There are cases where you have a compressed GZIP file for which you want to determine the uncompressed data size without having to extract it.
For example, if you work with large text-based documents, you can either display their content directly in the browser or share it as a file upon request depending on the file size.
+=======================+
|...compressed blocks...| (more-->)
+=======================+
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| CRC32 | ISIZE |
+---+---+---+---+---+---+---+---+
ISIZE (Input SIZE)
This contains the size of the original (uncompressed) input
data modulo 2^32.
It means that as long as the uncompressed payload is less than 4GB, the ISIZE value will represent the uncompressed data size.
You can get it in Ruby by combining #seek, #read and #unpack1 as followed:
# Open file for reading
file = File.open('data.gzip')
# Move to the end to obtain only the ISIZE data
file.seek(-4, 2)
# Read the needed data and decode it to unsigned int
size = file.read(4).unpack1('I')
# Close the file after reading
file.close
# Print the result
puts "Your uncompressed data size: #{size} bytes"
Cover photo by Daniel Go on Attribution-NonCommercial 2.0 Generic (CC BY-NC 2.0). Image has been cropped to 766x450px.
Year and a half ago, I was working with a software that used Redis as a buffer to store large sets of text data. We had some bottlenecks there. One of them was related to Redis and the large amount of data, that we had there (large comparing to RAM amount). Since then, I've wanted to check if using Zlib library would be a big improvement or would it be just a next bottleneck (CPU). Unfortunately I don't have access to this software any more, that's why I've decided to create a simple test case just to check this matter.
Approach
We mostly did read operations from Redis (the data was inserted and it was used many times through the cache life cycle), however I've wanted to test as many cases as I could, that's why I've tested following cases (each of them is tested with and without compression):
Read only operations
Write only operations
Read/write operations
I've also considered given data sets:
empty file source
small file source (16.6 kB)
medium file source (47.5 kB)
big file source (221.9 kB)
large file source (4.2 MB)
To make it quite accurate I've tested it 10 times for given case and also for different number of iterations (from 1 to 1000). You can check the results on charts below.
Hardware
Hardware used was rather simple:
2 GB RAM
Pentium 4 HT
2TB SATA WD Disk
Unstressed Debian Linux on board
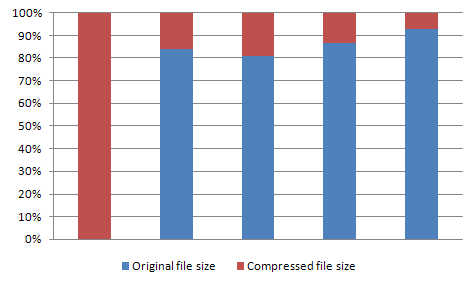
Memory gain due to compression
The memory gain is quite obvious - it depends on the compression level that we can achive using Zlib library. Below you can see the memory usage before and after compression - for all the given example files:
So, as you can see, except the first case, with the empty file, we gain around 75-85% of space, when using the Zlib compression of text data. In my opinion this is a huge improvement.
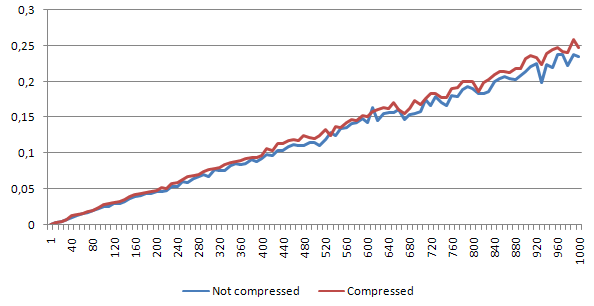
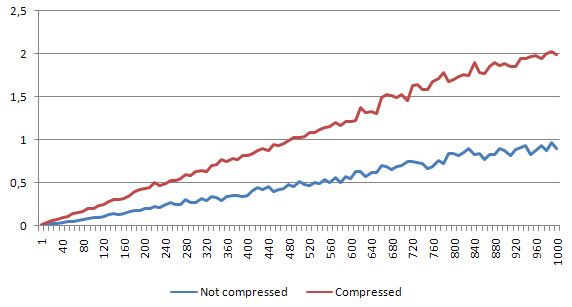
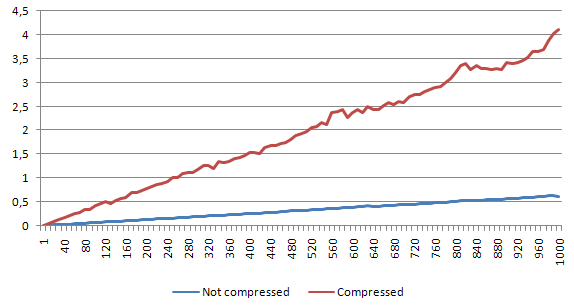
The read-only test case
First let's see how the read-only performance decreases due to the compression mechanism that was implemented. On the chart we can see both - the non-compressed and compressed script versions, both for given (same) number of iterations. Each chart represents one file size.
