Ruby developers have faced an uncomfortable truth for years: when you need to talk to external systems like Kafka, you're going to block. Sure, you could reach for heavyweight solutions like EventMachine, Celluloid, or spawn additional threads, but each comes with its own complexity tax.
EventMachine forces you into callback hell. Threading introduces race conditions and memory overhead. Meanwhile, other ecosystems had elegant solutions: Go's goroutines, Node.js's event loops, and Python's asyncio.
Ruby felt clunky for high-performance I/O-bound applications.
Enter the Async Gem
Samuel Williams' async gem brought something revolutionary to Ruby: lightweight concurrency that actually feels like Ruby. No callbacks. No complex threading primitives. Just fibers.
require 'async'
Async do |task|
# These run concurrently
task1 = task.async { fetch_user_data }
task2 = task.async { fetch_order_data }
task3 = task.async { fetch_metrics_data }
[task1, task2, task3].each(&:wait)
end
The genius is in the underlying architecture. When an I/O operation would normally block, the fiber automatically yields control to other fibers – no manual coordination is required.
Why Lightweight Concurrency Matters
Traditional threading and evented architectures are heavy. Threads consume a significant amount of memory (1MB stack per thread) and come with complex synchronization requirements. Event loops force you to restructure your entire programming model.
Fibers are lightweight:
Memory efficient: Kilobytes instead of megabytes
No synchronization complexity: Cooperative scheduling
Familiar programming model: Looks like regular Ruby code
Starting with the 2.8.7 release, every #produce_sync and #produce_many_sync operation in WaterDrop automatically yields during Kafka I/O. You don't configure it. It just works:
require 'async'
require 'waterdrop'
producer = WaterDrop::Producer.new do |config|
config.kafka = { 'bootstrap.servers': 'localhost:9092' }
end
Async do |task|
# These run truly concurrently
user_events = task.async do
100.times do |i|
producer.produce_sync(
topic: 'user_events',
payload: { user_id: i, action: 'login' }.to_json
)
end
end
# This also runs concurrently during Kafka I/O
metrics_task = task.async do
collect_application_metrics
end
[user_events, metrics_task].each(&:wait)
end
Real Performance Impact
Performance Note: These benchmarks show single-message synchronous production (produce_sync) for clarity. WaterDrop also supports batch production (produce_many_sync), async dispatching (produce_async), and promise-based workflows. When combined with fibers, these methods can achieve much higher throughput than shown here.
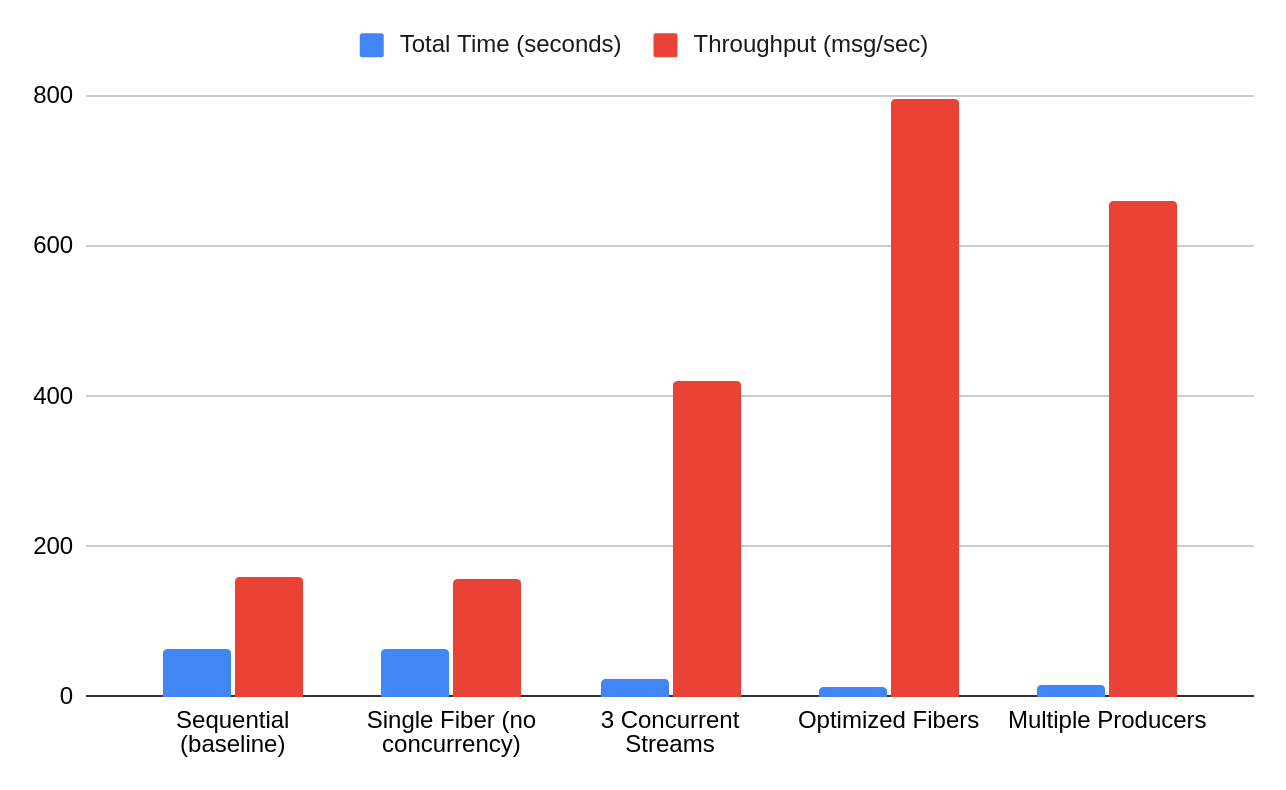
I benchmarked a Rails application processing 10,000 Kafka messages across various concurrency patterns:
Sequential processing (baseline):
Total time: 62.7 seconds
Throughput: 160 messages/second
Memory overhead: Baseline
Single fiber (no concurrency):
Total time: 63.2 seconds
Throughput: 158 messages/second
Improvement: 0.99x - No benefit without actual concurrency
Real-world scenario (3 concurrent event streams):
Total time: 23.8 seconds
Throughput: 420 messages/second
Improvement: 2.6x - What most applications will see in production
Improvement: 5.0x - Peak performance with proper structure
Multiple producers (traditional parallelism):
Total time: 15.2 seconds
Throughput: 659 messages/second
Improvement: 4.1x - Good, but uses more memory than fibers
