
Note: This case is valid also for the "old" #method method usage. The reason why I mention that in the "dot-colon" context, is the fact that due to the syntax sugar addition, this style of coding will surely be used more intensely.
Note: This feature has been reverted. See details here: bugs.ruby-lang.org/issues/16275.
Note: Benchmarks and the optimization approach still applies to the #method method usage.
One of the most interesting for me features of the upcoming Ruby 2.7 is the syntax sugar for the method reference. I like using the #method method together with the #then (#yield_self) operator in order to compose several functions in a "pipeline" like fashion. It's particularly useful when you process data streams or build ETL pipelines.
Here's an example of how you could use it:
class Parse
def self.call(string)
string.to_f
end
end
class Normalize
def self.call(number)
number.round
end
end
class Transform
def self.call(int)
int * 2
end
end
# Simulate a long-running data producing source with batches
# Builds a lot of stringified floats (each unique)
stream = Array.new(10_000) do |i|
Array.new(100) { |i| "#{i}.#{i}" }
end
stream.each do |batch|
batch
.map(&Parse.:call)
.map(&Normalize.:call)
.map(&Transform.:call)
end
It's nice, it's clear, it's short. So what is wrong with it?
Well, what is wrong is Ruby itself. Each time you reference a method using the #method method, Ruby gives you a new instance of a #Method class. Even when you're fetching the method of the same instance of an object. That's not all! Since we're using the & operator, each of the fetched method references is later on converted into a Proc object using the #to_proc method.
nil.:nil?.object_id #=> 47141222633640 nil.:nil?.object_id #=> 47141222626280 nil.:nil?.object_id #=> 47141222541360 # In general nil.:nil?.object_id == nil.:nil?.object_id #=> false nil.:nil?.to_proc == nil.:nil?.to_proc #=> false
It means that when you process a lot of data samples, you may spin up a lot of objects and pay a huge performance penalty. Especially when you operate on a per entity basis:
stream.each do |batch|
batch.each do |message|
message
.then(&Parse.:call)
.then(&Normalize.:call)
.then(&Transform.:call)
end
end
If you run the same code as above, but in a way like this:
stream.each do |batch|
batch.each do |message|
Transform.call(
Normalize.call(
Parse.call(message)
)
)
end
end
you end up having 12 million fewer objects and you will be able to run your code almost 10 times faster!
See for yourself:
require 'benchmark/ips'
GC.disable
class Parse
def self.call(string)
string.to_f
end
end
class Normalize
def self.call(number)
number.round
end
end
class Transform
def self.call(int)
int * 2
end
end
# Builds a lot of stringified floats (each unique)
stream = Array.new(10_000) do |i|
Array.new(100) { |i| "#{i}.#{i}" }
end
Benchmark.ips do |x|
x.config(time: 5, warmup: 1)
x.report('std') do
stream.each do |batch|
batch.each do |message|
Transform.call(
Normalize.call(
Parse.call(message)
)
)
end
end
end
# This case was pointed out by Vladimir Dementyev
# See the comments for more details
x.report('std-then') do
stream.each do |batch|
batch.each do |message|
message.then do |message|
Parse.call(message)
end.then do |message|
Normalize.call(message)
end.then do |message|
Transform.call(message)
end
end
end
end
x.report('dot-colon') do
stream.each do |batch|
batch.each do |message|
message
.then(&Parse.:call)
.then(&Normalize.:call)
.then(&Transform.:call)
end
end
end
x.compare!
