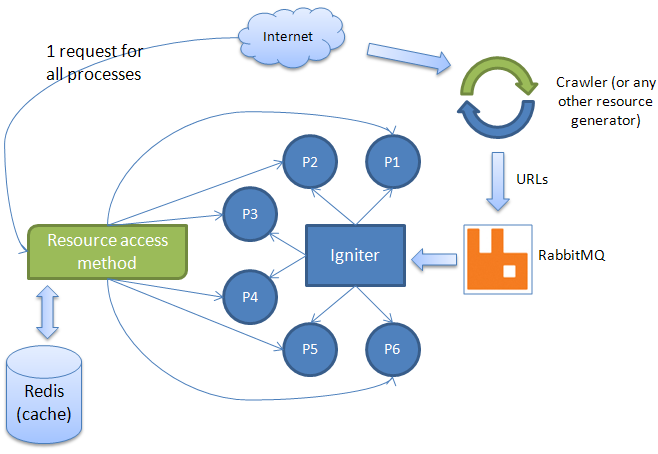
There are times, when you need to share some data between multiple processes, one of the ways is to use Redis. Not so long ago I've been working with an application which performs some types of calculations based on a crawled websites. Crawler pulls URLs from a page and sends them to a RabbitMQ. Then a worker is fetching those URLs and ignites multiply calculating processes (each of them is independent from the others - they just use the same dataset). They should use same dataset but to be honest... they didn't. Each process has been downloading same website over and over again, so instead of a page been downloaded one time - it has been downloaded minimum N times (N is a number of processes working with that page). That was insane! Each page was analyzed by all the processes only once and max time needed to handle those calculations was approximately 10-15 minutes (with 10 processes). A quite big amount of time was devoted to a page download.
Below you can see how it was working before optimization:
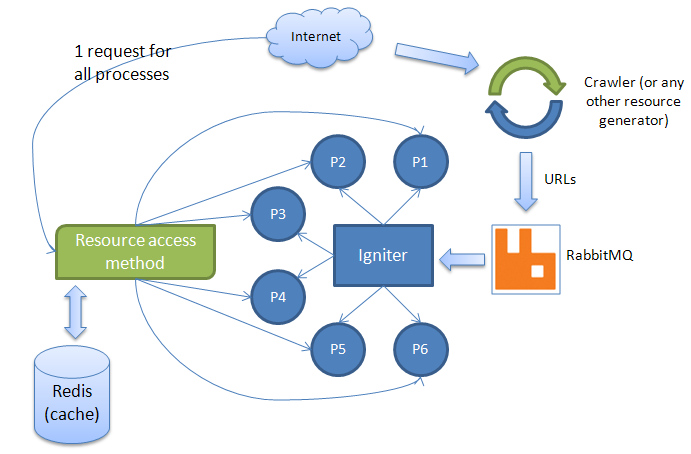
And how it should work:
As you can see above, there is one method which communicates with Redis. It should try to retrieve a cached page (or any other resource you want to store) and if it fails, it should download this page directly from the Internet. As mentioned before, data should stay in Redis for a certain amount of time (max 15 minutes). Further more I don't want to take care of expired data. Would if be greate if data could just "magically" dissapear? It certainly would!
Redis key expiration
On each Redis key we can set a timeout. After the timeout has expired, the key will automatically be deleted. You can set expiration time like this (example from Redis doc):
redis> SET mykey "Hello"
OK
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 10
redis> SET mykey "Hello World"
OK
redis> TTL mykey
(integer) -1
redis>
We will store pages in Redis and set TTL on 15*60 seconds (15 minutes).
Connecting Ruby to Redis
Making Ruby work with Redis is really easy. There is a gem called "redis", which is quite simple to use:
require 'rubygems'
require 'redis'
options = {
:timeout => 120,
:thread_safe => true
}
host = ENV["REDIS_HOST"] || 'localhost'
port = ENV["REDIS_PORT"] || 6379
db = ENV["REDIS_DB"] || 2
options.merge!({ :host => host, :port => port, :db => db })
redis = Redis.connect(options)
redis.set "my_key", "value"
p redis.get "my_key" # => "value"
Creating our main class
Source code is self explaining:
class WebPage
attr_reader :redis, :ttl
def initialize(redis, ttl = 5)
@redis = redis
@ttl = ttl
end
# Read page
def read(url)
# Try to get page content from radis
# and if it fails
unless d = get(url)
# Just open it and read
d = open(url).read
set(url, d)
end
d
end
private
# Set url key with page content
def set(url, page)
k = key(url)
@redis.set(k, page)
@redis.expire(k, @ttl)
end
# Get data from a Redis key (null if failed)
def get(url)
@redis.get(key(url))
end
# Prepare redis key for a certain url
def key(url)
"webpage:#{Digest::MD5.hexdigest(url)}"
end
end
Of course if you want to use this in production, you should include also SSL (https) support and error handling (404, 500, timeouts, etc).
Performance benchmark
I've prepared a simple chart, where you can see performance boost when requesting same page over and over again (Redis cache benchmark source code):
To minimize temporary CPU load overhead (some random requests to my dev server, etc), I've repeated test set 10 times and I've averaged data so it should be quite reliable.
Making 100 requests takes about 6.5 seconds. Making 100 requests with cache takes about 0.09 second! It is 72 times faster!
Summary
Caching data is really important and differences can be really big (10, 100, 1000 times faster with caching enabled!). If you design any type of application, always think about caching as the one of the ways to speed it up.


{kind=link}