A single producer using fibers outperforms multiple producer instances (5.0x vs 4.1x) while using less memory and resources. This isn't about making individual operations faster - it's about enabling Ruby to handle concurrent I/O elegantly and efficiently.
Transparent Integration
What makes WaterDrop's async integration cool is that it's completely transparent:
# This code works with or without async
producer.produce_sync(
topic: 'events',
payload: data.to_json
)
Running in a fiber scheduler? It yields during I/O. Running traditionally? It blocks normally. No configuration. No special methods.
The Transactional Reality
Transactions have limitations. Multiple transactions from one producer remain sequential due to the transactional.id design:
# These transactions will block each other
Async do |task|
task.async { producer.transaction { ... } }
task.async { producer.transaction { ... } } # Waits for first
end
But: transactions still yield during I/O, allowing other fibers doing different work to continue. For concurrent transactions, use separate producers.
Real-World Example
class EventProcessor
def process_user_activity(sessions)
Async do |task|
# Process different types concurrently
login_task = task.async { process_logins(sessions) }
activity_task = task.async { process_activity(sessions) }
# Analytics runs during Kafka I/O
analytics_task = task.async { update_analytics(sessions) }
[login_task, activity_task, analytics_task].each(&:wait)
end
end
private
def process_logins(sessions)
sessions.each do |session|
producer.produce_sync(
topic: 'user_logins',
payload: session.to_json
)
end
end
end
Why This Matters
WaterDrop's async integration proves Ruby can compete in high-performance I/O scenarios without sacrificing elegance. Combined with Samuel's broader ecosystem (async-http, async-postgres, falcon), you get a complete stack for building high-performance Ruby applications.
Try wrapping any I/O-heavy operations in Async do |task| blocks. Whether it's API calls, database queries, or Kafka operations with WaterDrop, the performance improvement may be immediate and dramatic.
Find WaterDrop on GitHub and explore the async ecosystem that's making Ruby fast again.
A few weeks have passed since RailsConf 2025, which was running from July 8th to 10th in Philadelphia, PA, and I've had time to process what was my first (and last) RailsConf experience. It wasn't just any RailsConf – it was the final edition after nearly 20 years of bringing together the Rails community. There's something poignant about attending what the organizers called "the last celebration" of Rails' longest-running conference.
After attending RubyKaigi 2025 in Matsuyama this past April, I was eager to compare it with RailsConf. RubyKaigi emphasizes Ruby internals and provides a unique bridge between Japanese and Western cultures, while RailsConf focuses on the Rails ecosystem and its diverse, dynamic community. With these experiences in mind, I approached RailsConf with excitement and curiosity about how it would distinguish itself.
Philadelphia was an excellent choice for this final gathering. The conference was held at Sheraton Philadelphia Downtown (201 N 17th St), right in the center of the city, making everything conveniently walkable. The organizers did an outstanding job securing accommodations at both the central conference hotel and The Logan Philadelphia nearby, ensuring plenty of space for attendees.
