processing in the Kafka-based applications.
The Power of Patience: Reasons to Postpone Your Kafka Messages Processing
Usually, you want to get the data as quickly as possible to ensure that your application can respond in real time. However, there are some situations where postponing messages processing can benefit your system. For example:
-
If you are implementing the retry logic, processing backoff can increase the chances of successful processing and reduce the number of failed messages that are sent to a dead letter queue. In this case, delaying processing can reduce the number of retries and minimize the impact of failed messages on your system.
-
Delaying the processing of data sent to a Kafka dead letter queue can reduce the number of retries and minimize the impact of failed messages on your system. By introducing the processing lag, you can make time for your system to recover and address any issues that may have caused the message to fail. This can be particularly useful if you are experiencing network latency, hardware issues, or other transient errors.
-
Delaying processing can give you more time to analyze the failed messages and take corrective actions. Collecting the failed messages in a dead-letter queue allows you to examine them in more detail to identify patterns or common issues. You can also use this information to improve your system and reduce the likelihood of similar failures in the future.
-
Processing lag can also be helpful in data crawling applications, where the immediately published data may not be immediately available due to HTTP caches. In such cases, it may be beneficial to always wait for the processing of messages for a fixed period to ensure that all the caches have expired and the data is fully available. By delaying the processing, you can avoid working with incomplete or stale data and ensure that your application works with the latest information.
Sleeping on the Job: A Problem with Kafka Delayed Processing
One common way developers delay the processing of Kafka messages is by using a sleep function to pause processing for a fixed period. While this approach is simple and easy to implement, it could be more efficient for a few reasons.
def consume
messages.each do |message|
time_diff = Time.now - message.timestamp
if time_diff < 5.minutes
sleep(5.minutes - time_diff)
redo
end
puts "Message key: #{message.key}, value: #{message.value}"
end
endUsing the sleep function can lead to unnecessarily long execution times. This can result in delays that impact the overall performance of your application. On top of that, Kafka may decide, that your process has hanged and may remove you out of the consumer group, creating unnecessery rebalances.
Using the sleep function can also result in idle threads, which can waste system resources and reduce the overall efficiency of your application. Idle threads can also prevent other messages from being processed, which can cause delays and bottlenecks in your system.
Below, you can find an example of how sleeping on partition 0 for ten seconds can impact Karafka's ability to process data from other topics/partitions*. In this scenario, we are producing and consuming messages simultaneously: 1 record per millisecond and using five partitions.
*Karafka can be configured in an optimized way to mitigate this, however, it was not done to illustrate the challenges related to sleeping
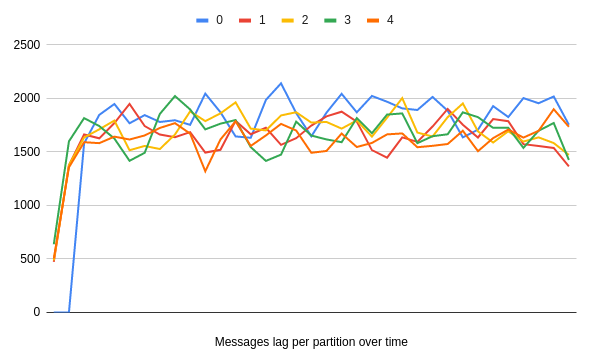
As you can see, we're immediately experiencing a lag on all of the partitions, and it is equal to the number of messages we produced per partition (10 000 messages for 10 seconds distributed to 5 partitions => 2000 messages per partition).
Below, you can also see that the age of messages aligns with the lag, effectively delaying all of our processing:

By default, Karafka and other Kafka consumers poll data in batches, process the data and then poll more. Only when all the work is finished for all the topics/partitions is more data polled. This is why you are seeing an increased lag for all the partitions, despite most of them not doing any work.
In general, it is more efficient and optimal to use a dedicated delay mechanism that is designed for Kafka message processing, such as the one built into Karafka. This approach can help you to optimize resource utilization, reduce processing delays, and ensure that your application remains performant and responsive.
Waking Up to a Better Solution for Kafka Delayed Processing
Rather than using sleep to delay consumption, a more effective approach is to pause partitions until the expected time has passed. While this can be more complex than sleeping, it provides a more optimal way of controlling the message processing delays. By pausing the partition, you can ensure that your application does not waste the system resources.
However, implementing the partition pausing correctly can be challenging, requiring considering things like rebalances and revocations. These events can cause the partition to be reassigned to a different consumer, impacting the timing of your processing. Additionally, if you pause for too long, you risk causing the delays that affect the performance of your application.
Fortunately, with Karafka, you can quickly implement this mechanism without worrying about these complexities. The Delayed Topics feature works seamlessly with other Karafka components, such as the Virtual Partitions and Long-Running Jobs, to provide a robust and efficient way of managing the processing delays. By leveraging this built-in mechanism, you can ensure that your application remains performant and responsive.