end
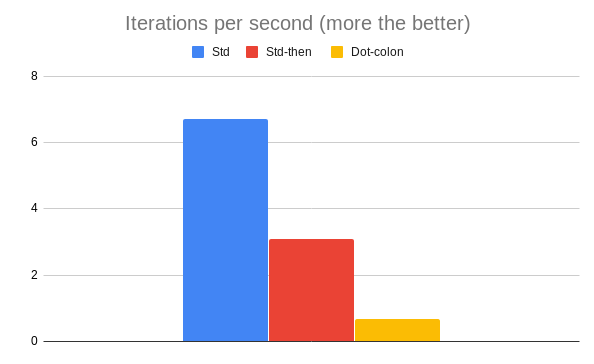
Results:
Warming up --------------------------------------
std 1.000 i/100ms
std-then 1.000 i/100ms
dot-colon 1.000 i/100ms
Calculating -------------------------------------
std 6.719 (± 0.0%) i/s - 34.000 in 5.060580s
std-then 3.085 (± 0.0%) i/s - 16.000 in 5.187639s
dot-colon 0.692 (± 0.0%) i/s - 4.000 in 5.824453s
Comparison:
std: 6.7 i/s
std-then: 3.1 i/s - 2.18x slower
dot-colon: 0.7 i/s - 9.70x slower
Same for the allocation of the objects:
tao1 = GC.stat[:total_allocated_objects]
stream.each do |batch|
batch.each do |message|
Transform.call(
Normalize.call(
Parse.call(message)
)
)
end
end
tao2 = GC.stat[:total_allocated_objects]
stream.each do |batch|
batch.each do |message|
message.then do |message|
Parse.call(message)
end.then do |message|
Normalize.call(message)
end.then do |message|
Transform.call(message)
end
end
end
tao3 = GC.stat[:total_allocated_objects]
stream.each do |batch|
batch.each do |message|
message
.then(&Parse.:call)
.then(&Normalize.:call)
.then(&Transform.:call)
end
end
tao4 = GC.stat[:total_allocated_objects]
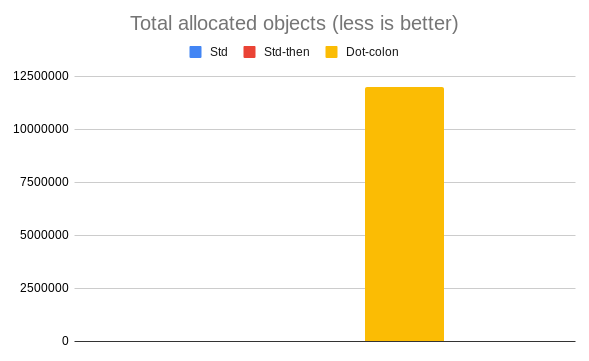
p "Std allocated: #{tao2 - tao1}"
p "Std-then allocated: #{tao3 - tao2}"
p "Dot-colon allocated: #{tao4 - tao3}"
Std allocated: 1 Std-then allocated: 2 Dot-colon allocated: 12000002
So, shouldn't we use the new feature (and method reference in general) at all? Not exactly. There are two things you need to do if you want to use it and not slow down your application that much.
Memoize your method references
Instead of fetching the method reference for each of the objects (or batches), fetch it once and re-use:
parse = Parse.:call
normalize = Normalize.:call
transform = Transform.:call
stream.each do |batch|
batch.each do |message|
message
.then(&parse)
.then(&normalize)
.then(&transform)
end
end
This will save you from creating 3 milions objects and will make your code 7 times slower than the base one.
Convert the memoized methods into procs
Since Ruby will do that for you anyhow (in a loop), why not be smarter and do it for him:
parse = Parse.:call.to_proc
normalize = Normalize.:call.to_proc
transform = Transform.:call.to_proc
stream.each do |batch|
batch.each do |message|
message
.then(&parse)
.then(&normalize)
.then(&transform)
end
end
This will make the code above only 2.5 times slower than the base one (usually it's fine), and at the same time, it will save you almost all out of the 12 milion additional objects!
Dot-colon and the method reference further development
Some of you might know that I've been involved a bit in this feature. I proposed and submitted a patch, that will make the .: Method object frozen. It may seem like not much, but freezing keeps a window of opportunity for introducing method reference caching in case it would be needed because the method object is immutable.
This proposal was an aftermath of my discussion with Ko1 and Matz this summer in Bristol. When using the #method method (not the syntax-sugar), due to the backwards compatibility (that I hope will be broken in this case), the Method instance is not frozen. However, the .: will be. It's a rare corner case (why would you even want to mutate an object like that?), but it does create a funny "glitch":
nil.:nil? == nil.method(:nil?) #=> true nil.:nil?.frozen? #=> true nil.method(:nil?).frozen? #=> false
Note: I'm planning to work on adding the last-method cache after the 2.7 is released and after I'm able to statistically justify that the majority of cases are as those presented above.

Cover photo by Rahel Samanyi on Attribution 2.0 Generic (CC BY 2.0) license.

