Wstęp
Tutorial składa się z dwóch cześci:
- FacebookBot z wykorzystaniem Mechanize
- Cachowanie odpytań
Kod (nowszy i lepszy ;) ) dostępny na githubie.
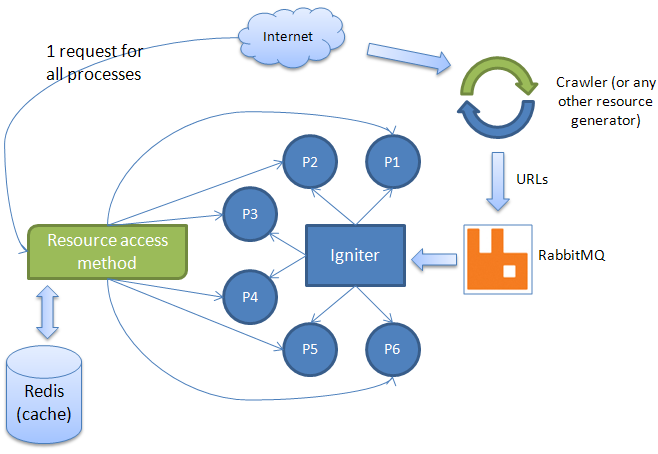
Ze względu na dużą popularność wpisu dot. "naprawy" linków z Facebooka (tutaj), postanowiłem dołączyć wam drugą część poradnika. Ta część dotyczyć będzie cachowania wyników - cobyśmy za często nie odpytywali Facebooka o linki. Dlaczego lepiej jest cachować wyniki, niż każdorazowo odpytywać FB? Z dwóch powodów:
- czas - przede wszystkim - czas potrzebny na odpytanie serwera Facebooka o potrzebne dane, a następnie zwrócenie tego klientowi, zajmuje zbyt wiele czasu. Dużo szybciej jest wyciągnąć i zwrócić pojedynczy rekord z bazy,
- logi - Facebook na pewno nie będzie zadowolony (i nie przepuści po pewnym czasie) z tego, że codziennie nasze konto odpytuje np. 30 - 40 tys razy o strony z filmami. Uznają to za dziwne zachowanie i po prostu zbanują konto lub co gorsza IP.
Czas "życia" adresu z Facebooka to od 24 do 36 godzin. Aby ciągłość usług była stabilna, załóżmy że cache będzie działał przez 30 minut. Da nam to odpytywanie Facebooka - maksymalnie co 30 minut na filmik (a nie przy każdym żądaniu). Dodatkowo, kiedy nasz cache się przedawni, nie odpytamy od razu o nowy URL - najpierw sprawdzimy czy stary już umarł, wysyłając zapytanie o nagłówek pod URL filmu. Jeśli dostaniemy odpowiedź 200 - tzn, że link wciąż jest aktywny i nie musimy go zmieniać.
Takie podejście zapewni nam uptime na poziomie (w najgorszym przypadku): 100%-(30/1440)*100%= 97.9% czasu. A to i tak zakładając wariant, że url z FB zmieni się dokładnie po naszym odpytaniu, przez co cache będzie serwował przez całe 30 minut zły URL. Myślę, że spokojnie można przyjąć uptime na poziomie 98.5%-99%.
Ustawienia
Aby było nam łatwiej, wszystkie ustawienia będziemy przechowywać w jednym miejscu. Stwórzmy sobie plik lib/settings.rb, w którym w stałej SETTINGS będziemy przechowywać co nam trzeba:
SETTINGS = {
:db_user => 'user_bazy',
:db_adapter => "mysql",
:db_host => "mysql5",
:db_database => "baza",
:db_pass => 'haslo',
:db_socket => '/tmp/mysql.sock',
:fb_login => 'mail@do.facebooka.pl',
:fb_pass => 'haslo-do-fb',
}
Baza danych
Do przechowywania danych wykorzystamy bazę MySQLa. Stworzymy sobie plik db_connector.rb, który tak jak poprzedni (i wszystkie następne oprócz main.rb) będzie przechowywany w katalogu lib/. W pliku tym będziemy trzymać kod odpowiedzialny za łączenie się z bazą danych oraz naszą "pseudo" migrację - generującą tabelę z odpowiednimi kolumnami. Warto zwrócić uwagę na to, że mimo wykorzystania ActiveRecord - ORMa z Railsów - nie wykorzystujemy całego frameworka. Sam ORM nam w zupełności wystarczy.
ActiveRecord::Base.establish_connection(
:adapter => SETTINGS[:db_adapter],
:host => SETTINGS[:db_host],
:database => SETTINGS[:db_database],
:username => SETTINGS[:db_user],
:password => SETTINGS[:db_pass],
:socket => SETTINGS[:db_socket]
)
unless Video.table_exists?
ActiveRecord::Base.connection.create_table(:videos) do |t|
t.column :video_id, :string
t.column :name, :string
t.column :url, :string, :default => nil
t.column :views, :integer, :default => 1
t.column :cached_at, :datetime
end
end
Warto zwrócić uwagę na ten warunek:
unless Video.table_exists?
dzięki któremu migracja zostanie wykonana tylko jeśli tabela z danymi nie istnieje.
Model filmu wideo
Mamy już gdzie trzymać nasze dane. Pora stworzyć model pojedyńczego filmiku z FB. Model nasz zawierać będzie cztery metody:
- url=(new_url) - przypisanie nowego adresu filmiku z Facebooka,
- working? - metoda zwracająca true/false zależnie od tego czy filmik działa czy też nie,
- url_working? - metoda sprawdzająca nagłówek odpowiedzi z żądania pod adresem URL filmu,
- (private) set_cached_at_time - ustawiająca podczas tworzenia instancji czas cachowania na teraz.
