Table of Contents
Introduction
Sometimes, we want to store our objects in files/database directly (not ORmapped or DRmapped). We can obtain this with serialization. This process will convert any Ruby object into format that can be saved as a byte stream. You can read more about serialization here.
Serializing stuff with Ruby
Ruby uses Marshal serialization. It is quite easy to use. If use use ActiveRecord, you can use this simple class to store objects in AR supported database:
class PendingObject < ActiveRecord::Base
# Iterate through all pending objects
def self.each
self.all.each do |el|
yield el, el.restore
end
end
# Marshal given object and store it on db
def store(object)
self.object = Marshal.dump(object)
self.save!
end
# "Unmarshal" it and return
def restore
Marshal.load(self.object)
end
end
Of course this is just a simple example of how to use serialization. Serialized data should be stored in a binary field:
t.binary :object
Mongo, Mongoid and its issues with serialization
Unfortunately you can't just copy-paste this ActiveRecord solution directly into Mongoid:
class PendingObject
include Mongoid::Document
include Mongoid::Timestamps
field :object, :type => Binary
# Iterate through all pending objects
def self.each
self.all.each do |el|
yield el, el.restore
end
end
def store(object)
self.object = Marshal.dump(object)
self.save!
end
def restore
Marshal.load(self.object)
end
end
It doesn't matter whether or not you use Binary or String in a field type decleration. Either way you'll get this as a result:
String not valid UTF-8
I can understand why this would happen with a String, but why when I set it as a binary value? It should just store whatever I put there...
Base64 to the rescue
In order to fix this, I've decided to use Base64 to convert serialized data. This has an significant impact on the size of each serialized object (30-35% more) but I can live with that. I was more concerned about the performance, that's why I've decided to test it. There are 2 cases what I've wanted to check:
- Serialization
- Serialization and deserialization (reading serialized objects)
Here are steps that I took:
- Create simple ruby object
- Serialize it 100 000 times with step every 1000 (without Base64)
- Serialize it 100 000 times with step every 1000 (with Base64)
- Benchmark creating of ruby simple objects (just as a reference point)
- Analyze all the data
Just to be sure (and to minimize random CPU spikes) I've performed test cases 10 times and then I took average values.
Benchmark
Benchmark code is really simple:
- Code responsible for iteration preparing
- DummyObject - object that will be serialized
- PendingObject - object that will be used to store data in Mongo
- ResultStorer - object used to store time results (time taken)
- Benchmark - container for all the things
- Loops :)
You can download source code here (benchmark.rb).
Results, charts, fancy data
First the reference point - pure objects initialization (without serialization). We can see, that there's no big decrease in performance, no matter how many objects we will initialize. Initializing 100 000 objects takes around 0.25 second.

Now some more interesting data :) Objects initialization and initialization with serialization (single direction and without base64):

It is pretty straightforward, that serialization isn't the fastest way to go. It might slowdown whole process around 10 times. But it's still like 2.5 seconds for 100 000 objects. Now lets see what will happen when we add a base64 to all of it (for a reference we will leave previous values on the chart as well):

It seems, that Base64 conversions will slow down the whole process about 10-12% max. It is still bearable (since for 100 000 objects its around 2.7s).
Now it is time for the most interesting part: deserialization. By "deserialization" I mean time that we need to convert a stream of bytes into objects (serialization time is not taken into consideration here):
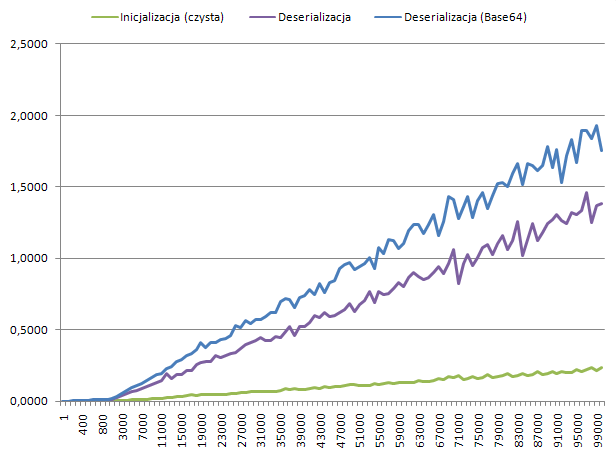
Results are quite predictable. Adding Base64 to the deserialization process, increases overall time required around 12-14%. As previously, it is an overhead that can be accepted - especially when you realize that even then, 100 000 objects can be deserialized in less than 2 seconds.
Lets summarize all that we have (pure initialization, serialization, serialization with Base64, deserialization, deserialization with Base64, serialization-deserialization process and the serialization-deserialization with Base64):

Conclusions
Based on our calculations and benchmarks we can see, that the overall performance drop when serializing and deserializing using Base64 is around 23-26%. If you're not planning to work with huge number of objects at the same time, the whole process will still be extremely fast and you can use it.
Of course if you can use for example MySQL with Binary - there is no need to use Base64 with it. But on the other hand, if you're using MongoDB (with Mongoid) or any other database that has some issues with Binary and you still want to store serialized objects in it - this is a way to go. If you consider also the bigger size of Base64 data, the total performance loss should not exceed 35%.
So: if you don't have time to look for a better solution and you will be aware of disadvantages of this solution - you can use it ;)
July 2, 2011 — 21:59
fajny art, chętnie bym przeczytał, może być w komentarzach, kiedy przykładowo stosowaliście serializację w realnych projektach ? kiedys się opłaca
July 4, 2011 — 00:09
Niedawno pisałem o tym jak można wykorzystywać serializację do “persistence” zamiast bazy danych. Zainteresowanych zapraszam na http://andrzejonsoftware.blogspot.com/2011/05/madeleine-with-rails.html