Table of Contents
Ruby 2.3.0-preview1 has been released. Let's see what new features we're getting this time:
Table of content
- Frozen string literals
- Safe navigation operator
- Did you mean
- Hash Comparison
- Hash#dig and Array#dig
- Number #negative? and #positive?
- Hash#to_proc
- Hash#fetch_values
- Enumerable#grep_v
- Conclusions
Frozen string literals
If you like reviewing gems, you could often find something like that:
module MyGem VERSION = '1.0.2'.freeze end
Did you ever wonder why people tend to freeze their strings? There are 2 benefits of doing so:
- First of all, you tell other programmers that this string should not change - never. It should remain as it is and it is intended (in general this is why freeze exists)
- Performance is a factor as well. Frozen strings won't be changed in the whole application, so Ruby can take advantage of it and reduce object allocation and memory usage
It's worth pointing out, that Ruby 3.0 might consider all strings immutable by default (1, 2). That means that you can use current version of this feature as a first step to prepare yourself for that.
How can you start using "frozen by default" strings without having to mark all of them with #freeze? For now, you will have to add following magic comment at the beginning of each Ruby file:
# frozen_string_literal: true # The comment above will make all strings in a current file frozen
Luckily, as expected from Ruby community, there's already a gem that will add the magic comment to all the files from your Ruby projects: magic_frozen_string_literal.
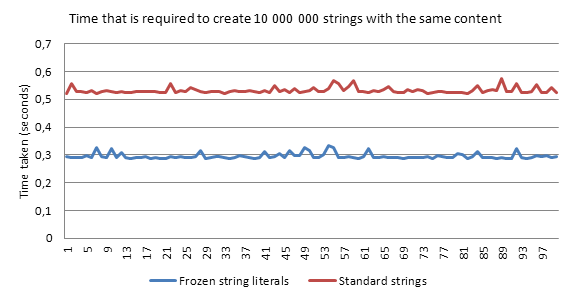
Ok, so we will lose possibility to change strings (if we won't explicitly allow that), what we will get in return? Performance. Here are the performance results of creating 10 000 000 strings all over again (with GC disabled). In my opinion results are astonishing (you can find the benchmark here). With frozen strings a simple "string based" script runs 44% faster then the version without freezing.
If you wonder what will happen, if you try to modify frozen string, here's a simple example you can run:
# frozen_string_literal: true 'string' << 'new part' # output: frozen.rb:3:in `<main>': can't modify frozen String (RuntimeError)
This description is pretty straightforward for smaller applications, but if you deal with many strings, from many places, you might have a bit of trouble finding an exact place where this particular string was created. That's when --enable-frozen-string-literal-debug flag for Ruby becomes handy:
# frozen_string_literal: true 'string' << 'new part' # Execute with --enable-frozen-string-literal-debug flag # ruby --enable-frozen-string-literal-debug script.rb # output: frozen.rb:3:in `<main>': can't modify frozen String, created at frozen.rb:3 (RuntimeError)
it will tell you not only the place where you tried to modify a frozen string, but also a place where this string has been created.
Immutable strings make us also one step closer to understanding, introducing and using the concept of immutable objects in Ruby.
Easy nil saving FTW! Finally a ready to go replacement for many #try use cases (however not for all of them). Small yet really sufficient feature, especially for non-Rails people. So what exactly Object#try was doing?
Object#try - Invokes the public method whose name goes as first argument just like public_send does, except that if the receiver does not respond to it the call returns nil rather than raising an exception.
This is how you can use it:
# Ruby 2.2.3
user = User.first
if user && user.profile
puts "User: #{user.profile.nick}"
end
# Ruby 2.3.0
user = User.first
if user&.profile
puts "User: #{user.profile.nick}"
end
At first that might not look too helpful but image a chain of checks similar to this one:
if user&.profile&.settings&.deliver? # and so on...
Warning: It is worth pointing out that the Object#try from ActiveSupport and the safe navigator operation differs a bit in their behaviour so you need to closely consider each case in which you want to replace one with another (both ways). When we have a nil object on which we want to invoke the method (both via try or safe navigator), they behave the same:
user = User.first # no users - user contain nil user.nil? #=> true user.try(:name) #=> nil user&.name #=> nil
However, their behaviour strongly differs when we have non-nil objects that may (or may not) respond to a given method:
class User
def name
'Foo'
end
end
class Student < User
def surname
'Bar'
end
end
user = User.new
# This wont fail - even when user exists but does not respond to a #surname method
if user.try(:surname)
puts user.surname
end
user = Student.new
if user.try(:surname)
puts user.surname
end
# With an object that has a #surname method the safe
# navigation operation will work exactly the same as try
if user&.surname
puts user.surname
end
# However it will fail if object exists but does not have a #surname method
user = User.new
if user&.surname
puts user.surname
end
NoMethodError: undefined method `surname' for #<User:0x000000053691d8>
Does this difference really matter? I strongly believe so! #try gives you way more freedom in terms of what you can do with it. You can have multiple objects of different types and you can just try if they are not nil and if they respond to a given method and based on that react. However it is not the case with the nil safe operator - it requires an object (except nil) to respond to a given method - otherwise it will raise an NoMethodError. This is how they look (more or less) when implemented in Ruby:
# try method simplified # We skip arguments for simplicity def try(method_name) return nil if nil? return nil unless respond_to?(method_name) send(method_name) end def safe_navigator(method_name) return nil if nil? # Does not care if an object does not respond to a given method send(method_name) end
And that's why, when replacing #try with the safe navigation operator (or the other way around), you need to be extra cautious!