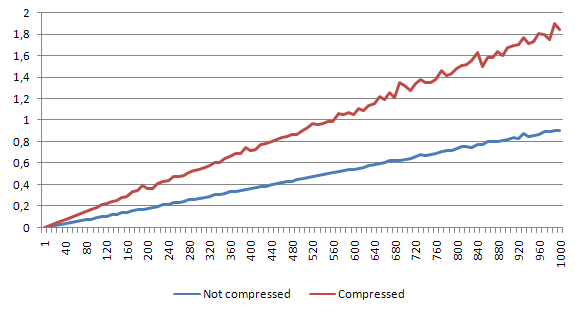
Empty file
For empty file, the speed decrease is around 6%.
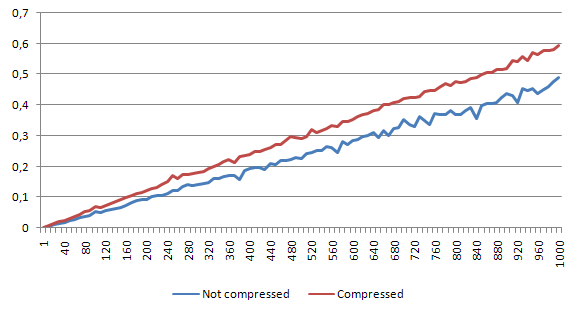
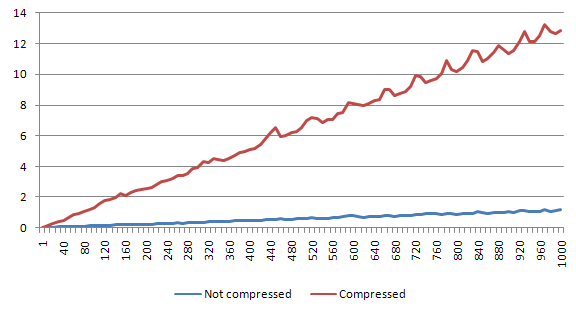
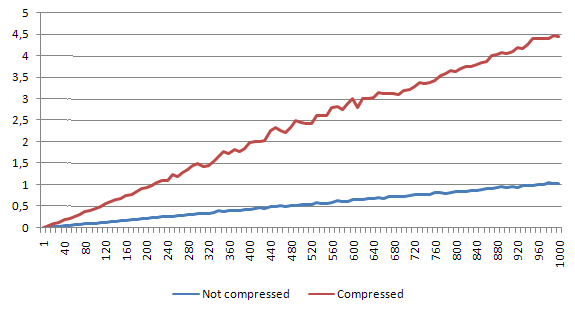
Small file
For small file, the speed decrease is around 26%. But still - 1000 reads take us less than a half of second.
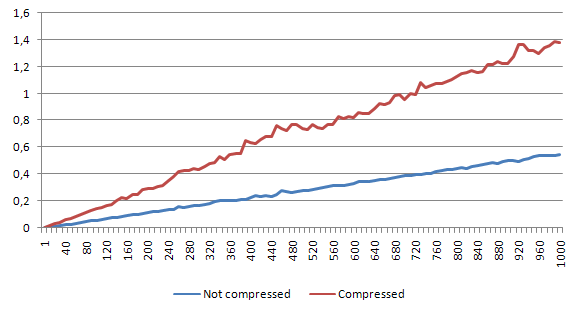
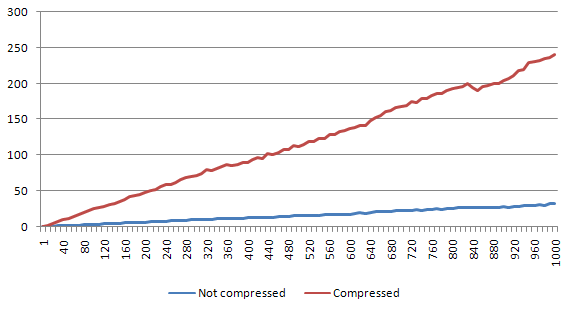
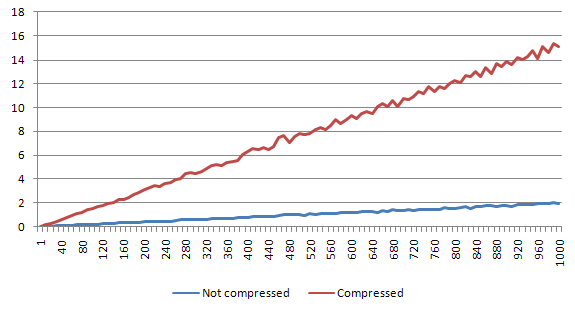
Medium file
Here the difference is around 47.5% - the bigger the file gets, the bigger the decompression overhead is. Since the read operations from Redis are quite fast, the decompression time seems to affect the whole process in a quite high level.
