Lately I've fixed an issue with Mongoid driver (read more about this). Memory consumption stabilized at a relatively low level until... gem update mongo. Below you can see Munin memory and CPU consumption charts from a frontend server (frontend only presents data):
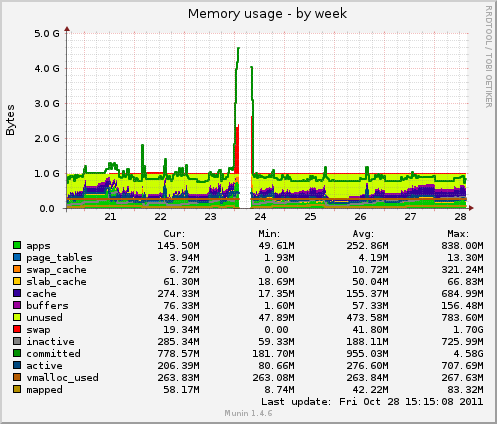

There were some heavy issues on october 23d. Server went really crazy. Behavior was similar to one mentioned in previous post about Mongoid. But IdentityMap has been turned off so WTF? Well I don't know what happend, but what do I know is how to fix it. Edit your Padrino/Sinatra app file (app/app.rb) and place this in your project class:
after do Mongoid::IdentityMap.clear end
This will clear IdentityMap after each request.
I know, that this is not the best solution, however it is good enough for me - and what's more important - it works fine.