
Table of Contents
- Kafka on Rails: Using Kafka with Ruby on Rails – Part 1 – Kafka basics and its advantages
- Kafka on Rails: Using Kafka with Ruby on Rails - Part 2 - Getting started with Rails and Kafka
Introduction
In this series of articles, I will try to provide you with an explanation on why you should invest your time in learning Kafka and the Karafka framework and how it can reshape the way you design and develop your Ruby applications. I will also try to answer some of the most common questions regarding those two and give you some real usage examples on how you can benefit fast from adding them to your technological stack.
What is Kafka?
Let me quote Wiki on that one:
Apache Kafka is an open-source stream processing platform developed by the Apache Software Foundation written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.
Now let's translate it into some general concepts (copied from here):
- It lets you publish and subscribe to streams of records. In this respect, it is similar to a message queue or enterprise messaging system.
- It lets you store streams of records in a fault-tolerant way.
- It lets you process streams of records as they occur.
- It lets you build real-time data pipeline based applications that reliably get data between systems and/or applications.
- It lets you build real-time streaming applications that transform and react to a stream of data and/or events.
- It allows you to simplify Domain Driver Design implementation within both new and existing applications and allows you to do this more technology agnostic.

Why should I be interested in it?
Because it allows you to expand. And I don't only mean that you will get much better performance with it and that you will be able to process more and faster.
What I really mean, is that once you understand concepts behind it, you will get a whole new set of possibilities to work with your data. You will expand your horizons and re-shift the way you design your code.
Systems that we build are data-driven and by having more ways of working with it, we get a totally new set of tools and solutions which we can use to make our work better and more efficient.
I keep saying, that the Ruby (and Rails in particular) community lacks architects and good architecture for post-MVP systems. One of the reasons why it is the way it is, is because we're to bound to the Request-Response way of thinking. Once you learn, that things can be done in a different way, it will impact your way of working with any technology you use, including Ruby on Rails.

Basic Kafka terminology
There are many general Kafka introduction articles, including the official one. Here, I will describe the most important parts of Kafka ecosystem, so you can start working with it as fast as possible.
Note: the description mentioned below might not be 100% accurate, but it should be enough for you to grasp the basics and keep you going.
Note: You can find more details about Kafka in a great Kafka in a Nutshell article.
General publish-subscribe messaging system concept
A messaging system lets you send messages between processes, applications, and servers. Applications should be able to connect to a system like that and transfer messages both ways.
Note: Publisher (one that sends a message) can be a receiver / subscriber at the same time.
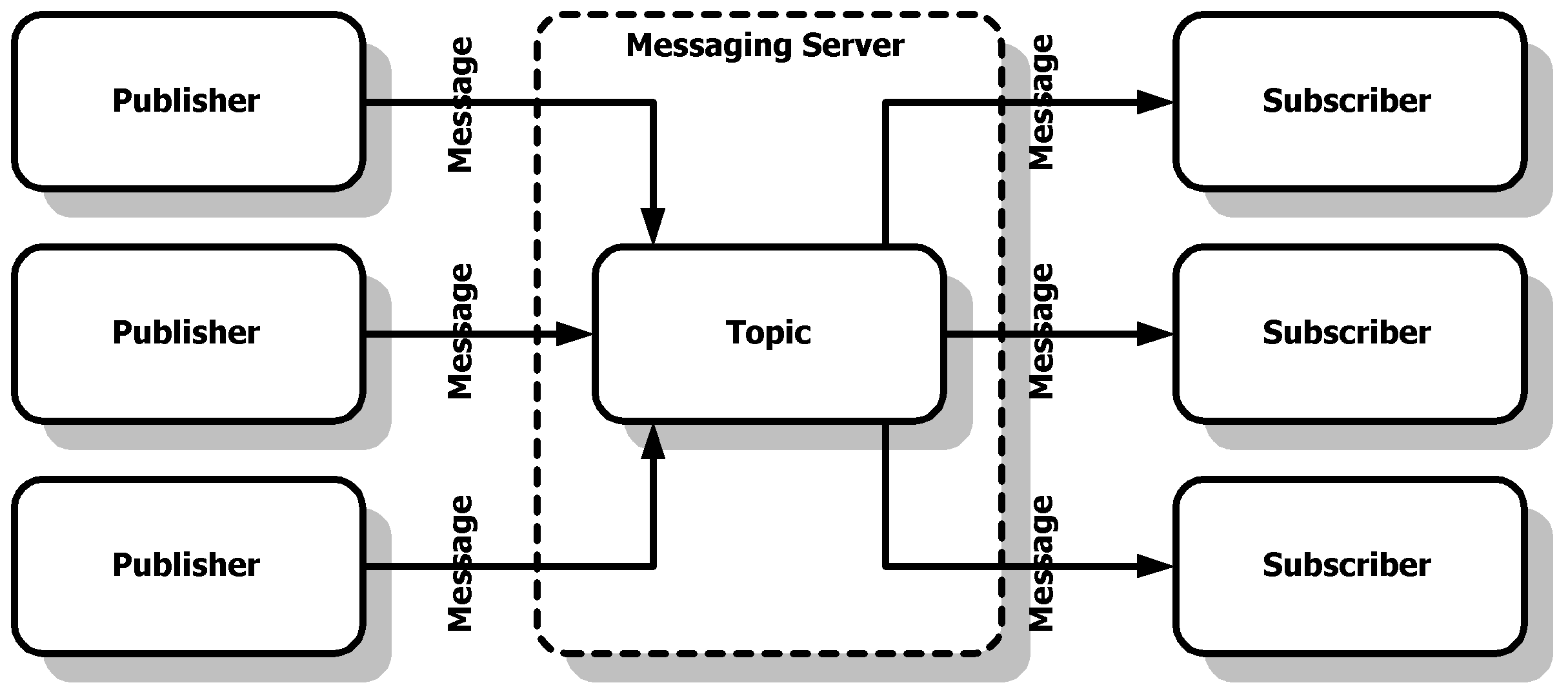
Illustration are taken from here.
Kafka brokers