All that is needed for it to work is the delay_by routing definition for a given topic:
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
topic :orders do
consumer OrdersConsumer
# Always delay processing messages from the orders by 10 seconds
# Note: the code for delaying single partition is slightly different, but the outcome is the same
delay_by(10_000)
end
end
endWhen you apply this logic to the code and replace sleep with Karafkas' automatic delay, things look drastically different:
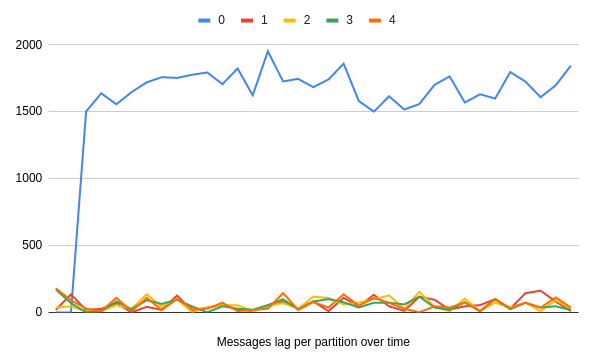
Not only is the lag close to zero for non-paused partitions, but the processing is within the polling frequency (note the logarithmic scale):
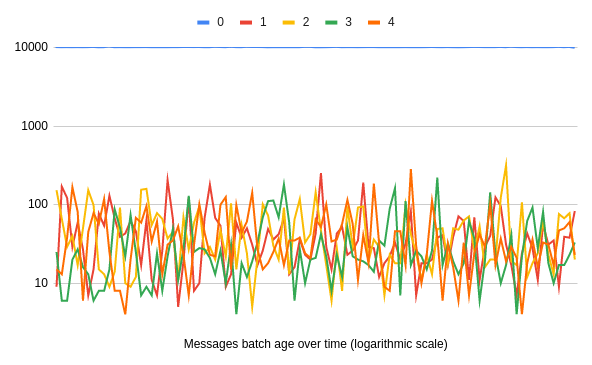
Only the topic/partion that you want is being delayed without impacting the rest of the data you are working with! That is because you do not block polling. Instead, after the remaining four partitions work is done, you immediately request more data to work with.
Limitations of pausing and resuming
While this feature provides a valuable way to postpone the messages processing, it does have some limitations to look out for.
One significant limitation is precision. It is not always millisecond-exact. This is because the Delayed Topics feature works by pausing a given partition for a specified amount of time and then unpausing it after that time has elapsed. However, the unpausing happens before the polling happens, so there can be a slight delay between when the partition is unpaused and when the delayed message is processed.
This limitation also means that the age of the messages may be slightly higher than the required minimum but will never be less than expected.
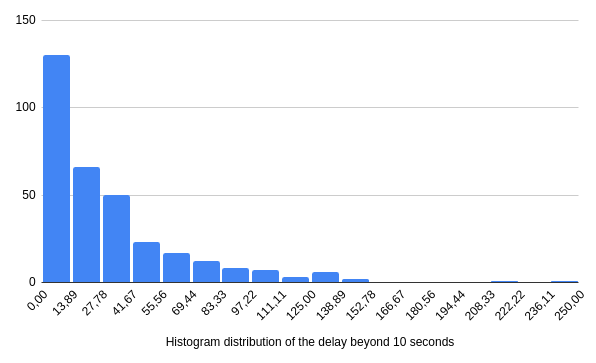
Below, you can see the "ten seconds + polling" histogram. While the theoretical max is equal to 10 seconds + max wait time, most of the time, we're close to 10 seconds + 10% of max wait time.
Summary
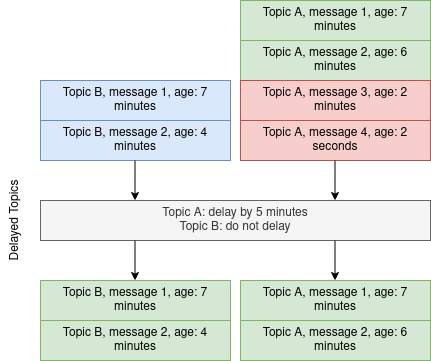
Karafka's Delayed Topics is a powerful feature that allows for arbitrary delays when working with messages from specific topics. It can be used in various use cases, such as e-commerce, social media moderation, and finance. By delaying message processing, you can perform additional processing or validation, moderate user-generated content, and introduce a retry mechanism for failed messages.
Building a complex and reliable open-source is neither easy nor fast, so Karafka Pro exists. It has many functionalities, including the one described in this blog post, that can help you build robust and performant event-driven applications.
Help me build and maintain a high-quality Kafka ecosystem for Ruby and Ruby on Rails.
Buy Karafka Pro.