Table of Contents
I am excited to announce the release of llm-docs-builder, a library that transforms Markdown documentation into an AI-optimized format for Large Language Models.
TL;DR: Open source tool that strips 85-95% of noise from documentation for AI systems. Transforms Markdown, generates llms.txt indexes, and serves optimized docs to AI crawlers automatically. Reduces RAG costs significantly.
If you find it interesting or useful, don't forget to star ⭐ the repo - it helps others discover the tool!
The Problem
If you have watched an AI assistant confidently hallucinate your library API – suggesting methods that do not exist or mixing up versions – you've experienced this documentation problem firsthand. When AI systems like Claude, ChatGPT, and GitHub Copilot try to understand your docs using RAG (Retrieval-Augmented Generation), they drown in noise.
Beautiful HTML documentation with navigation bars, CSS styling, and JavaScript widgets becomes a liability. The AI retrieves your "Getting Started" page, but 90% of what it processes is HTML boilerplate and formatting markup. The actual content? Buried in that mess.
Context windows are expensive and limited. Research shows that typical HTML documents waste up to 90% of tokens on pure noise: CSS styles, JavaScript code, HTML tag overhead, comments, and meaningless markup. This waste adds up fast across thousands of pages and millions of queries.
What llm-docs-builder Does
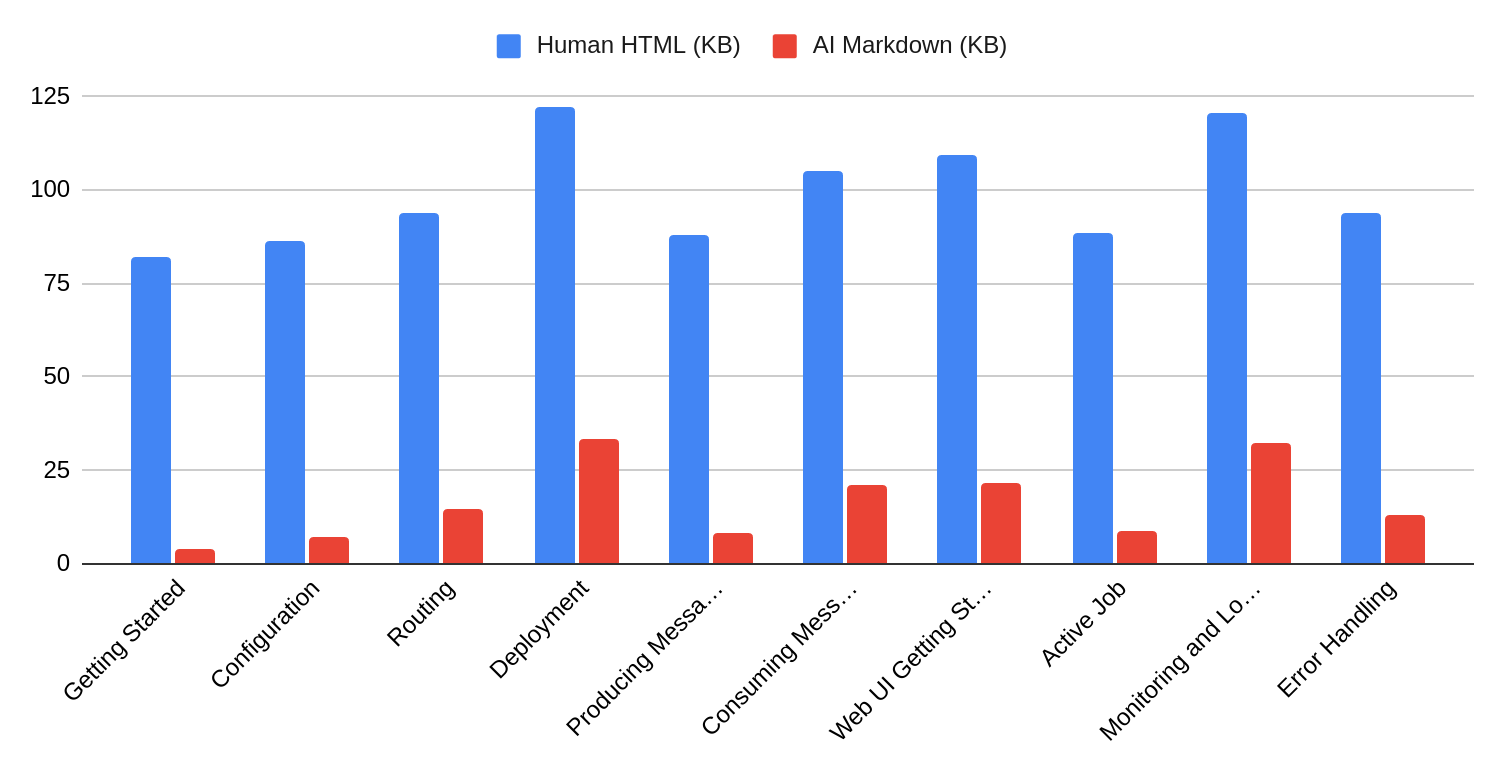
This tool transforms your markdown documentation to eliminate 85-95% of the noise compared to the HTML version, letting AI assistants focus on the actual content. I have extracted it from the Karafka framework's documentation build system, where it has served thousands of developers in production for months.
