I'm proud to announce that we've released a new shiny version of Karafka: .
In this article I will cover all the important changes and new features that you will be able to use.
Karafka? But what is it?
Karafka provides a higher-level abstraction than raw Kafka Ruby driver. Instead of focusing on single topic consumption, it provides developers with a set of tools that are dedicated for building multi-topic applications similarly to how Rails applications are being built.
Important changes
Here are the most important changes that were made (whole list available in the changelog):
- Responders for nicer pipelining and better responses flow description and control
- Automatic Capistrano integration
- karafka flow CLI command for printing the application flow
- Moved from Poseidon into Ruby-Kafka
- Zookeeper (ZK) no longer as a dependency
- Automatic thread management (no need for tunning) - each topic is a separate actor/thread
- Manual consuming is no longer available (no m ore karafka consume command)
- We're finally on RubyGems
- karafka topics no longer available
- Ruby 2.2.* support dropped
Responders concept for nicer pipelining and better responses flow description and control
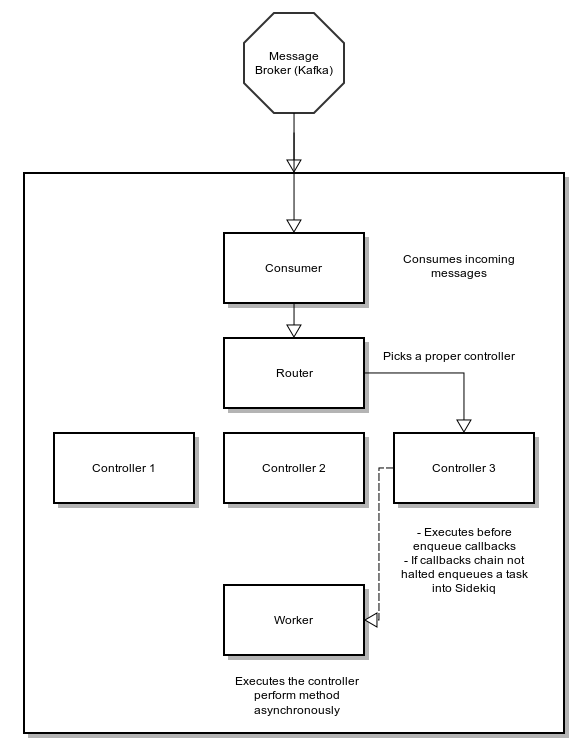
Change that we're most proud of. A brand new, shiny concept that allows you to design applications that not only receive messages but can respond to them after performing your business logic!
Here's a quick example (before I get into details) on how this concept looks:
class UsersCreateController < KarafkaController
def perform
respond_with User.create!(params[:user])
end
end
end
class UsersCreateResponder < ApplicationResponder
topic :users_created, required: true
topic :users_premium_created, optional: true
def process(user)
respond_to :users_created, user
respond_to :users_premium_created, user if user.premium?
end
end
It's no longer HTTP. It's no longer a single response
Most web programmers are used to a nice and predictable flow: single request, single response. It is easy to test, it works and in many cases it is enough. Unfortunately the more complex IT software gets, the more often it is not enough. And that's exactly why we've implemented the Responders concept.
Now you will have a single entry-point (topic's message) but you can generate response on as many topics as you want in reaction to what you did with the incoming data.
Well I could do that already with Karafka + Producer client
That is true. However without clear boundaries on what should happen where, less experienced programmers will start developing less stable, more complicated apps. When you do that manually, there's also no validation layer that will ensure that you responses were sent to where you wanted them in the first place.
Where can I use it?
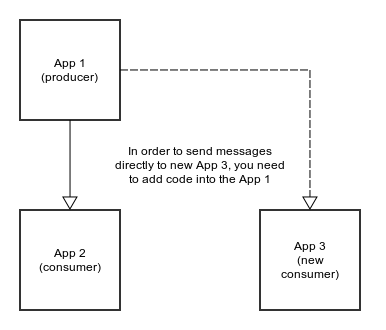
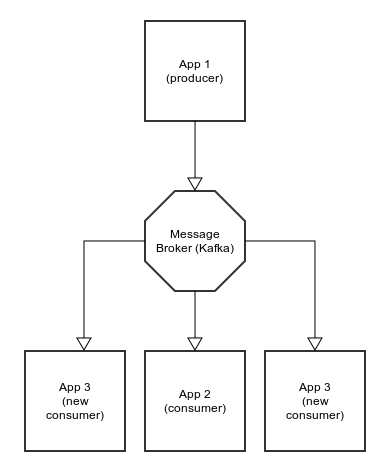
Karafka responders allow you to build more reliable Ruby+Kafka SOA systems, that not only receive messages but also generate messages based on results of the app business logic. They work great in distributed systems that are built using SOA. Having Kafka as a message bus gives you a unique opportunity to treat your whole ecosystem like a huge pipeline. You can accept messages and preprocess them in one app. Then send the results into many other systems. The best thing is that apart from the topic (or topics) to which you send your results, your preprocesing app does not need to know anything about other applications.

Approach like that is great when you have event based systems that need to take many actions upon a single event. Let's assume for a second that you have a huge monolithic application that upon a new user registration:
- sends him an email
- connects to his server (via SSH or anything else)
- downloads some informations
- analyzes received data
- sends a second email with the results
- sends a text-message to someone else if the analysis results are bad (whatever that might mean)
Wouldn't it be better to split such an app into couplse sub-apps that would be parts of such a flow?