Zacznijmy od szkieletu modelu:
require 'net/http'
require 'uri'
class Video < ActiveRecord::Base
# 30 minut
CACHE_TIME = 60*30
before_create :set_cached_at_time
# Gwarancja, ze jeden filmik bedzie mial jeden wpis w bazie
validates_uniqueness_of :video_id
validate :working?
end
Metody
1. url=
def url=(new_url)
self.errors.clear
self.cached_at = Time.now
super new_url
end
Część z was może zapytać, dlaczego czyszczę błędy (self.errors.clear)? Czyszczę je, ponieważ przypisanie nowego URLa następuje wtedy i tylko wtedy, gdy stary był niepoprawny i nie przechodził walidacji. Nowy z założenia przechodzi, tak więc błąd starego URLa musi zostać "zapomniany".
2. working?
def working?
v = false
if self.cached_at >= Time.now - CACHE_TIME && self.url.length > 10
v = true
else
v = url_working?
self.cached_at = Time.now
end
self.errors.add(:cached_at, 'Cache ulegl przedawnieniu') unless v
v
end
W tej metodzie sprawdzamy czy URL jest poprawny. Jeśli jest "młody" (czyli nowszy niż 30 minut) i jego długość jest większa niż 10 (to tak dla pewności ;) ), tzn. że jest prawdziwy (w 99% procentach przypadków - patrz wstęp). W przeciwnym razie - sprawdzamy nagłówek odpowiedzi z żądania wysłanego pod link, i jeśli jest poprawny - to ok, jeśli nie - to wrzucamy błąd do tablicy błędów naszej instancji modelu. Uważniejsze osoby mogą zapytać, dlaczego ustawiamy cache na nowy - mimo, że URL się nie zmienił. Ustawiamy tak, ponieważ zmiana URLa nastąpi na pewno jeśli ten link był niepoprawny. Nastąpi ona jednak w pliku main.rb.
3. url_working?
def url_working?
begin
host = URI.parse(self.url).host
http = Net::HTTP.new(host)
headers = http.head(self.url)
rescue
return true
end
if headers.code == "200"
true
else
false
end
end
Zasadniczo sposób działania tej metody opisałem już wyżej, ale tak dla pewności:
- Wysyłamy żądanie nagłówka pod adres naszego filmiku
- Jeśli coś poszło nie tak - zakładamy, że URL nie jest poprawny
- Jeśli dostaliśmy nagłówek to go sprawdzamy
- Jeśli 200 - to znaczy że URL jest poprawny (true)
- Jeśli cokolwiek innego (404, 401, 403, 500, itd) - tzn. że już "umarł" (false)
4. set_cached_at_time
def set_cached_at_time
self.cached_at = Time.now
end
Tutaj nie ma co tłumaczyć.
To by było na tyle jeśli chodzi o nasz model Video. Pozostaje nam jeszcze tylko plik main.rb.
Połączenie wszystkiego w całość
Na początek zaincludujmy pliki z katalogu lib/ oraz inne niezbędne nam biblioteki:
# coding: utf-8
def require_local(file)
require File.join(File.dirname(__FILE__), "/lib/#{file}")
end
require 'rubygems'
require_local 'settings'
require_local 'facebook_bot'
require 'active_record'
require_local 'video'
require_local 'db_connector'
Zwróćcie uwagę, że dołączamy naszego FacebookBota z pierwszej części tego poradnika. Jednak jest to wersja lekko zmodyfikowana w stos. do wersji z części pierwszej. Różnica jest zasadniczo taka, że ta "nowa" wersja bota, oprócz URLa filmu pobiera także jego nazwę, dlatego radzę pobrać sobie paczkę ze źródełkami lub plik z botem z mojego githuba.
Dalej pobieramy z parametrów ID filmu oraz opcję "force" której użycie wymusi regenerację linku wprost z Facebooka, niezależnie od wartości cache'a:
video_id = ARGV[0]
force = false || ARGV[1] == 'true'
Dalej cała główna logika tej aplikacji:
video = Video.find_by_video_id(video_id)
# Jesli taki plik istnieje i jest poprawny i żądanie nie jest wymuszone
# to zwróć link
if video && video.valid? && !force
puts 'Cache'
puts video.url
else
# Jesli link był niepoprawny lub jest to nowy filmik to zainicjuj FBbota
# i pobierz z FB URL oraz nazwę filmiku
fb = FacebookBot.new(SETTINGS[:fb_login], SETTINGS[:fb_pass])
url = fb.video_url(video_id)
name = fb.video_name(video_id)
# Jesli video istniało tylko URL wygasł to przypisz nowy URL i nazwę
# (nazwe na wypadek gdyby ulegla zmianie)
if video
video.url = url
video.name = name
else
# Jesli filmiku nie bylo to go utworz
video = Video.new(
:video_id => video_id,
:url => url,
:name => name
)
end
puts 'Nowe wywolanie'
puts video.url
end
# Podbij ilosc wyswietlen
video.views+=1
# I Zapisz zmiany w modelu
video.save
Tyle. Od teraz mamy w pełni działający program umożliwiający "regenerację" linków do plików video z Facebooka. Dzięki cachowaniu w bazie danych ilość odpytań dla popularnych filmików znacznie spada.
Tutorial składa się z dwóch cześci:
- FacebookBot z wykorzystaniem Mechanize
- Cachowanie odpytań
Kod (nowszy i lepszy ;) ) dostępny na githubie.

{kind=link}
