Introduction
Managing frontend assets in gems serving Web UI can be tricky. Why? Because while you want assets to expire across versions, you don't want them fetched repeatedly, slowing things down. This challenge popped up when working on the Karafka Web UI, which runs on the Roda framework.
In this article, I'll explore how I addressed this, ensuring smooth updates without compromising speed by elevating Roda and its plugins ecosystem.
Brief on the Roda web framework.
Roda is a versatile web framework for the Ruby programming language. Crafted by Jeremy Evans, Roda is renowned for its exceptional quality, security, and performance.
One of the standout aspects of Roda is its low supply chain footprint. In an era where software dependencies can sprawl into the tens or hundreds, introducing potential vulnerabilities and complexity, Roda's minimalistic approach is a breath of fresh air. This is essential, especially when building gems, as you want to ensure your third-party dependencies are as minimal as possible. Ultimately, your gems supply chain becomes someone else's software dependency. The less complex your dependency tree is, the lower the chances are that things will go out of hand for anyone using your software.
For those eyeing the development of Rack-compatible Web UIs, Roda emerges as an impeccable choice. Its adaptability means it can be effortlessly used either in tandem with Ruby on Rails or independently, making it a mountable engine for a myriad of projects.
Roda isn't just a web framework; it's a commitment to lightweight, efficient, and quality web development.
Assets Management for UI providing Gems
In web development, assets like JavaScript and CSS enhance user experience. These should be forever cached to boost page load speeds. But when you don't control the end application, how do you prevent outdated assets, which can lead to glitches or even break the UI?
When embedding UI inside a gem, the solution must be twofold: it should auto-detect and serve updated assets post-gem update and remain uncomplicated. I could not afford the hassle of complex asset pipelines or mechanisms that could lead to integration issues. I aimed for optimal performance with assets that auto-refresh on gem updates without added complexity.
There are several reasons why you want your assets to be cached:
-
Enhanced Performance: With assets cached, subsequent page loads are faster since the browser retrieves files locally rather than making multiple server requests. This leads to a rapid and seamless user experience.
-
Reduced Server Load: Forever-caching alleviates the strain on servers. By minimizing the number of repetitive requests for the same assets, servers can efficiently manage traffic and respond to unique queries faster. This can be especially important when it is Rack/Roda serving the assets and not a proxy server like Nginx.
-
Bandwidth Savings: For UIs with significant traffic or big asset files, serving assets repeatedly can consume a vast amount of bandwidth. Caching assets cuts down on this data transmission, leading to substantial savings.
Roda Routing and the public Plugin
Basic Setup
Serving static files with Roda is as easy as it can be. The only things you need to do is to active the public plugin, provide it with the assets root directory and set appropriate route:
plugin(
:public,
root: Karafka::Web.gem_root.join('lib/karafka/web/ui/public')
)
r.route do
# Make GET /assets/.* look for files in Karafka Web gem lib/karafka/web/ui/public directory
r.on(:assets) do
r.public
end
endIn my case, since assets are part of the gem, the root lies within the gem itself.
This, however, does not solve our problem by itself. While we can serve assets, their location is constant, and they are being fetched during each request.
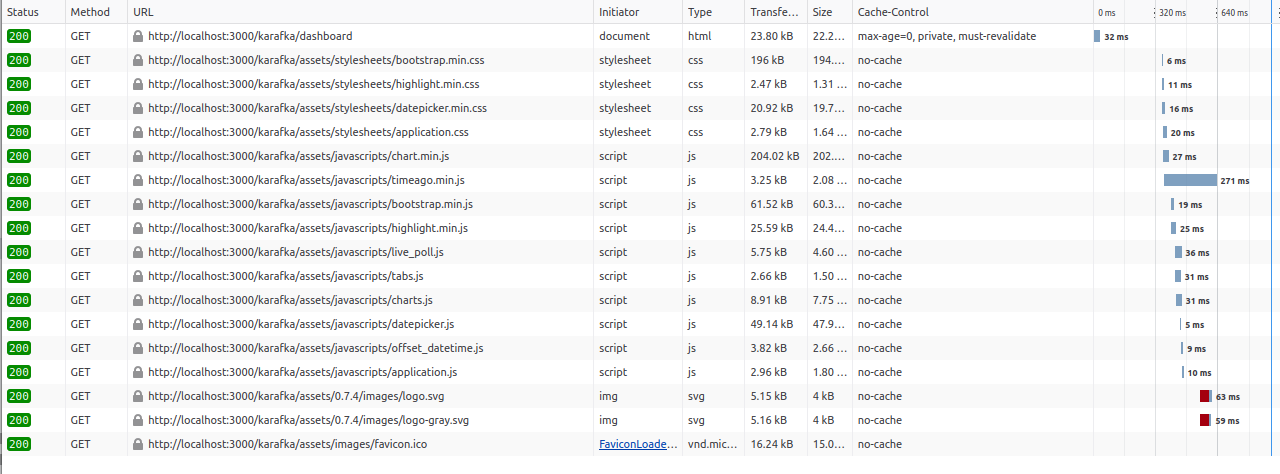
Assets are being fetched with each request, and while the response is 304, not modified, the assets are still being demanded each time.