Real metrics from Karafka documentation:
| Page | HTML | Markdown | Reduction |
|---|---|---|---|
| Getting Started | 82.0 KB | 4.1 KB | 95% (20x) |
| Monitoring | 156 KB | 6.2 KB | 96% (25x) |
| Configuration | 94.3 KB | 3.8 KB | 96% (25x) |
Average: 93% fewer tokens, 20-36x smaller files
Before and After Example
Before transformation (98 tokens):
---
title: Getting Started
description: Learn how to get started
tags: [tutorial, beginner]
updated: 2024-01-15
---
[](https://ci.example.com)
[](LICENSE)
# Getting Started
> **Note**: Requires Ruby 3.0+
Welcome to our framework! Let's get you up and running...After transformation (18 tokens, 81% reduction):
# Getting Started
Welcome to our framework! Let's get you up and running.Why This Matters
Cleaner documentation means AI assistants spend less time processing noise and more time understanding your actual content. This translates to lower costs per query, fewer hallucinations as shown in the HtmlRAG study, and much faster response times.
How It Works
llm-docs-builder applies several transformations to your markdown documentation to make it RAG-friendly, then generates an llms.txt index that helps AI agents discover and navigate your content efficiently. Below are examples of these transformations in action.
1. Hierarchical Context Preservation
When documents are chunked for RAG, context loss leads to hallucinations. Consider:
# Configuration
## Consumer Settings
### auto_offset_reset
Controls how consumers handle missing offsets...Chunked independently, ### auto_offset_reset loses all parent context. llm-docs-builder preserves hierarchy:
### Configuration / Consumer Settings / auto_offset_reset
Controls how consumers handle missing offsets...Now the chunk is self-contained even when retrieved in isolation.
2. Semantic Noise Removal
- Strips YAML/TOML frontmatter.
- Removes HTML comments and build badges.
- Expands relative links to absolute URLs.
- Normalizes whitespace while preserving code blocks.
- Preserves code syntax highlighting markers.
3. Enhanced llms.txt Generation
This feature creates llms.txt index files - the emerging standard for AI-discoverable documentation, adopted by Anthropic, Cursor, Pinecone, LangChain, and 200+ projects.
Generated llms.txt includes token counts and timestamps and provides AI-readable documentation for your:
# Llms.txt
## Documentation
- [Getting Started](https://myproject.io/docs/getting-started.md): 1,024 tokens, updated 2024-03-15
- [API Reference](https://myproject.io/docs/api-reference.md): 5,420 tokens, updated 2024-03-18
- [Configuration Guide](https://myproject.io/docs/configuration.md): 2,134 tokens, updated 2024-03-12
Total documentation: 8,578 tokens across 3 core pagesAI agents can prioritize which documents to fetch based on token budgets, their needs and freshness.