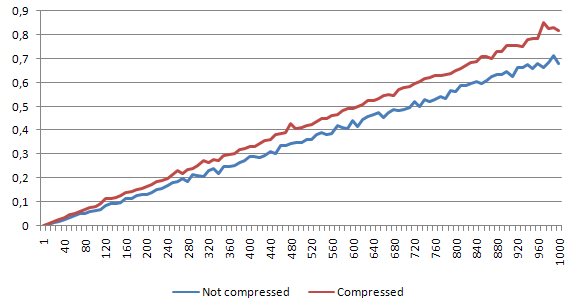
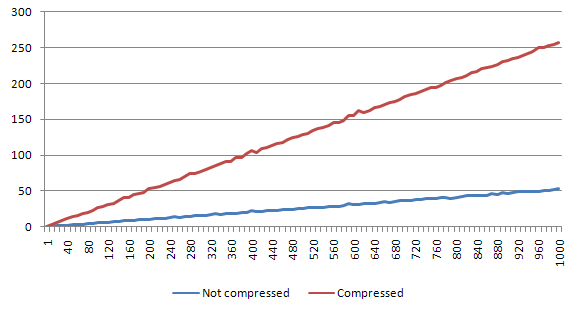
Big file
Diffence is around 55%. Which is still tolerable. Of course if we would do a lot of readings that should be performed really fast - this would be a problem.
Large file
Difference is around 33.5%, which is quite weird, since it is lower than with the previous smaller file.
Read-only summary
As you can see above, the decompression overhead is around 30-50%. Is it much? It depends what you are doing. If you are ready to exchange such a speed loss for a memory saving, this might be the solution for you (of course for now we are talking about the read-only scenario).
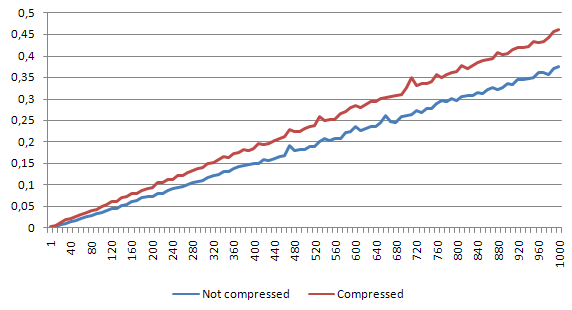
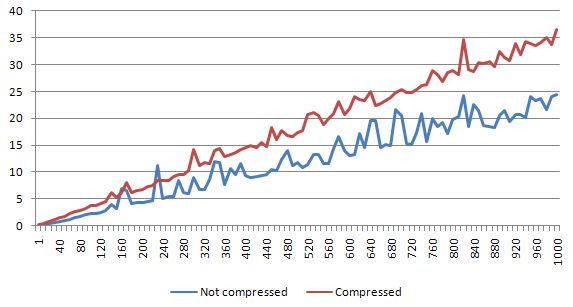
The write-only test case
Empty file
Difference is around 29%. Seems like the compression impact comparing to decompression is way bigger (nearly 5 times). This doesn't look good for the write-only test case, however let's see more examples.
Small file
Difference is around 161%. This is huge difference - even with small data amounts, compression seams to really influence the write process.
Medium file
Difference is around 520%. No comments here - this level is way beyond the heavy duty usage tolerance level. With such a difference, using compression on heavy-write system would be
Big file
Difference is around 1063%.
Large file
Difference is around 675%.
Write-only summary
It seems like the heavy duty write-only usage with Zlib compression won't be a good idea. The time spent compressing the input data is way beyond any acceptable level. Write process increases so much, that it would be way better to use storage that has compression already implemented (or one that is not in-memory).
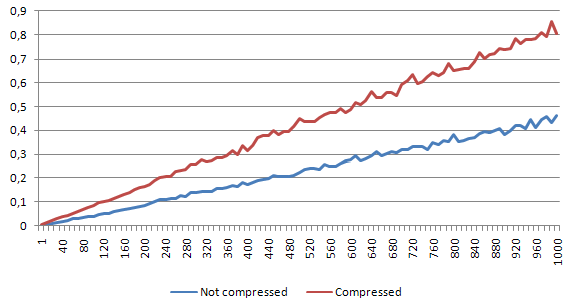
Read-write test case
This is the last test case. I've performed one write per 1 read.
Empty file
Difference is around 19.8%.
Small file
Difference is around 104%.
Medium file
Difference is around 350%.
Big file
Difference is around 667%.
Large file
Difference is around 402%.
Read-write summary
It looks like the write process slowed the whole program in a big way. This is a second case that shows, that we should not use this approach in a heavy-write environment
Overall summary
First of all, if you have such a problem at the beginning of your software development, probably you should use a different data-storage (if you plan to have more data than you can handle in memory). This article and the compression "tweak" that I've tried to check/use should be implemented only when you don't have any other option and the Redis memory usage is your biggest bottleneck. Also, you should not try to use this idea when you do a lot of writing to Redis and a only few reads per data chunk. This would slow down your software dramatically. Of course if you do less than few hundred operations per second, you probably would not feel this, but still, try to think about future issues as well.
On the other hand, it seems that when we have an application that uses Redis mostly for reading stuff from it, we might think about compressing the input data. However as I mentioned before - try not to overdo it and implement such a mechanism only when you really need it.
To be honest, I'm a bit disappointed. I thought, that using the compression would not be such a big overhead, however it seems like Redis is way faster than I thought comparing to compression process.