After we've added RSpec and Cucumber (with PhantomJS) to our CI build process, it got really, really slow. Due to the application character, after each scenario (for Cucumber) we truncate and restore the whole database. 45 minutes for a single build is definitely not what we aimed to get. So, how to speed up tests execution?
First we thought, that we could run RSpec and Cucumber stuff in parallel (using parallel tests gem). We've got a much better machine on AWS to make sure that a single process has a single core to use. Unfortunately everything got... slower. We've decided to pinpoint a single RSpec spec and a single Cucumber scenario that would be representative and figure out what the hell. What we've discovered at the beginning, is that all the specs were running faster on the Ruby level. It all got significantly slower because of the database. Our tests were heavy in terms of DB communication and as I said before, due to it's character, it will probably stay that way.
So, what were our options?
- We could get a much better hardware for our testing DBs. Bigger, faster, with SSD, however it would definitely make things more expensive
- We could compromise data consistency. Since it is a testing cluster - in case of a system failure / crash /shutdown, we can just drop all the databases and repopulate them again
We've decided to try out the second approach and use fsync PostgreSQL flag to tweak this database a little bit.
What is fsync (quote from PostgreSQL documentation)?
If this parameter is on, the PostgreSQL server will try to make sure that updates are physically written to disk, by issuing fsync() system calls or various equivalent methods (see wal_sync_method). This ensures that the database cluster can recover to a consistent state after an operating system or hardware crash.
While turning off fsync is often a performance benefit, this can result in unrecoverable data corruption in the event of a power failure or system crash. Thus it is only advisable to turn off fsync if you can easily recreate your entire database from external data.
Examples of safe circumstances for turning off fsync include the initial loading of a new database cluster from a backup file, using a database cluster for processing a batch of data after which the database will be thrown away and recreated, or for a read-only database clone which gets recreated frequently and is not used for failover. High quality hardware alone is not a sufficient justification for turning off fsync.
Results were astonishing! Since we're no longer as much dependent on our HDDs performance for each operation, the database layer does not slow us down that much.
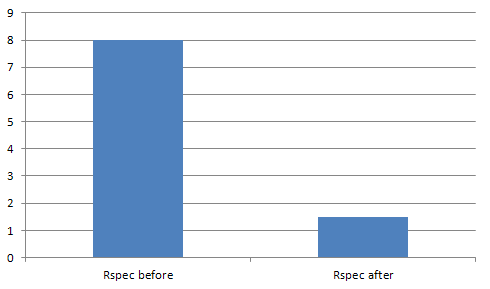
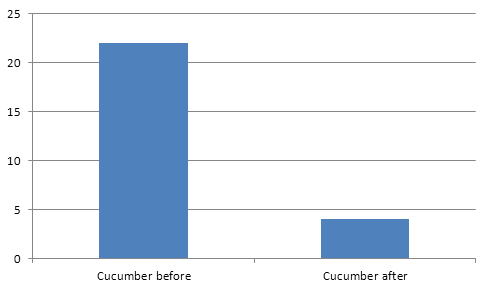
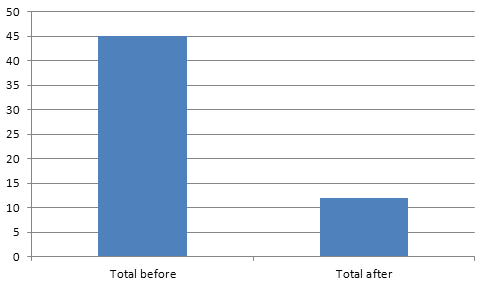
Overall thanks to this tweak and parallel execution, we've managed to get down from 45 minutes for a whole build, down to 12 minutes. That is 75% faster than before and this build time is acceptable for us.
Research done by: Adam Gwozdowski