Note: These release notes cover only the major changes. To learn about various bug fixes and changes, please refer to the change logs or check out the list of commits in the main Karafka repository on GitHub.
Table of Contents
Time passes by, Kafka is already 1.0 and Karafka is already 1.1.
Code quality
I will start from the same thing as with 1.0. We're constantly working on having a better and easier code base. Apart from adding several new monitoring tools to our code quality stack, we were able to maintain a pretty decent offenses distribution and trends.
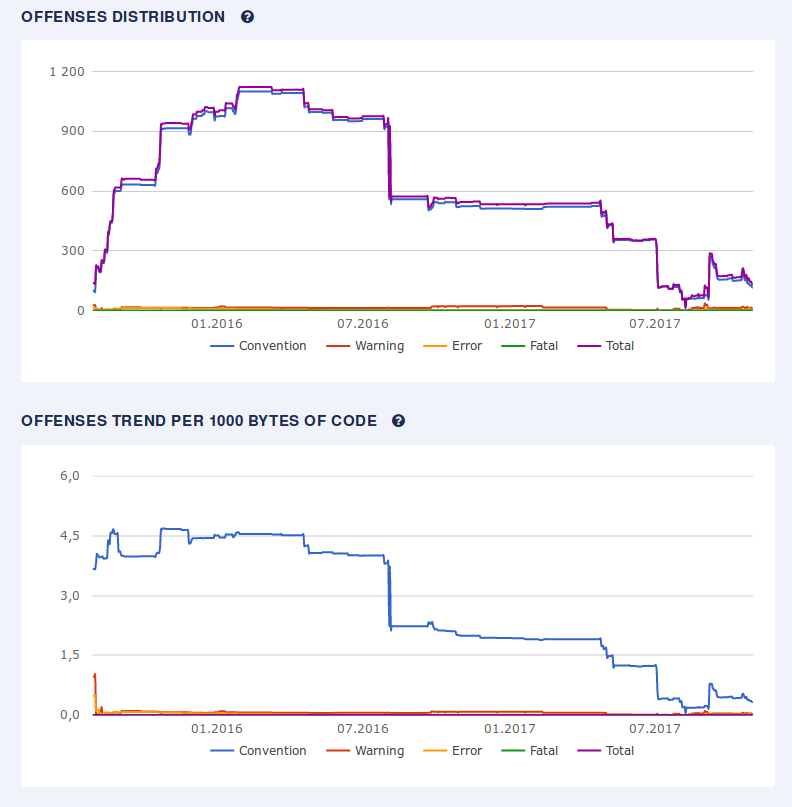
It's also worth noting, that our reaction time towards gem updates and other upgrades have significantly improved, which means that we're almost always up to date with all the dependencies.
Features
There are several new features included in this release. Most of them focus on advanced users, that needed a better control over processing flow. However, this does not mean, that regular "consumers" won't benefit from them. Features from this release give you space to expand your applications beyond simple consumption and allow you to process more and faster.
Manual offset management
Most of the time you will be happy with the automatic offset management, however there are some cases in which you might be interested in taking control over this process. It can be helpful i.a.:
- In memory DDD sagas realization,
- Buffering,
- Simulating transactions.
In a real shortcut, this is how you can use it:
Disable automatic offset management either on the app or the consumer group level:
class App < Karafka::App
consumer_groups.draw do
consumer_group :events do
automatically_mark_as_consumed false
topic :user_events do
controller EventsController
end
end
end
end
and just commit your offsets manually:
def consume # Do something with messages EventStore.store(params_batch.parsed) # And now mark last message as consumed, # so we won't consume any of already processed messages again consumer.mark_as_consumed params_batch.to_a.last end
Note: You can read more about this feature in the Manual offset management (checkpointing) Wiki section.
WaterDrop 1.0 with sync and async support
WaterDrop is a standalone messages producer that is integrated with Karafka out of the box.
We've recently redesigned both its internals and the API, to make it better, less memory consuming, easier to use and more bullet-proof.
Karafka 1.1 comes with full WaterDrop 1.0 support, including both synchronous and asynchronous producers. It also integrates automatically with it, populating all the options related to Kafka that were set during the Karafka framework configuration.
In case you want to change WaterDrop configuration settings, you can do this after you setup and boot Karafka framework in the karafka.rb file:
class App < Karafka::App
setup do |config|
config.kafka.seed_brokers = ::Settings.kafka.seed_brokers
config.kafka.offset_commit_threshold = 30
config.client_id = ::Settings.name
end
consumer_groups.draw do
# consumer groups definitions go here
end
end
App.boot!