Kafka is a distributed system that runs in a cluster. Each node in the cluster is called a Kafka broker. Broker is a single Kafka process that operates in a cluster.
Kafka topics with partitions
Kafka topic is just a named stream of records. It is a bit similar to Sidekiq or RabbiMQ queue concept. In general, it is a namespace where you are going to store messages that are similar to each other in terms of your business logic.
Everything is organized around topics and most Kafka guarantees are either for a topic or a topic partition. You send and receive messages from topics. Topics in Kafka are always multi-subscriber in nature; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.

Each Kafka topic is always divided in partitions. Even if you have a single partition, it is still there. Each partition is an ordered, immutable sequence of records that is continually appended to a structured commit log. The records in the partitions are each assigned a sequential id number called the offset.
You can fetch data from multiple partitions with a single consumer, but you need to be aware that their guaranteed delivery order will be maintained within data set from a single partition. It means, that you should not rely on a multi-partition message order within your business logic.
Kafka producers
Kafka producer is an application or a process that sends messages to Kafka.
Kafka consumers and consumer groups
Kafka consumer is an application that reads messages from Kafka.
Consumer can start reading messages from any offset. It means, that you can build systems that will start from the beginning of a topic and replay all the events/messages that Kafka contains or that will start from the current position and only work with new messages that are coming in.
Most of the time, for the first consumer run, you will pick one of those and later on you will always consume from the last offset you worked with before shutting down the consumer, but it is still good to know, that you can always start from any offset you want. This allows consumers to join the cluster at any point in time.
Consumers can be organized in groups. Consumer group includes consumers that subscribe to the same topics. Each consumer in a group will be assigned by Kafka with a set of partitions to work with. This approach allows you to greatly scale as you can increase number of partitions and spin up more consumers within the same consumer group. Kafka guarantees that a message is only read by a single consumer in the group.
You can have more consumers than partitions, but they won't actively participate in the consumption process. They will start performing work in the case of crashes or other failures of other consumers.
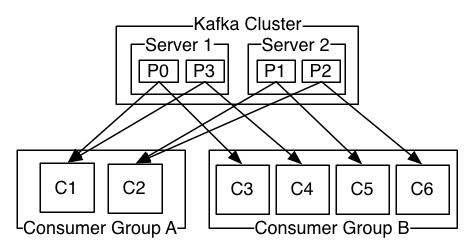
It's worth pointing out, that Kafka never pushes messages to the consumers on its own. It's the consumer that asks for messages when it is ready to handle them. This approach is super flexible, as it allows you to temporarily shut down the consumer and after it is back, it will catch up with all the messages that were not yet processed. A really great feature for SOA-based microservices that won't loose any data. In the worst case scenario, they will just process them a bit later.
What Kafka can do for me and my Ruby on Rails applications?
Note: We will explore all those benefits in details in next parts of this series. Here's just a quick summary.