Status: 304 Not Modified
Version: HTTP/1.1
Transferred: 3.16 kB (2.08 kB size)
Referrer Policy: strict-origin-when-cross-origin
DNS Resolution: SystemCache-Control Forever
Our assets work, but they are not cached. To improve this, we will use the Cache-Control HTTP header.
Cache-Control is an HTTP header directive web developers use to dictate how browsers should cache web content. It specifies what can be cached, by whom, and for how long, optimizing web performance by reducing unnecessary server requests.
Roda allows you to configure this directive inside the same public plugin as follows:
plugin(
:public,
root: Karafka::Web.gem_root.join('lib/karafka/web/ui/public'),
headers: { 'Cache-Control' => 'max-age=31536000, immutable' }
)31536000 is approximately one year, and we indicate that the resources fetched are immutable. Now, consecutive requests look much better, and since our assets will not change until gem updates, we're left only with the "on update" invalidation.
Notice how all the assets are loaded in 0ms. That's because the browser knows it can use its local versions without revalidating them with the server.
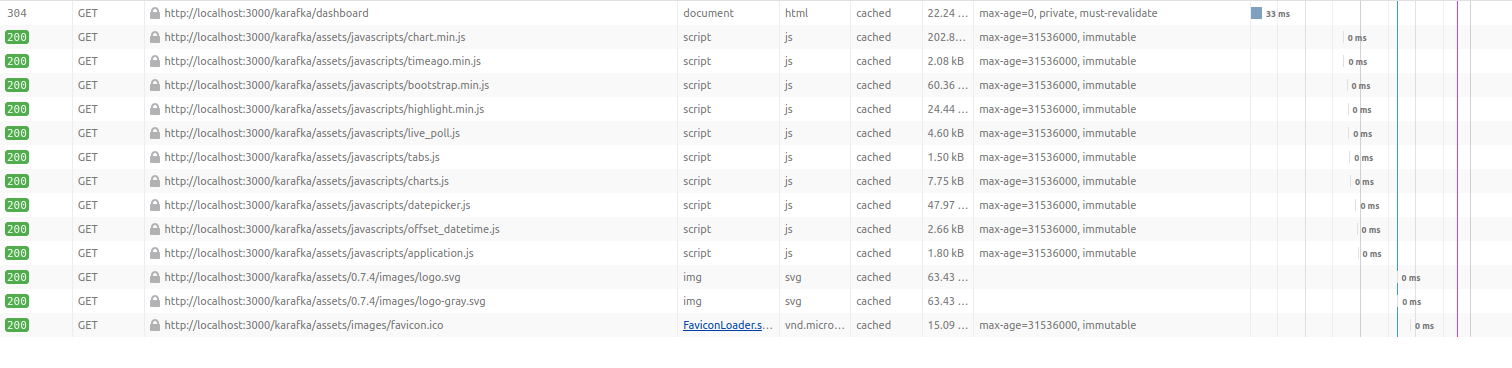
Per Gem Version Assets with via Roda Routing
One last challenge we must address is asset invalidation during gem updates. My initial solution was to use checksum fingerprinting for assets. Yet, this would demand a release pipeline with pre-build steps for asset processing. I aimed to keep the process straightforward, so I hesitated on this approach.
Another approach was placing assets within a version-specific directory and renaming it to align with the gem version before release. While this still needed a pipeline, it was a simpler one. Assets URLs would then look like:
<link href="/karafka/assets/VERSION/stylesheets/bootstrap.min.css" rel="stylesheet">Then, I realized I didn't need to namespace assets or implement pipelines. Using Roda routing, I could deliver version-specific assets as shown but source them from a single directory!
Not only that, but it also required only three lines of code:
route do |r|
r.on 'assets', Karafka::Web::VERSION do
r.public
end
endFantastic! Now, with every new release of Karafka Web UI, all assets are automatically invalidated upon user upgrades as their URL changes. No manual actions, reminders, or management are needed – Roda handles it seamlessly!

Summary
When integrating a Web UI into your OSS gems, you're presented with challenging choices. While the flexibility and extensibility of frameworks like Rails are tempting, you may not want to limit yourself solely to Rails or introduce such a heavy framework. Unlike Mike Perham, who crafted an entire HTTP stack for Sidekiq, I opted for Roda. It offers everything one could desire in situations like mine. Roda is powerful, extremely adaptable, and elegant with minimal dependencies. It ensures swift, stable, and predictable progress.
Whenever I encounter a Web UI OSS-related challenge, I often find that Jeremy has already anticipated a similar scenario, and my solution often boils down to just a few added lines of code.
I highly recommend exploring Roda if you haven't already. Dive into the official Roda documentation or take a look at the Karafka Web UI's Roda application.