Getting There: From Kraków to the City of Brotherly Love
My journey to Philadelphia started early - a 6 AM flight from Kraków to Frankfurt, then onward to Philadelphia. I appreciated that the organizers chose a city accessible to international attendees. The East Coast location was particularly beneficial for European travelers like myself - the jet lag wasn't too punishing, coming from Poland.
I was apprehensive about border controls, which seem increasingly rigid these days, though I encountered no problems whatsoever. Philadelphia pleasantly surprised me with its cleanliness and surprisingly calm atmosphere, at least in the downtown area where the conference took place.
First Impressions: Heat, Humidity, and Hospitality
What immediately struck me was the oppressive weather – 36°C (97°F) with crushing humidity. Walking became a strategic exercise in shadow-hopping and route optimization. Despite the heat, the city had that distinctive American energy that I genuinely enjoyed with a European twist.
I have mixed feelings about hosting conferences directly in hotels where attendees stay. On one hand, it's incredibly convenient – you can grab a quick nap between sessions or drop off swag without leaving the building. On the other hand, it can create a bubble effect where you never really experience the host city. In this case, the convenience won out, especially given the weather.
Day 1: Technical Content and Community Connections
Day 1 was primarily about reconnecting with familiar faces and meeting new community members. There was one standout technical presentation about "The Ghosts of Action View Cache" that caught my attention for being genuinely technical and diving into implementation details.
Having just come from RubyKaigi, I had my expectations for technical depth calibrated relatively high. Coming from RubyKaigi, where presentations dive deep into Ruby internals and advanced topics, some of the RailsConf talks felt less technically dense. That's not to say the presentations weren't valuable – they addressed different needs. RailsConf has always been about the broader Rails ecosystem, including topics that might not interest hardcore Ruby internals folks but are crucial for the day-to-day work of Rails developers.
The evening was refreshingly low-key – we stayed in the hotel, shared some beers, and enjoyed conversations about the state of Rails and Ruby. Nothing spectacular, but precisely the kind of organic community building that makes conferences worthwhile.
Day 2: Past, Present, and Future Panel
Day 2 was the big day for me – I participated in a panel discussion with Mike, Rosa, and Ben about the past, present, and future of Ruby background processing engines. I can't objectively evaluate our performance since I was part of it, but the audience seemed engaged, and there was plenty of laughter, which I take as a good sign.
We managed to cover both our prepared talking points and several audience questions. I wish we'd had more time to delve deeper into technical implementation details, but RailsConf targets a broader audience than highly technical conferences like RubyKaigi.
One thing I noticed was how polite everyone was during the panel. Nobody complained about things that don't work well in the Ruby background processing ecosystem. While that makes for a pleasant discussion, it also means we might have missed opportunities to address real pain points that developers face daily. These could be a topic for a future blog post themselves.
The day also included hackathon–style breakout sessions with teams tackling different challenges. I ended up working on my projects and ideas – essentially a personal mini-hackathon to prototype a small application I'd been contemplating.
Meeting Karafka and Shoryuken Users
What made this day particularly special was connecting with the users of my open-source projects. I was thrilled to meet people using both Karafka and Shoryuken, and the positive feedback I received was incredibly energizing. There's something uniquely rewarding about putting faces to GitHub usernames and hearing firsthand how your work impacts other developers' daily lives.
Exploring Philadelphia: Food, Culture, and Conference Social Events
Between conference sessions, I managed to explore Philadelphia's highlights. The Rocky Steps at the Philadelphia Museum of Art were obligatory – you can't visit Philly without channeling your inner Rocky Balboa, however cliché it might be. The surrounding museum district offered beautiful architecture and a rich historical atmosphere perfect for wandering.
The culinary scene exceeded expectations. I particularly enjoyed some fish tacos from my Uber-recommended spot - perfectly spiced with just the right amount of heat, crispy texture, and fish that wasn't overly moist. Philadelphia's diverse food landscape offered far more than the stereotypical cheesesteaks, though I did sample those, too.
Conference Social Events
The Sidekiq-sponsored board games evening was brilliant. While I'm not typically a board game enthusiast, I was there for the beer and conversations – and both delivered. These kinds of informal gatherings often produce the best conversations and connections.
Day 3: Presentations and Concerns About AI
Day 3 brought on several compelling talks. I particularly enjoyed one about ActiveRecord migrations that was well-executed and informative.
But the highlight, as always when he's speaking, was Aaron Patterson's talk. Aaron has this unique ability to be simultaneously hilarious and thought-provoking. His presentation covered his previous talks and various loose thoughts about conferences and the Ruby ecosystem. While entertaining, he touched on a topic that's quite troubling for me: the impact of AI on the open-source environment.