Did you mean
A small helper for debugging process directly built in into Ruby. In general it will help you detect any typos and misspellings that cause your code to fail. Will it become handy? Well I tell you once I'll use it for a while.
class User def name end end user = User.new use.name # Error you will receive: user.rb:7:in `<main>': undefined local variable or method `use' for main:Object (NameError) Did you mean? user
Hash Comparison
This is a really nice feature. Comparing hashes like numbers. Up until now we had the #include? method on a Hash, however it could only check if a given key is included (we could not check if one hash contains a different one):
{ a: 1, b: 2 }.include?(:a) #=> true
{ a: 1, b: 2 }.include?(a: 1) #=> false
Now you can check it using comparisons:
{ a: 1, b: 2 } >= { a: 1 } #=> true
{ a: 1, b: 2 } >= { a: 2 } #=> false
That way can compare not only keys but also their values. Here are some examples that should help you understand how it goes:
Same keys and content
{ a: 1 } <= { a: 1 } #= true
{ a: 1 } >= { a: 1 } #= true
{ a: 1 } == { a: 1 } #= true
{ a: 1 } > { a: 1 } #= false
{ a: 1 } < { a: 1 } #= false
Same keys, different content
{ a: 1 } <= { a: 2 } #= false
{ a: 1 } >= { a: 2 } #= false
{ a: 1 } == { a: 2 } #= false
{ a: 1 } > { a: 2 } #= false
{ a: 1 } < { a: 2 } #= false
Same content, different keys
{ a: 1 } <= { b: 1 } #= false
{ a: 1 } >= { b: 1 } #= false
{ a: 1 } == { b: 1 } #= false
{ a: 1 } > { b: 1 } #= false
{ a: 1 } < { b: 1 } #= false
Hash containing different one (with same values)
{ a: 1, b: 2 } <= { a: 1 } #= false
{ a: 1, b: 2 } >= { a: 1 } #= true
{ a: 1, b: 2 } == { a: 1 } #= false
{ a: 1, b: 2 } > { a: 1 } #= true
{ a: 1, b: 2 } < { a: 1 } #= false
Hash containing different one (with different values)
{ a: 1, b: 2 } <= { a: 3 } #= false
{ a: 1, b: 2 } >= { a: 3 } #= false
{ a: 1, b: 2 } == { a: 3 } #= false
{ a: 1, b: 2 } > { a: 3 } #= false
{ a: 1, b: 2 } < { a: 3 } #= false
Number #negative? and #positive?
A simple example should be enough to describe this feature:
elements = (-10..10) elements.select(&:positive?) #=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] elements.select(&:negative?) #=> [-10, -9, -8, -7, -6, -5, -4, -3, -2, -1]
Hash#dig and Array#dig
Ruby was always about doing things in a short and easy way. Now this can be also said about retrieving deeply nested data from hashes and arrays thanks to #dig. No more || {} tricks or anything like that!
# Nested hashes
settings = {
api: {
adwords: {
url: 'url'
}
}
}
settings.dig(:api, :adwords, :url) # => 'url'
settings.dig(:api, :adwords, :key) # => nil
# Way better than this:
((settings[:api] || {})[:adwords] || {})[:url]
# Nested arrays
nested_data = [
[
%w( a b c )
],
[]
]
nested_data.dig(0, 0, 0) # => 'a'
nested_data.dig(0, 1, 0) # => nil
# Way better than this:
((nested_data[0] || [])[0] || [])[0]
Hash#to_proc
This feature allows to use hashes to iterate over enumerables
h = { a: 1, b: 2, c: 3 }
k = %i{ a b c d }
k.map(&h)
Hash#fetch_values
More strict version of Hash#values_at:
settings = {
name: 'app_name',
version: '1.0'
}
settings.values_at(:name, :key) #=> ['app_name', nil]
settings.fetch_values(:name, :key) #=> exception will be raised
KeyError: key not found: :key
Enumerable#grep_v
I could use this one few times. Instead of negating a regexp itself, we can now just specify that we want all the elements that does not match a given regexp. It also works for filtering by types.
# Regexp example data = %w( maciej@mensfeld.pl notanemail thisisnotanemailaswell@ ) regexp = /.+\@.+\..+/ data.grep(regexp) #=> ['maciej@mensfeld.pl'] data.grep_v(regexp) #=> ['notanemail', 'thisisnotanemailaswell@']
# Type matching example
data = [nil, [], {}]
data.grep(Array) #=> [[]]
data.grep_v(Array) #=> [nil, {}]
Conclusions
It's been a while since we had a new Ruby version with some additional features. It's not a big step but it definitely brings something to the table. Nothing that we would not be able to do with an old plain Ruby, but now many things will require much less work. If we consider this release as a transitional one, it feels that things are heading in a good direction (towards 3.0).
November 15, 2015 — 03:46
Safe navigation operator is similar to Object#try! than Object#try.
Actually we had discussions about the behaviors, finally @a_matsuda, a RoR contributor and a CRuby committer, said the former is preferred to the latter nowadays in RoR.
November 15, 2015 — 13:10
You’re absolutely right and imho this is a really good decision that it acts as #try! not #try
December 26, 2015 — 11:00
good one….!!! thanks for sharing.
January 9, 2016 — 07:32
Its really good!