Here's an example from one of the apps that I work with, with such a flow (input => output) generated using karafka flow CLI command:
repositories_created => - sources_created: (always, exactly once) repositories_deleted => - sources_deleted: (always, exactly once) repositories_updated => - sources_updated: (always, exactly once) sources_refresh => - sources_refreshed: (conditionally, exactly once) - sources_disconnected: (conditionally, exactly once)
Responders API
The only thing that happens outside of a responder object, is it's controller invocation using #respond_with method. It accepts any number of arguments. Input of this method is forwarded to a proper responder.
class UsersCreateController < KarafkaController
def perform
respond_with User.create!(params[:user])
end
end
Registering responder
Karafka needs to be aware of which responder to use for a given topic. This can be achieved in two ways:
Registering responder for a given route:
class App < Karafka::App
routes.draw do
topic :repositories_created do
controller Repositories::CreatedController
responder Repositories::CreatedResponder
end
end
end
or by naming responder class as your controller class but with "Responder" postfix:
UsersCreatedController => UsersCreatedResponder UserActionsController => UserActionsResponder
If you follow this naming convention, you won't have to register responders at all. They will be assigned when a proper controller is being used.
Registering topic
Each topic that is going be to used needs to be register. It happens when responder class is defined using .topic method:
class RefreshResponder < ApplicationResponder topic :sources_refreshed, required: true # true by default topic :sources_disconnected, required: false end
.topic method accepts a second argument that allows to set two flages:
- required - Should we raise an error when a topic was not used (if required)
- multiple_usage - Should we raise an error when during a single response flow we sent more than one message to a given topic
Responding on topic
Once you register topics you want to work with, there's only one more thing to do: implement the #perform method in which you implement your responding logic. This method should accept exactly the same number of arguments as passed during the #respond_with invokation:
class CreatedResponder < ApplicationResponder
topic :sources_created
def respond(source)
respond_to :sources_created, source
end
end
In this method (as seen above) you can respond to a single registered topic using the #respond_to method. Note that if you pass something else than a string into it, Karafka will try to run a #to_json method on passed object. It means, that if you want to limit what is being send, you need to do this by yourself:
def respond(source) respond_to :sources_created, source.to_json(only: %i( id status )) end
For topics defined with multiple_usage flag set to true, you can invoke the #respond_to method multiple times:
class RegisteredTopicsResponder < ApplicationResponder
topic :new_topics, multiple_usage: true
def respond(topics)
topics.each do |topic|
respond_to :new_topics, topic
end
end
end
Karafka will raise an error when you'll:
- Try to use unregistered topic
- Try to use multiple times topic that was not registered with a multiple_usage flag
- Forget to use topic registered as a required one
That way you can control your flow much better.
Automatic Capistrano integration
Second most important change from a programmer perspective! Karafka has now a new and shiny Capistrano out-of-the-box integration. In order to make it work, just drop this line into your Capfile:
require 'karafka/capistrano'
Following Capistrano tasks are available:
cap karafka:restart # Restart Karafka cap karafka:start # Start Karafka cap karafka:status # Status Karafka cap karafka:stop # Stop Karafka
Hooks are added by default, so you really don't need to do anything.
If you want to personalize the flow, you can always disable default hooks by setting karafka_default_hooks in Capistrano to false:
set :karafka_default_hooks, false
Here are all the Capistrano configuration options with their defaults:
set :karafka_default_hooks, -> { true }
set :karafka_env, -> { fetch(:karafka_env, fetch(:environment)) }
set :karafka_pid, -> { File.join(shared_path, 'tmp', 'pids', 'karafka.pid') }
New CLI command for printing the application flow
New low-level Kafka driver - Ruby-Kafka
Poseidon that Karafka used is no longer maintained. It also lacks many features that were introduced in Kafka 0.9, so we had to replace it. With what? Obviously with new and shiny Ruby-Kafka gem. What does it mean for you as a Karafka user? Many things
- No more Kafka 0.8 support
- Better balancing for topics and partitions
- Support of Zendesk :-)
- Better performance
- Different thread management setup
- No need for ZK as a dependency
- Automatic cluster discovery from a single Kafka node
It's worth pointing out, that the GIL in MRI is removed for IO operations, so by using separate threads we can be truly parallel.
Bye bye Zookeeper
Zookeeper is no longer a Karafka dependency. It has few drawbacks, but on the other hand it allowed us to remove ZK gem and all our auto-discovery login. Things work now way better.
Threads? I don't want to care about that!
And you no longer have to. We've redesigned thread management completely and now a single connection has a long-running thread in which we constantly listen to a given topic. It means that there is no delay on receiving messages from multiple topics. You just don't have to worry about that anymore.

Will it work for bigger apps? Well we're currently running on production one that listens almost 100 topics and it works great!
No more manual consumption
Supporting manual consumption that could be incorporated into a rake task or a Sidekiq worker is no longer in Karafka. We've decided that it breaks the one of the concepts that is behind Karafka which is consuming messages as soon as possible.
It also means that following CLI command is no longer available:
bundle exec karafka consume
Hello RubyGems!
Some of you noticed, that Karafka is not being released on RubyGems. That is not true anymore. Karafka 0.5.0 is the first release also sent to RubyGems. Now you can do both:
gem install karafka
and in your Gemfile you can finally:
# replace this # gem 'karafka', github: 'karafka/karafka' # with gem 'karafka'
Goodbye karafka topics command!
We no longer use Zookeeper, so we're no longer able to list all the topics using it. That means that:
bundle exec karafka topics
Is removed and no longer available.
Goodbye Ruby 2.2.*
Karafka is using some Ruby 2.3 syntactic sugar, which means that you won't be able to install and use Karafka if you run Ruby 2.2 or older.
Summary
It's over a year, since the first Karafka commit and almost a year since the first working release and I can say that this release is one of the biggest we had. Kafka is getting more and more popular and hopefully Karafka will follow the same path :)