# Overwrite default delivery setting and don't send in the test env
WaterDrop.setup do |water_config|
water_config.deliver = !Karafka.env.test?
end
Responders are still the recommended way to generate Kafka messages, however if you want, you can use WaterDrop directly:
# For sync
WaterDrop::SyncProducer.call('message', topic: 'my-topic')
# or for async
WaterDrop::AsyncProducer.call('message', topic: 'my-topic')
Async support per topic for responders
As mentioned above, WaterDrop now supports both synchronous and asynchronous way of producing messages. If wouldn't make any sense, if the same would not be available for responders. From now on, you can decide on a delivery method per topic with which you decide to work:
class ExampleResponder < ApplicationResponder
topic :regular_topic
topic :async_topic, async: true
def respond(user, profile)
respond_to :regular_topic, user
# This will be sent async
respond_to :async_topic, user
end
end
New set of callbacks for better flow control
Callbacks can be used to trigger some actions on certain moments of Karafka messages receiving flow. You can use them for additional actions that need to take place at certain moments. They are not available by default, as we don't want to provide functionalities that are not required by users by default.
In order to be able to use them, you need to include Karafka::Controllers::Callbacks module into your controller class:
class ExamplesController < Karafka::BaseController
include Karafka::Controllers::Callbacks
after_fetched do
# Some logic here
end
def consume
# Some logic here
end
end
Currently there are four callbacks available:
- after_fetched - executed right after we fetch messages from Kafka but before the main logic kicks in.
- before_stop - executed before the shutdown process kicks in. Really useful if you use manual offset management.
- after_poll - executed after each attempt to fetch messages from Kafka (even when there is no data).
- before_poll - executed before each attempt to fetch messages from Kafka (even when there is no data).
Please visit the Callbacks Wiki section for more details.
Incompatibilities and breaking changes
after_received callback renamed to after_fetched
IF you use the after_received callback, you will have to do two things to make it work with 1.1:
- Rename it from after_received to after_fetched
- include Karafka::Controllers::Callbacks module inside of your controller
class ExamplesController < Karafka::BaseController
include Karafka::Controllers::Callbacks
after_fetched do
# Some logic here
end
end
connection_pool config options are no longer needed
WaterDrop 1.0 uses in-thread consumer pool, so connection pool is no longer required. You need to remove all connection_pool related settings.
Celluloid config options are no longer needed
Karafka no longer uses Celluloid, so all the Celluloid options are no longer needed.
#perform is now renamed to #consume
#perform has been renamed to #consume. Please update all your controllers to match this change.
class ExamplesController < Karafka::BaseController
include Karafka::Controllers::Callbacks
# Old name
def perform
# Some logic here
end
# New name
def consume
# Some logic here
end
end
Renamed batch_consuming option to batch_fetching and batch_processing to batch_consuming
We're constantly trying to unify naming conventions. Due to some misunderstanding on what is consuming and what is processing, we've decided to rename them. So just to clarify:
- fetching is a process of receiving messages from Kafka cluster (no user business logic involved)
- consuming is a process of applying your business logic na processing the data
So now:
- if you want to fetch messages from Kafka in batches, you need to have batch_fetching set to true
- if you also want to work with messages in batches, you need to have batch_consuming set to true
Other improvements
Wiki updates
Apart from code changes, we also updated Wiki pages accordingly and added the FAQ section.
Celluloid dropped in favor of native thread pool management
Mike has a great explanation related to Sidekiq on that one. Our reasons were quite similar:
- Memory consumption,
- Way more dependencies needed,
- Abstraction overhead.
Also, with a bit of Ruby-Kafka patching, we don't need an extra layer to handle shutting down and other edge cases.
Unused dependencies cleanup
We're constantly working on lowering the memory footprint of Karafka. It turned out, that we would load some of the parts of ActiveSupport that weren't required. This is now cleaned up. Also we're planning to completely drop ActiveSupport requirement as we're not the biggest fans of this gem.
Getting started with Karafka
If you want to get started with Kafka and Karafka as fast as possible, then the best idea is to just clone our example repository:
git clone https://github.com/karafka/karafka-example-app ./example_app
then, just bundle install all the dependencies:
cd ./example_app bundle install
and follow the instructions from the example app Wiki.