I'm a quite happy Synology user. For the past years I've been using it mostly to backup my things, so I didn't pay much of an attention to the fact, that the Photo Station software would get slower and slower up to the point when I would end up with "Failed to load data" message each time I would access it.
Some articles suggested that you have to drop and re-create the media indexing database to fix it. However, this won't help you in the long run. Your Photo Station 6 database will become bloated once again after a while.
The reason, why Photo Station 6 gets slower and slower, is the fact that Synology, for any crazy reason disabled the PostgreSQL AutoVacuum functionality. Vacuuming is suppose to keep your database in a good state
How to fix that once and for all? You need to enable the PostgreSQL AUTOVACUUM and for an immediate effect, you should also run the vacuuming manually.
SSH into your server and then:
sudo su cd /volume1/@database/pgsql vim postgresql.conf
Within the postgresql.conf file replace (or add if they don't not exist) following settings:
wal_buffers =128MB autovacuum = on checkpoint_segments = 10
save, exit the file and reboot.
If you want to run vacuuming manually, log in into the PostgreSQL console:
psql -U postgres
List available databases:
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-------------+----------------------------+-----------+---------+-------+-----------------------
mediaserver | MediaIndex | SQL_ASCII | C | C |
ong | SynologyApplicationService | SQL_ASCII | C | C |
photo | PhotoStation | SQL_ASCII | C | C |
postgres | postgres | SQL_ASCII | C | C |
synosnmp | postgres | SQL_ASCII | C | C |
template0 | postgres | SQL_ASCII | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | SQL_ASCII | C | C | postgres=CTc/postgres+
| | | | | =c/postgres
Connect to the photo DB:
postgres=# \c photo; You are now connected to database "photo" as user "postgres".
Check the tables size by running the following query:
SELECT nspname || '.' || relname AS "relation",
pg_size_pretty(pg_total_relation_size(C.oid)) AS "total_size"
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
AND C.relkind <> 'i'
AND nspname !~ '^pg_toast'
ORDER BY pg_total_relation_size(C.oid) DESC
LIMIT 5;
relation | total_size
----------------------+------------
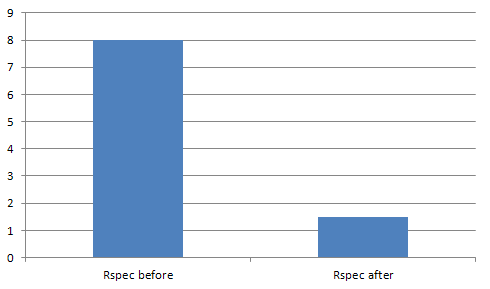
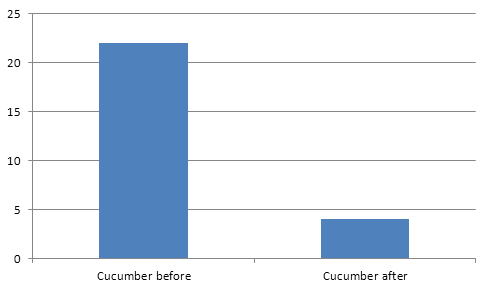
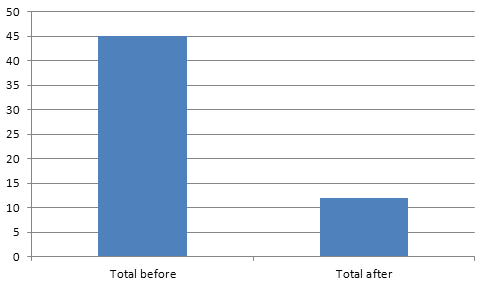
public.photo_image | 1097 MB
public.photo_log | 5912 kB
public.video_convert | 936 kB
public.photo_share | 928 kB
public.video | 864 kB
(5 rows)
and the potential vacuuming candidate should be obvious by now:
photo=# vacuum full public.photo_image; VACUUM
Re-run the size checking query again just to see 93% size reduction of the images table:
relation | total_size
----------------------+------------
public.photo_image | 72 MB
public.photo_log | 5912 kB
public.video_convert | 936 kB
public.photo_share | 928 kB
public.video | 864 kB
(5 rows)
After that, everything will work blazing fast!