What is Karafka?
Karafka is a microframework used to simplify Apache Kafka based Ruby applications development. Up until now there was only a sending library called Poseidon and its extension called Poseidon Cluster that could be used to work with Kafka clusters. Unfortunately there was no Sinatra "like" framework to rapidly develop message based applications. Karafka goes beyond simple sending and receiving. It provides an environment to work with multiple topics and groups (for load balancing) in a MVC like way.
What is Apache Kafka?
A high-throughput distributed messaging system. Kafka is designed to allow a single cluster to serve as the central data backbone for a large organization. It can be elastically and transparently expanded without downtime. (description taken from Apache Kafka website).
Why even bother with messages when there is HTTP and REST?
Because HTTP does not provide broadcasting and Apache Kafka does. This means, that we can create multiple applications that "live" by consuming messages generated by hundreds of other applications inside of one ecosystem. And those applications generate their messages that can be consumed and processed by other endpoints.
Also, without a message broker, you have to make changes to both applications - one that produces messages (to send to a new app) and to the one that receives (obviously).
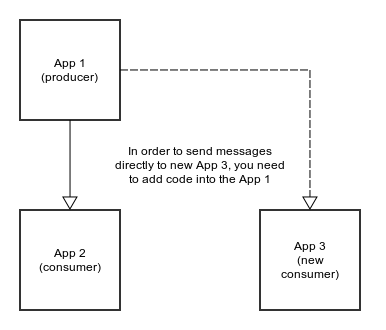 However, if you have a message broker, you can easily add more and more applications that consume and produce messages that could be used by any number of applications, without any additional changes to the producer. That way they are less dependent on each other.
However, if you have a message broker, you can easily add more and more applications that consume and produce messages that could be used by any number of applications, without any additional changes to the producer. That way they are less dependent on each other.
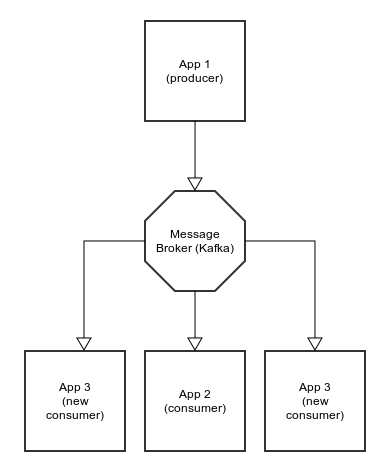
The next huge advantage of messaging is that producer app can be replaced by other, as long as they send understandable data (same format) into same topics. You can also use multiple applications that deliver information into the same topic, for example about users activities across all of your systems. You could have a single topic called users_activities that would track any user action.
Karafka ecosystem
Karafka framework is combined from 3 parts:
- Karafka - Framework used to build Kafka messages receiving applications in a similar way like Sinatra or Rails - with controllers and params
- WaterDrop - Library used to send messages to Apache Kafka from any Ruby based application (in a standard or aspect oriented way)
- SidekiqGlass - Sidekiq worker wrapper that provides optional timeout and after failure (reentrancy)
Karafka framework components
Apart of the implementation details, Karafka is combined from few logical parts:
- Messages Consumer (Karafka::Connection::Consumer)
- Router (Karafka::Routing::Router)
- Controller (Karafka::BaseController)
- Worker (Karafka::Worker)
They all act together to consume, route and process incoming messages: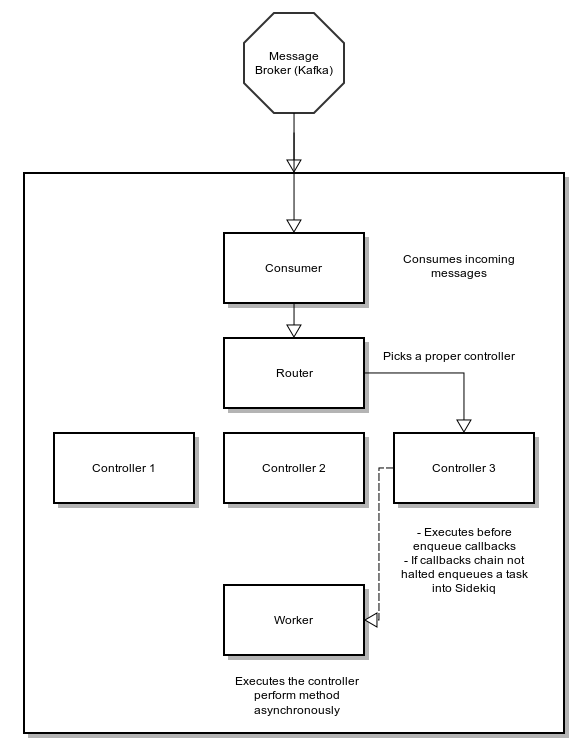
Why Sidekiq?
Performing business logic for each message can be time and resource consuming, so instead of doing it in the same process as data consumption, we use Sidekiq to schedule background tasks that will perform it. Also it is worth mentioning, that Sidekiq is well known, well tested and pretty stable. What do you need to do to enqueue Karafka tasks into Sidekiq? Nothing. Everything happens automatically, so you don't need to define any workers or schedule anything. Your controller and Karafka::Worker will do that for you. You just need to execute Sidekiq worker by running bundle exec rake karafka:sidekiq task. There's one more advantage in Sidekiq favour: scalability and performance. Sidekiq workers can be easily scaled both by number of threads and number of processed (and we can distribute them across multiple machines).
Scalability
Apart from scaling Sidekiq workers, Kafka also takes advantage of Poseidon Cluster library features. With a bit of magic it allows to create processes (applications) groups. You can think of them as of separate namespaces for processes. Kafka will ensure that a single message is delivered to a single process from each namespace (group). That way you can spin up multiple Kafka processes with "auto load balancing" support build in. Technically we could process everything in the Kafka app (without Sidekiq) although it would require building many more features that are already built into Sidekiq. There's just no need for wheel re-inventing.
Reentrancy
Karafka supports reentrancy for any task that is being executed in Sidekiq. You can read more about reentrancy here:
- Adding reentrancy and a on failure fallback for your Sidekiq workers
- Ruby (Rails, Sinatra) background processing – Reentrancy for your workers is a must be!
Rails like before filtering and params
Kafka allows you to preprocess messages before they are enqueued to Sidekiq. We use ActiveSupport::Callbacks to provide you with before_enqueue callbacks. They act in a similar way as before_action for Rails framework. There's just one difference: the callbacks chain will stop if there's a false value returned - which means that the Sidekiq task won't be schedule. This gives you possibility to filter out any "noise" that comes from Kafka.
before_enqueue do # Don't enqueue task for message that has a counter less than 1 and without a flag params[:counter] > 0 && params[:flag] end
The next thing that is similar to Rails is params usage. The params object (Karafka::Params::Params) is a ActiveSupport::HashWithIndifferentAccess descendant. Thanks to that, you can use the same approach as with any of your Rails/Sinatra applications:
def perform EventTracker.create(params[:event]) end
What Karafka is missing?
As for now, Karafka is a quite new tool and it is missing some features:
Celluloid listening(already there!)- Daemonization
Graceful shutdown (in progress)(already there!)Multithreading for controllers groups(already there!)Reloading in development environment (you have to restart the process to see your code changes)(works in console)
How can I use Karafka?
There's a pretty decent HOWTO in Karafka's README file. We're also planning to add an example app soon. I will also blog post with some usage examples of Karafka soon.
How can I test it?
Karafka can be tested with any Ruby test framework. It contains a plain Ruby code and you can just mock and stub anything you need.