A lot. And it really depends on your perspective and your role in the organization. Having Kafka as your messages backbone for Ruby and Rails systems will bring you benefits in many places.
Performance
Most of the Ruby on Rails systems are developed with objects in mind. This is true for both the client end-to-end requests as well as for the Sidekiq background jobs.
Having to refresh or recalculate some things in the system upon a change that is frequent during spikes that occur from time to time? Redesigning this part of the system and being able to fetch messages in batches can lower the need of constant recalculation significantly.
The Kafka-based systems also scale really, really well and due to the multi-consumer subscription model, you can optimize and scale separate parts of the system independently.
Architecture
This is by far the biggest advantage you will get in your Ruby and Rails systems when you add Kafka to them. You will be able to design, build and test independent components that can do things outside of a typical Rails "HTTP like" processing scope.
You won't have to worry about (almost) anything else except your bounded context and your business domain. Due to the way Kafka works, sometimes you will be even forced to use tools and solutions that aren't from the "Rails way".
Have you ever been able to build a proof of concept application that could hook up in real time to staging or production without introducing side-effects? Were you able to run it from your local machine and see how things work? With Kafka, it can be super easy to achieve that.
Note: Don't get me wrong, it's not Kafka itself in your stack, that will auto-magically change everything. It's you having it and understanding what you can achieve with it who will trigger and lead the change. Kafka will just allow you to do those things easily and fast.
Deployment process
Being able to re-consume and re-process messages allows you to shutdown certain parts of the system without affecting others. Since the Kafka messages are not being pushed, they don't disappear, if not consumed immediately. With a bit of good architecture, you can deploy, perform maintenance and do other things while the system is running without users knowing about that.
Development performance
The bigger system gets, the more often developers step on each other's toes. Development costs and developers frustration will grow exponentially when they:
- change the same things simultaneously,
- have to remember about edge cases out of our current business domain scope,
- have to deal with additional callback actions and/or non explicit processes.
Kafka allows you to easily use DDD to build systems that are event-based and that can be managed and developed with much smaller overhead than a typical Ruby on Rails MVC, callback-based system.
Freedom of choice
Ruby on Rails can be a burden from time to time. Plain Ruby can do really well. ActiveRecord can be replaced with ROM and Dry-Validation, bringing you many benefits. However, it can be really hard to introduce new concepts in a huge legacy system. If you have Kafka and Karafka, you can spin up a new experimental applications that will perform some business within a bounded context and won't do any harm to the existing logic and/or data.
Tired of Ruby in general? Replace a single Kafka based component with a different one in a different technology that might better suit your needs.
I already have a message bus (Redis + Sidekiq)
Kafka is not a message bus. It is a distributed streaming platform.
It's not entirely accurate to compare them as they are not the same. There are many business cases that could be solved with any of those. However, there are some significant differences,when looking from the Sidekiq perspective, that it's good to know and understand:
- Kafka does not handle reentrancy - in case of a message processing failure, it is up to you to decide what to do with it. It won't be pushed back and retried automatically,
- Kafka does not support pushing the same message into a queue again (you can push it back but it will be a new message in the partition). Messages are immutable and once placed in Kafka, they cannot be changed,
- Sidekiq does not support message broadcasting and is more command-oriented than event-oriented (do-this vs did-this), especially within Ruby on Rails and Sidekiq scope,
- Sidekiq does not support batch consuming,
- Kafka can keep events much (configurably) longer due to persistence,
- Kafka events can be consumed multiple times by multiple consumer groups,
- Kafka can be the only message bus for any publish-subscribe flows,
- Sidekiq message that got consumed is being removed from the queue, which means that you cannot re-consume it if needed.
Summary - Karafka as a Ruby Kafka backbone
![]()
![]()
All this introduction has had one goal: to make you familiar with the basic concepts and advantages of using Kafka with your new and existing Ruby and Rails based systems.
In the next parts of this series, we will explore Karafka, a framework used to simplify Apache Kafka based Ruby applications development.
We will start from building small applications that use Karafka as an internal and external message backbone, and then we'll move to integrating Karafka with existing monoliths and using it to decompose and re-design your existing code base.
Somewhere down the road, in this series, I will also introduce other "non-Rails" stack tools including Traiblazer, Dry-Validation, ROM and few others, to give you a wider perspective on how much you can benefit, when combining proper tools altogether.
Karafka provides you with a lot of possibilities and you will see for yourself, that when boosted with other great tools, your code quality, architecture, performance and the way you work can jump to a totally different level.
Stay tuned :-)