Aaron's concerns mirror my own growing apprehensions. He argued that AI tools might inadvertently stifle innovation because the friction and pain points that typically drive developers to create better solutions will be papered over by AI assistance. Instead of solving problems that hurt developers, we might start offloading responsibility to these tools to work around issues rather than fixing them fundamentally. He gave the example of "convention over configuration" in Rails – a principle that emerged from the pain of XML configuration files. If LLMs had existed then, developers might have automated the XML generation rather than questioning whether XML configuration was the right approach at all.
It resonates with my concerns about AI's impact on tool selection and ecosystem diversity. If developers increasingly rely on AI recommendations, they'll likely choose the most popular tools - the ones the AI was trained on most heavily – rather than better, more innovative, or more suitable alternatives for specific use cases. It could cement the current landscape, making it increasingly difficult for new tools to gain adoption unless they fill an empty niche.
The risk is that instead of a diverse, evolving ecosystem where better solutions can emerge and gain traction, we might end up with a "frozen" developer landscape where the most popular tools become permanently entrenched simply because they're what AI tools recommend.
Day 4: RubyGems Team Meeting
While the official conference ended on Day 3, Day 4 brought an important RubyGems team meeting. It lasted about 2.5 hours and was incredibly productive. Having six of us in person was fantastic - there's something irreplaceable about face-to-face collaboration when you usually work distributed across different time zones.
We covered numerous topics about how RubyGems operates and what changes we need to make moving forward, including many operational aspects related to new platform policies. Some excellent improvements will come out of that meeting.
This kind of in-person collaboration is one of the most valuable aspects of conferences that people often overlook. While the talks get recorded and can be watched later, these impromptu meetings and discussions can only happen when everyone's in the same place.
Community Reflections: Age, Support, and the Future
Several things struck me about this final RailsConf, mostly positive and some concerning.
The Positive: The organization was excellent, Philadelphia proved to be a great host city, and the community spirit was strong. I received numerous warm comments about my open-source work, particularly Karafka and Shoryuken, and met users I'd never have encountered otherwise.
The sponsor's presence created a good atmosphere for meaningful connections with companies supporting the Rails ecosystem.
Many people expressed genuine interest in contributing to open-source projects, but seemed unaware of the challenges involved in maintaining a project over many years. It isn't criticism – it's more an observation about the gap between wanting to help and understanding what's involved in long-term project maintenance.
The Concerning: One observation that both struck and somewhat concerned me was the apparent aging of conference attendees. I'd estimate the average age at the conference was well over 35, possibly closer to 40. It could indicate several troubling trends:
Market conditions: The tech job market, particularly for junior developers, might be challenging enough that fewer younger developers are attending conferences.
Technology relevance: Ruby and Rails might not be attracting new developers the way they once did. This could be specific to the region (Philadelphia) or a broader trend.
Economic factors: Companies might not be funding conference attendance as readily, particularly for more expensive destinations requiring travel and accommodation.
The criticism I received about Karafka's pricing also highlighted an interesting disconnect. Some developers seemed to view the commercial aspects of open-source sustainability as problematic, despite the extensive free tier and the reality of what it takes to maintain enterprise-grade software over many years.
Final Thoughts: The Magic of In-Person Gatherings
RailsConf 2025 was a fitting finale to nearly two decades of Rails conferences. While different from RubyKaigi – less technically intense but more focused on community and practical applications – it served its purpose well as a gathering place for the Rails ecosystem.
The enduring magic of every conference lies in facilitating conversations and connections that simply cannot happen any other way. Despite all our advances in remote collaboration tools, they remain fundamentally limiting for certain types of relationship-building and knowledge transfer. Despite all the advances in remote work and virtual collaboration, there's still something irreplaceable about grabbing a beer with someone whose gem you depend on, or having an impromptu hallway conversation that sparks a new idea.
As Rails conferences transition to becoming tracks within RubyConf starting in 2026, I hope we don't lose the specific focus on the Rails ecosystem that made RailsConf valuable. The combination of community building, practical applications, and ecosystem updates served an essential role in keeping the Rails world connected.
While I miss the deep technical content that makes RubyKaigi special, RailsConf fulfilled a different but equally important role. It reminded me why I fell in love with the Rails community in the first place – not just for the technical excellence, but for the people who make it work.
Philadelphia truly lived up to its "City of Brotherly Love" reputation. The warmth of both the city and the Ruby community created a memorable experience that I'll carry forward as our community continues to evolve and adapt to new challenges and opportunities.
Here's to the next chapter of Rails conferences, and to the community that will keep Rails thriving for years to come.