Getting Started
Installation
docker pull mensfeld/llm-docs-builder:latest
alias llm-docs-builder='docker run -v $(pwd):/workspace mensfeld/llm-docs-builder'Transform Your Documentation
llm-docs-builder bulk-transform --docs ./docs --base-url https://myproject.ioThis single command can reduce your RAG system's token usage by 85-95%.
Generate an llms.txt Index
llm-docs-builder generate --docs ./docsMeasure Your Savings
llm-docs-builder compare --url https://karafka.io/docs/Getting-Started/Example output:
============================================================
Context Window Comparison
============================================================
Human version: 82.0 KB
AI version: 4.1 KB
Reduction: 77.9 KB (95%)
Factor: 20.1x smaller
============================================================Configuration
Create llm-docs-builder.yml:
docs: ./docs
base_url: https://myproject.io
# Optimization options
convert_urls: true
remove_comments: true
remove_badges: true
remove_frontmatter: true
normalize_whitespace: true
# RAG enhancements
normalize_headings: true
include_metadata: true
include_tokens: true
excludes:
- "**/internal/**"Serving Optimized Docs to AI Crawlers
Configure your web server to automatically serve markdown to LLM crawlers while continuing to serve HTML to human visitors. Detect AI user agents (ChatGPT-User, GPTBot, anthropic-ai, claude-web, PerplexityBot, meta-externalagent) and serve .md files instead of .html.
Implement this feature to automatically detect AI agents and serve them raw markdown, as shown in the following example:
Apache (.htaccess):
SetEnvIf User-Agent "(?i)(openai|anthropic|claude|gpt|chatgpt|perplexity)" IS_LLM_BOT
RewriteCond %{ENV:IS_LLM_BOT} !^$
RewriteCond %{REQUEST_FILENAME}.md -f
RewriteRule ^(.*)$ $1.md [L]Nginx:
map $http_user_agent $is_llm_bot {
default 0;
"~*(?i)(openai|anthropic|claude|gpt|chatgpt|perplexity)" 1;
}
location ~ ^/docs/ {
if ($is_llm_bot) {
try_files $uri.md $uri $uri/ =404;
}
}Benefits:
- Zero disruption to human users
- Automatic cost savings on every AI query
- No separate documentation sites needed
Why Markdown for RAG Systems
Tokenization efficiency matters for both cost and performance. The following table shows a simple heading comparison:
| Format | Example | Token Count |
|---|---|---|
| HTML | <h2>Section Title</h2> |
7-8 tokens |
| Markdown | ## Section Title |
3-4 tokens |
HTML requires opening and closing tags for every element (2x overhead), special characters (<, >, ) consume multiple tokens each, and attributes add 2-3 tokens per occurrence. Markdown uses single characters for formatting (**, *, -, |) that often tokenize to single tokens, requires no closing tags, and maintains semantic structure without attribute bloat.
Format efficiency comparison:
- Plain text: 96% reduction vs raw HTML
- Cleaned HTML (CSS/JS removed): 94% reduction
- Markdown: 90% reduction
While cleaned HTML can match Markdown's efficiency, the preprocessing required is complex and error-prone. Markdown provides the optimal balance: simple to generate, efficient to tokenize, and preserves semantic structure naturally. For RAG systems that chunk and retrieve documents independently, a clear hierarchy of Markdown ensures that each chunk remains interpretable without its surrounding context.
When NOT to Use This
My llm-docs-builder will not be of great use when:
- Your docs rely heavily on visual diagrams that cannot be described in Markdown.
- You are already serving pure Markdown without HTML noise.
- Your documentation is primarily an API reference with minimal prose (consider OpenAPI/Swagger instead).
Next Steps
Your documentation is already being consumed by LLMs. The question is whether you're serving optimized content or forcing them to parse megabytes of HTML boilerplate.
- Install llm-docs-builder via Docker.
- Run
compareon your existing docs to measure potential savings. - Configure
llm-docs-builder.ymlfor your project. - Run
bulk-transformto generate optimized versions. - Use server configuration to serve markdown to AI crawlers.
Every query you optimize saves money and improves the quality of AI-assisted development with your framework.
llm-docs-builder is open source under the MIT License. It is extracted from production code powering the Karafka framework documentation.